阻塞赋值与非阻塞赋值的再分析
在Verilog HDL设计中,经常会遇到阻塞赋值与非阻塞赋值,这是学习逻辑设计时最基础的知识点。设计者经常会在书中看到一些建议:什么时候该用阻塞赋值,什么情况下使用非阻塞赋值。可是,如果仅仅按照这样的设计推荐来进行设计的话,经常会碰到一头雾水的情况。本文就对阻塞赋值和非阻塞赋值进行详细的讨论,深入分析这两种赋值语句的区别。
“阻塞”与“非阻塞”疑问的由来,主要体现在always或initial语句中。
在任何书上都会碰到的分析为:阻塞赋值“=”与非阻塞赋值“<=”的区别在于:非阻塞赋值语句右端表达式计算完后并不立即赋值给左端,而是马上启动下一条语句继续执行;而阻塞赋值语句在每个右端表达式计算完后立即赋值给左端变量。
1、语义分析
首先来看阻塞赋值与非阻塞赋值在语义上的含义。
always @ (posedge clk)
begin
q1 = d;
q2 = q1;
q3 = q2;
end在所有的语句执行完以后,该always语句等待clk的上升沿到来,从而再次触发begin...end语句块。
其次来分析非阻塞赋值。
非阻塞赋值,就是指当前语句的执行互惠阻塞下一语句的执行。下面为非阻塞赋值的语句结构:
sum <= A+B
上式中左边的A+B称之为右式(RHS)计算事件,SUM称之为左式(LHS)更新事件。无论左式还是右式,都有可能即是变量,又是表达式。
非阻塞赋值的RHS计算属于活跃事件,需要优先执行,因此首先执行A+B,然后产生一个更新事件,把计算结果更新到SUM中,将“更新事件”放入事件队列中,但不会马上执行,即使这个更新事件属于当前时间的事件。因为非阻塞赋值的更新事件优先级较低,需要执行完begin...end中其他当前时间的活跃事件和非活跃事件之后,才会执行当前时间的非阻塞赋值更新事件。
如果在非赋值阻塞的右式中有延时参数,例如:
sum = #5 A+B
那么A+B完成以后,会将sum的更新事件放入事件队列中,并在当前仿真时间内5ns后才会执行该事件。
下面来分析非阻塞赋值代码的执行过程:
always @ (posedge clk)
begin
q1 <= d;
q2 <= q1;
q3 <= q2;
end这是always语句块执行完成,并且等待下一个clk上升沿到来。
通过上面的分析可知,现在事件队列中有三个更新事件需要完成,那么什么时候执行这三个等待事件呢?只有当当前时间内的所有活跃事件和非活跃事件执行完成之后,才开始执行这些非阻塞赋值的更新事件。这样就相当于将d,q1,q2的值同时赋值给了q1,q2,q3.
2、综合后的电路
对于下面的HDL描述:
always @ (posedge clk or negedge rstn)
begin
if(!rstn)
A <= 0;
else
A <= B;
end这是一个标准的DFF描述,综合完成后是一个标准的D触发器。那么同理对于上文所描述的非阻塞赋值,有如下的电路图:

对于阻塞赋值,实现的电路结果如下图
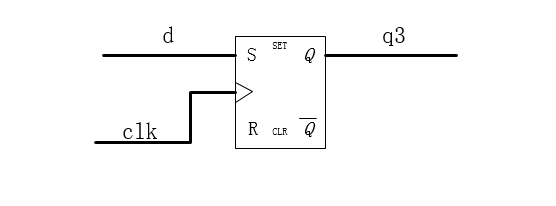
其中的q1和q2,在逻辑代码综合的时候,就被优化掉了。
那么,为什么好多书上会不根据实际的需求,来推荐设计者按照一些固定的建议来设计呢?这主要是为了设计者减少代码的错误,为初学者在开发时省去很多麻烦。但这并不是很好的设计。因为按照实际电路的要求,在always语句中,有时也需要采用阻塞赋值语句。最常见的是两段式或者三段式状态机。还有其他的一些情况,可以通过下面的案例来说明阻塞赋值与非阻塞赋值的区别。
3、案例分析
本例选自《设计与验证 verilog HDL》
这里有一个数组:Data[0]、Data[1]、Data[2]和Data[3]。它们都是4bit的数据。我们需要在它们当中找到一个最小的数据,同时将该数据的索引输出到LidMin中,这个算法有点类似于“冒泡排序”的过程。而且需要在一个时钟周期内完成。例如,如果这4个数据中Data[2]最小,那么LidMin的值为2.
reg [1:0] LidMin;
reg [3:0] Data [0:3];
always @ (posedge clk or negedge rstn)
begin
if(!rstn)
LidMin <= 0;
else
begin
if(Data[0] <= Data[LidMin])
LidMin <= 0;
if(Data[1] <= Data[LidMin])
LidMin <= 1;
if(Data[2] <= Data[LidMin])
LidMin <= 2;
if(Data[3] <= Data[LidMin])
LidMin <= 3;
end
end原意是首先将LidMin设置为一个初始值,然后将Data[0] ~ Data[3]与Data[LidMin]进行比较,每比较一个数,就将较小的索引暂存在LidMin中,然后再进行下一次比较。当4组数据比较完成之后,最小的数据所以就会保留在LidMin中。
在上面的程序中使用了非阻塞赋值,结果发现,仿真波形不是所需要的功能,如下图示,图中Data[0] ~ Data[3]分别为11、3、10、12,LidMin的初始值为0。LidMin的计算结果应该为1,但仿真波形却为2.

那么为什么会得到这样的结果呢?
在时钟上升沿到来后,且rstn信号无效开始执行以下4个语句,假设只是LidMin是0,Data[0] ~ Data[3]分别为11、3、10、12:
if(Data[0] <= Data[LidMin])
LidMin <= 0;
if(Data[1] <= Data[LidMin])
LidMin <= 1;
if(Data[2] <= Data[LidMin])
LidMin <= 2;
if(Data[3] <= Data[LidMin])
LidMin <= 3;第一句的if为真,因此执行LidMin <= 0,而这时候,LidMin并没有立刻被赋值,而是调度到时间队列中等待执行,这是非阻塞赋值的特点。
第二句的if为真,因此执行LidMin <= 1,这时LidMin也没有立刻被赋值为1,而是调度到事件队列中等待执行,当前的LidMin还是0,没有发生变化。
第三句的if为真,因此执行LidMin <= 2,将更新事件调度到时间队列中等待执行,当前LidMin还是0.
第四句的if为假,因此跳过LidMin <= 3不执行,这是跳出always语句,等待下一个时钟上升沿。
在以上的always语句执行完成后,在当前时间下,事件队列中3个被调度的非阻塞更新事件开始执行,他们分别将LidMin更新为0、1和2.
按照verilog语言的规范,这3个更新事件属于同一时间内的事件,它们之间的执行顺序随机,这就产生了不确定性。一般在实现的时候是根据它们被调度的先后顺序执行的。事件队列就像一个存放事件的FIFO,它是分层事件队列的一部分,如图所示:

这三个更新事件在同一时刻被一一执行,而真正起作用的是最后一个更新事件,因此在防身的时候得到的最终结果是LidMin为2.
然而想要的结果是,在每个if语句判断并执行完成以后,LidMin先暂存这个中间值,再进行下一次比较,也就是说在进行下一次比较值钱,这个LidMin必须被更新,而这一点也正是阻塞赋值的特点,因此将代码做如下更改:
always @ (posedge clk or negedge rstn)
begin
if(!rstn)
LidMin <= 0;
else
begin
if(Data[0] <= Data[LidMin])
LidMin = 0;
if(Data[1] <= Data[LidMin])
LidMin = 1;
if(Data[2] <= Data[LidMin])
LidMin = 2;
if(Data[3] <= Data[LidMin])
LidMin = 3;
end
end仿真结果如下图
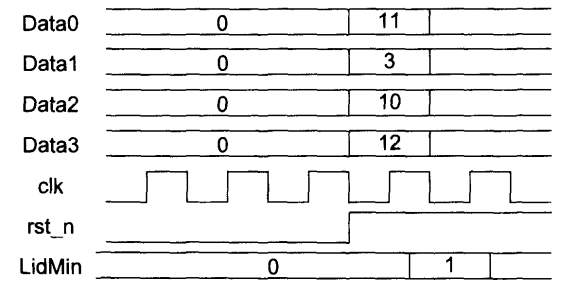
在代码执行过程中,第二句的if为真,执行LidMin = 1,根据阻塞赋值的特点LidMin被立刻赋值为1.在执行第三句if的时候,if(Data[2] <= Data[LidMin])为假,直接跳过LidMin = 2不执行,同样也跳过LidMin = 3不执行。LidMin最终赋值为1。这正是想要的结果。
另外,为了使代码看起来更加简洁,使用for语句修改:
always @( posedge clk or negedge rstn)
begin
integer i;
if (!rst n )
LidMin <= 0
else
begin
for (i = 0;i <= 3; i = i + 1 )
begin
if ( Data[i] <= Data[LidMin] )
Li dMin = i;
end
end
end