用estimator构建一个简单的神经网络
estimator最主要的就两个部分
input_fn
model_fn
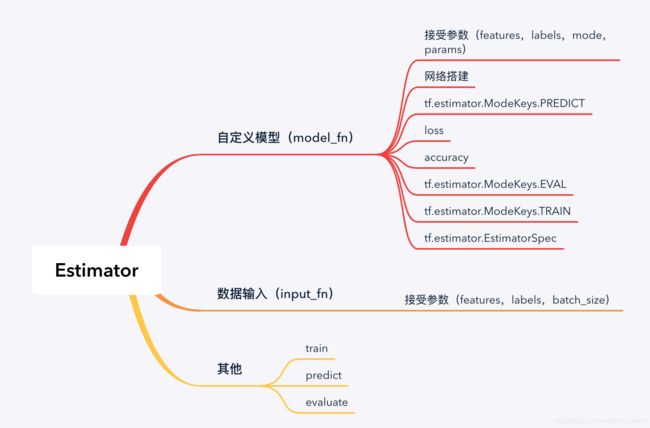
模型可以自定义
输入需要转成字典
import os
import pandas as pd
import tensorflow as tf
FUTURES = ['SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth', 'Species']
SPECIES = ['Setosa', 'Versicolor', 'Virginica']
##加载数据
dir_path = "data"
train_path = os.path.join(dir_path, 'iris_training.csv')
test_path = os.path.join(dir_path, 'iris_test.csv')
train = pd.read_csv(train_path, names=FUTURES, header=0)
train_x, train_y = train, train.pop('Species')
test = pd.read_csv(test_path, names=FUTURES, header=0)
test_x, test_y = test, test.pop('Species')
def train_input_fn(features, labels, batch_size):
"""An input function for training"""
# Convert the inputs to a Dataset.
dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))
# Shuffle, repeat, and batch the examples.
dataset = dataset.shuffle(1000).repeat().batch(batch_size)
# Return the dataset.
return dataset
def eval_input_fn(features, labels, batch_size):
"""An input function for evaluation or prediction"""
features=dict(features)
if labels is None:
# No labels, use only features.
inputs = features
else:
inputs = (features, labels)
# Convert the inputs to a Dataset.
dataset = tf.data.Dataset.from_tensor_slices(inputs)
# Batch the examples
assert batch_size is not None, "batch_size must not be None"
dataset = dataset.batch(batch_size)
# Return the dataset.
return dataset
##构建我们自定义的模型
def my_model(features, labels, mode, params):
"""DNN with three hidden layers and learning_rate=0.1."""
# Create three fully connected layers.
net = tf.feature_column.input_layer(features, params['feature_columns'])
for units in params['hidden_units']:
net = tf.layers.dense(net, units=units, activation=tf.nn.relu)
# Compute logits (1 per class).
logits = tf.layers.dense(net, params['n_classes'], activation=None)
# Compute predictions.
predicted_classes = tf.argmax(logits, 1)
if mode == tf.estimator.ModeKeys.PREDICT:
predictions = {
'class_ids': predicted_classes[:, tf.newaxis],
'probabilities': tf.nn.softmax(logits),
'logits': logits,
}
return tf.estimator.EstimatorSpec(mode, predictions=predictions)
# Compute loss.
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
# Compute evaluation metrics.
accuracy = tf.metrics.accuracy(labels=labels,
predictions=predicted_classes,
name='acc_op')
metrics = {'accuracy': accuracy}
tf.summary.scalar('accuracy', accuracy[1])
if mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(
mode, loss=loss, eval_metric_ops=metrics)
# Create training op.
assert mode == tf.estimator.ModeKeys.TRAIN
optimizer = tf.train.AdagradOptimizer(learning_rate=0.1)
train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op)
def main(argv):
# Feature columns describe how to use the input.
my_feature_columns = []
for key in train_x.keys():
my_feature_columns.append(tf.feature_column.numeric_column(key=key))
# Build 2 hidden layer DNN with 10, 10 units respectively.
classifier = tf.estimator.Estimator(
model_fn=my_model,
params={
'feature_columns': my_feature_columns,
# Two hidden layers of 10 nodes each.
'hidden_units': [10, 10],
# The model must choose between 3 classes.
'n_classes': 3,
})
# Train the Model.
classifier.train(
input_fn=lambda:train_input_fn(train_x, train_y, 20),
steps=10)
# Evaluate the model.
eval_result = classifier.evaluate(
input_fn=lambda:eval_input_fn(test_x, test_y, 20))
print('\nTest set accuracy: {accuracy:0.3f}\n'.format(**eval_result))
# Generate predictions from the model
expected = ['Setosa', 'Versicolor', 'Virginica']
predict_x = {
'SepalLength': [5.1, 5.9, 6.9],
'SepalWidth': [3.3, 3.0, 3.1],
'PetalLength': [1.7, 4.2, 5.4],
'PetalWidth': [0.5, 1.5, 2.1],
}
predictions = classifier.predict(
input_fn=lambda:eval_input_fn(predict_x,
labels=None,
batch_size=10))
for pred_dict, expec in zip(predictions, expected):
template = ('\nPrediction is "{}" ({:.1f}%), expected "{}"')
class_id = pred_dict['class_ids'][0]
probability = pred_dict['probabilities'][class_id]
print(template.format(SPECIES[class_id],
100 * probability, expec))
if __name__ == '__main__':
tf.logging.set_verbosity(tf.logging.INFO)
tf.app.run(main)