对PyramidBox的理解
首先介绍一下PyramidBox,这是百度研发的人脸检测深度学习算法,感觉BAT里,百度在算法方面还是非常有实力的。根据官方数据,今年三月份这个盒子在世界最权威的人脸检测公开评测集 WIDER FACE 的「Easy」、「Medium」和「Hard」三项评测子集中均荣膺榜首,刷新业内最好成绩。《PyramidBox: A Context-assisted Single Shot Face Detector》——环境辅助的单步人脸检测器,文章很新,今年三月份发的。这里提供一下论文链接:https://arxiv.org/abs/1803.07737?context=cs以及demo链接:https://github.com/EricZgw/PyramidBox
首先解释一下什么是single-shot。这里有single-shot(单步) 和multi-shot(多步),有single-scale(单尺度)和multi-scale(多尺度)。图1a图多步单尺度检测,b图单步多尺度检测,c图单步单尺度检测。Scale的single/multi对应是否是同一特征层检测出的结果。Shot的single/multi对应是否是多输入。蓝色层视为Input,multi-shot将同一输入进行缩放,缩放为原来的1/2、1/4等,single-shot对输入不作处理。
 图1
图1
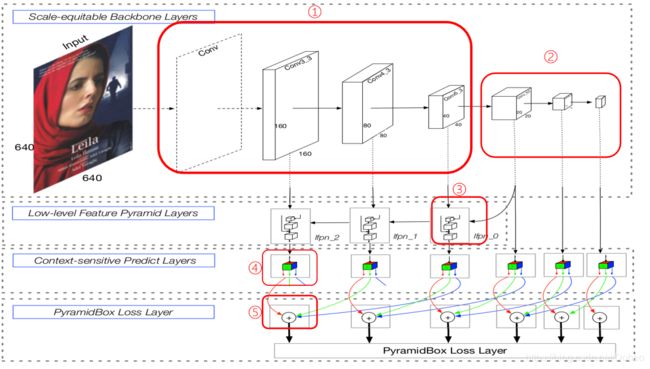 图2
图2
PyramidBox的网络结构如图2。希望在这里简单介绍一下它的网络结构、环境辅助的预测模块、文章创新成分PyramidAnchor以及联合的训练方法。
网络结构先看图2的虚框conv。这里不得不提VGG16网络。在介绍VGG网络前,介绍卷积神经网络的一些基本概念。
(1)卷积是什么?
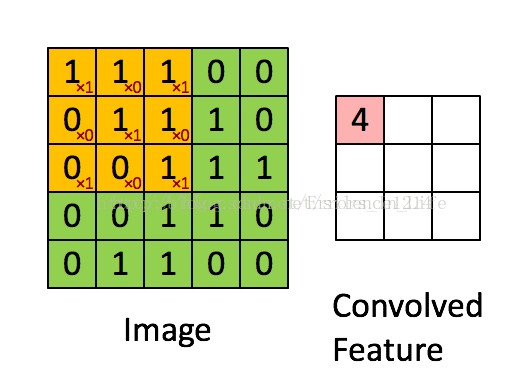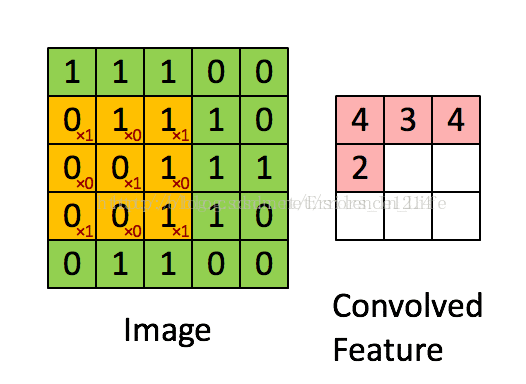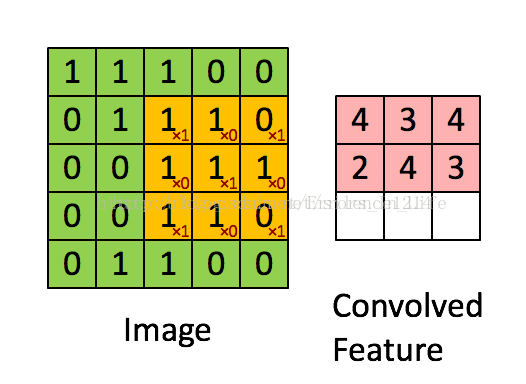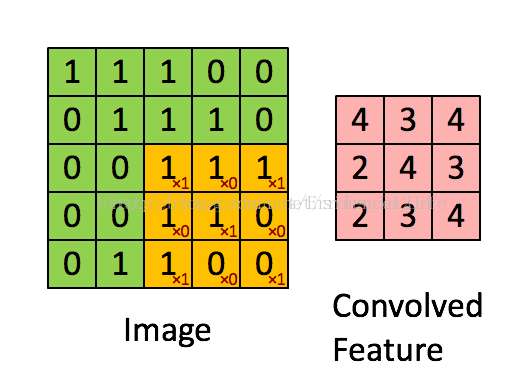 图3
图3
橙色框(3x3)为卷积核,它在绿色图上一格格移动(所以这里步长为1),橙色框相当于对应绿色框内值的系数,对应相乘再相加就能得到卷积值(对应粉色框内的一个值)。这样一轮过后我们发现image变小了,从5x5变成了3x3。
(2)什么是池化?
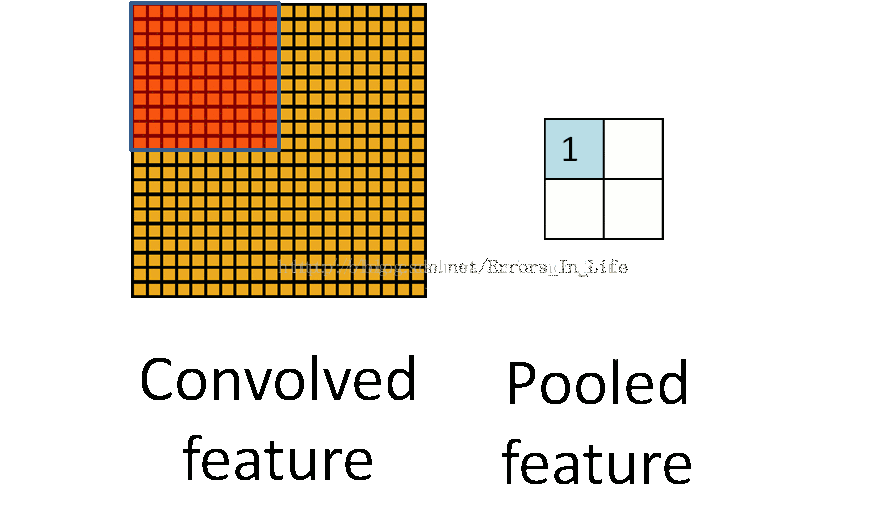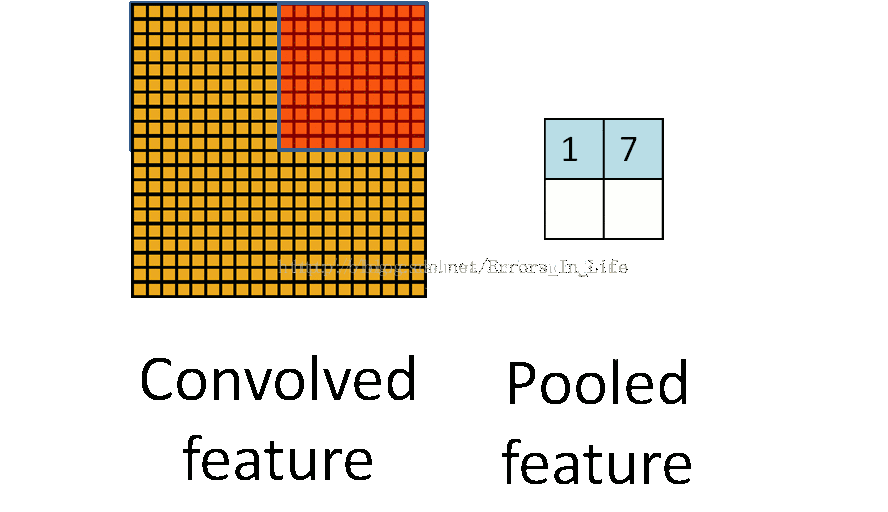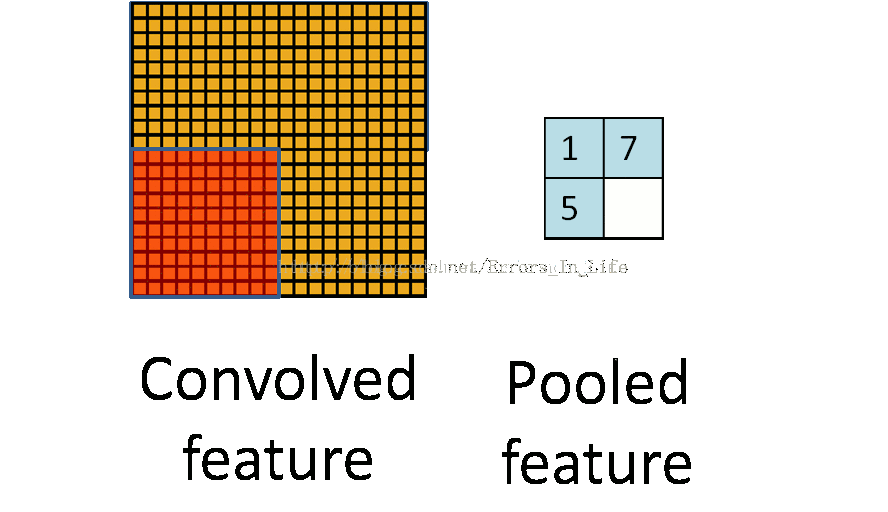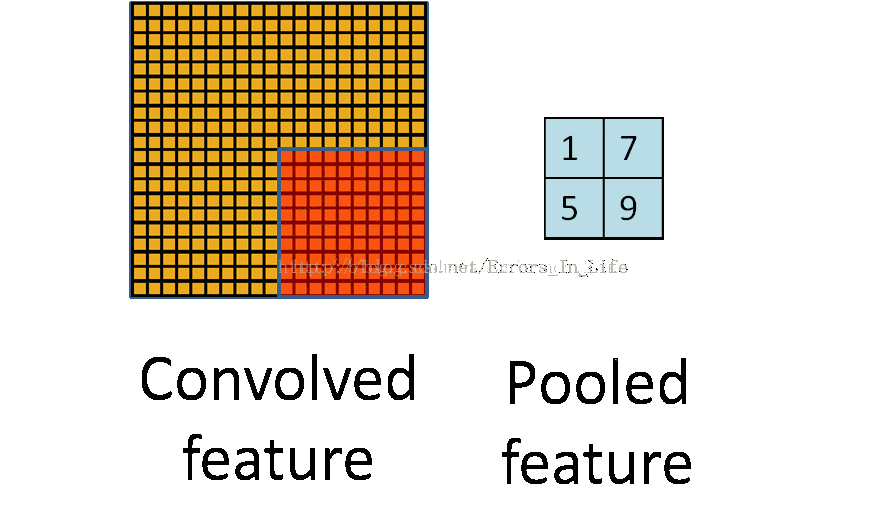 图4
图4
和前面一样,池化也是三个矩阵间的运算。它的目的是直观得将输入层变小。不过这时核的移动间没有重合,没有与各自系数相乘并相加的操作,我觉得是一种比较特别的“卷积”吧。那Pooled feature值怎么得来的呢?有好几种方法,一种是直接取红色框里最大值称做max pooling,用不同框里的最大值组成pooled feature层。如图5。
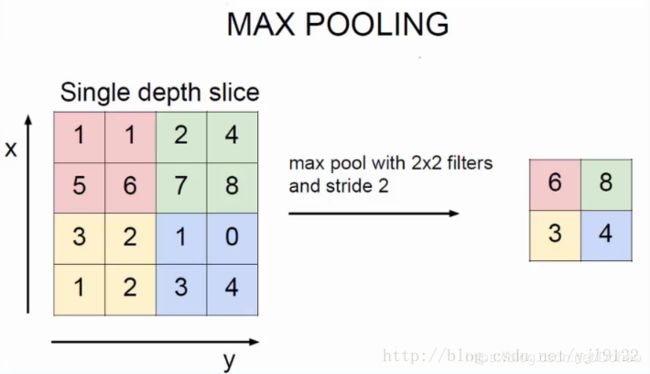 图5
图5
(3)什么是步长?
步长就是卷积核每次移动的距离。在图示里,它每次移动多少格,步长就是多少。我们可以发现,步长越大,输出的结果面积越小。
(4)什么是卷积核?
就是图3中橙色框,有时候我们要提取的特征非常多和广,需要用更多的不同的橙色框来扫,所以能得到不同的特征层(粉色层)。这里我们知道,特征层的个数就是卷积核的个数。
(5)什么是Padding?
padding中文就是填充的意思,顾名思义在图3中我们由5x5的输入得到3x3输出,如果我们要输入输出的大小不变,就可以在输入层外边加一圈“0”。这样5x5变成7x7,用一样的3x3卷积核,以步长为1的方式卷积,就能得到5x5的输出了。如图6。
 图6
图6
具备了这些概念,回到VGG网络。16表示层数(图7中所有的黑色层和蓝色层,也即图8中的所有conv层和fc层)。
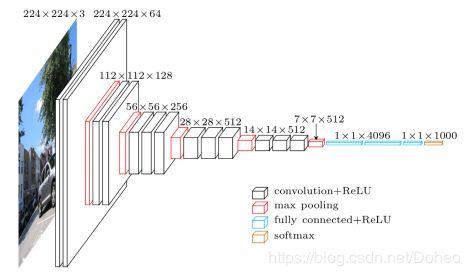 图7
图7
 图8
图8
我们拿第一个黑色层(也就是VGG16中的第一层里的第一小层,即conv1_1)来剖析。我们有了一个224x224的彩色图片,因为色彩有RGB三个值,故有三个通道(R通道、G通道、B通道)。
 图9
图9
每个(黄色的)卷积核在绿色长方体中移动,分别对应27个数和卷积核上的系数分别相乘,再相加,利用padding技术另输出的大小依然为224x224.至此我们利用一个卷积核输出了224x224x1的卷积层(即一层)。同理我们用64个不同的卷积核做相同处理,能得到64个224x224x1的卷积层,堆叠起来就是224x224x64。
那图7里的红色层(也即图8里的pool层)是什么,看起来它的作用是将前一阶段得到的卷积层的尺寸减半(长宽各为原来一半)。看名字知道这是个池化层,拿第一个池化层剖析,我们能得到conv1_2的结果是224x224x64。(以后有时间补充con1_2层做了什么)用步长为2的2x2核(看作一个2x2大小的二维面)移动在每个维度上,最终得到112x112x64。如图10。
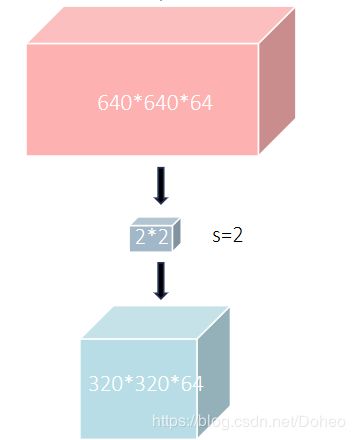 图10
图10
图2网络的①框部分就明了了。进入框②部分。这个部分第一个层是个全连接层。看名字conv_fc7,论文中介绍这一层是VGG16中的fc6和fc7层转换来的。后面两个又是两个卷积层让网络变得更深了。
这里介绍一下全连接层。即图7的蓝色层(也即图8的fc层),PyramidBox中并没有全部引用VGG16的网络结构,它有点像集各家所长,把各个已知网络的特长集为一体(像使用了与 ![]() 完全相同的主干网络,包括基础卷积层和额外卷积层;将 VGG16 中的 fc6 层和 fc7 层做了转化;在基于anchor机制的网络上进行改造的PyramidAnchor;以及后面提到的由max-out改进得到的max-in-out,由FPN改进得到LFPN,用 DSSD 中的残差预测模块替换了 SSH 中的环境模块的卷积层等等)这里先引申介绍全连接层的作用。
完全相同的主干网络,包括基础卷积层和额外卷积层;将 VGG16 中的 fc6 层和 fc7 层做了转化;在基于anchor机制的网络上进行改造的PyramidAnchor;以及后面提到的由max-out改进得到的max-in-out,由FPN改进得到LFPN,用 DSSD 中的残差预测模块替换了 SSH 中的环境模块的卷积层等等)这里先引申介绍全连接层的作用。
拿VGG16的fc4096举例:经过卷积,ReLU后得到3x3x5的输出,如何变成1x4096形式呢?ReLU是一种激活函数,就是将卷积结果(这里假设为x)在成为下一层的卷积层的值之前经过一个函数:max(0,x),x若小于等于0,结果为0;x若大于0,则为x。又跑偏了...重新回到全连接层。
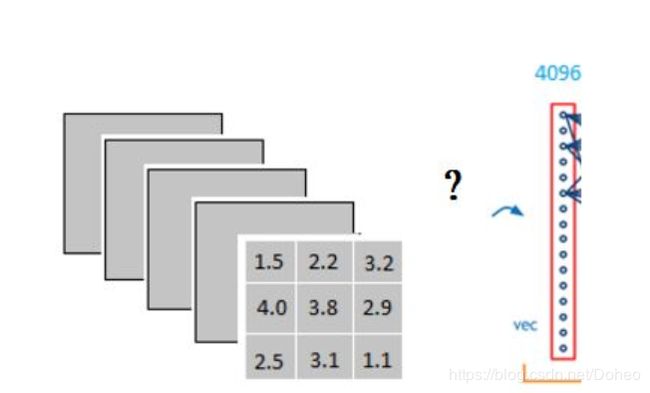 图11
图11
如图11我们是如何将3x3x5的卷积变成1x1x4096的呢?
 图12
图12
从图12我们可以看出,用一个3x3x5的卷积核做卷积,将结果求和就是一个fully connected layer 的一个神经元的输出,这个输出就是一个值。因为我们有4096个神经元。我们实际就是用一个3x3x5x4096的卷积层去卷积激活函数的输出。
它把特征表示整合到一起,输出为一个值。
这样做的目的就是大大减少特征位置对分类带来的影响。为什么这么说?
举个例子:
 图13
图13
从图13我们可以看出,猫在不同的位置,输出的feature值相同,但是位置不同。因为目标检测对于系统来说,特征值相同,但是特征值位置不同,那分类结果也可能不一样。这时全连接层filter的作用就相当于喵在哪我不管,我只要喵,于是我让filter去把这个喵找到,实际就是把feature map 整合成一个值,这个值大,有喵,这个值小,那就可能没喵。和这个喵在哪关系不大了,鲁棒性有大大增强。因为空间结构特性被忽略了,所以全连接层不适合用于在方位上找Pattern的任务,比如segmentation。
全连接层中一层的一个神经元就可以看成一个多项式,我们用许多神经元去拟合数据分布,但是只用一层fully connected layer 有时候没法解决非线性问题,而如果有两层或以上fully connected layer就可以很好地解决非线性问题了。我们都知道,全连接层之前的作用是提取特征,全理解层的作用是分类,我们现在的任务是去区别一图片是不是猫。
 图14
图14
假设这个神经网络模型已经训练完了,全连接层已经知道怎么检测一只猫,即它已经掌握了猫的特征。
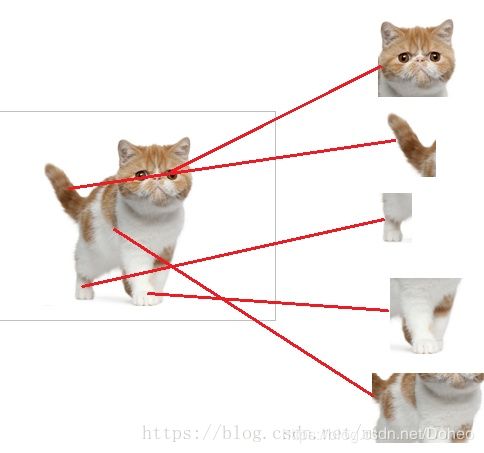 图15
图15
当我们得到(图15)以上特征——猫头、猫尾、猫腿等,我就可以判断这个东东是猫了。全连接层的作用主要就是实现分类。
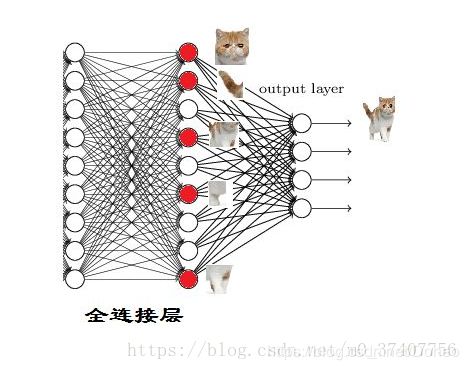 图16
图16
从图16,我们可以看出红色的神经元表示这个特征被找到了(激活了)。同一层的其他神经元,要么猫的特征不明显,要么没找到。当我们把这些找到的特征组合在一起,发现最符合要求的是猫。ok,我认为这是猫了。那我们又是怎么认得这是猫头,这是猫尾的呢?一样的道理。就是把猫头的这么些子特征找到,比如眼睛啊,耳朵啊。如图17。
 图17
图17
当我们找到这些特征,神经元就被激活了(图18红色圆圈)这细节特征又是怎么来的?就是从前面的卷积层,下采样层来的。
 图18
图18
可以看出全连接层参数特多——图里密密麻麻的线。(可占整个网络参数80%左右)
全连接层对模型影响参数就是三个:
1.全接解层的总层数(长度)
2.单个全连接层的神经元数(宽度)
3.激活函数
顺利进入第③个部分。这里是个LFPN。先介绍一下FPN(Feature Pyramid Networks)。FPN采用特征金字塔做目标检测的网络,PyramidBox涉及的论文很大程度(网络结构,设计上)都与之相同。这里提供论文《feature pyramid networks for object detection》链接:https://arxiv.org/abs/1612.03144
如图19所示。FPN(图19d)是single-shot,特征抽取的过程像金字塔一样,低层的感受野小,特征抽取度小,高层感受野大,特征抽取度大。在此基础上,FPN从最高层开始,将特征层往下融合,并在各个融合层上分别predict。
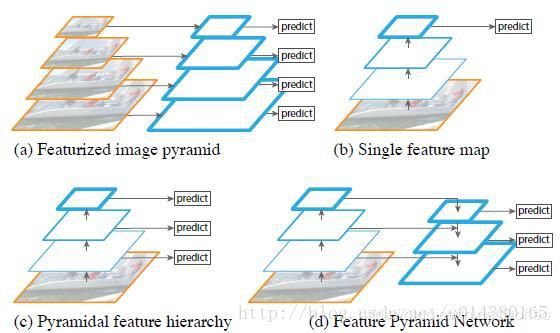 图19
图19
问题是如何从上往下融合特征层。图19里可以看到。因为相邻特征层长宽差两倍,融合大概是先把上一层的特征层两倍上采样(理解为放大两倍),再将下一层用1x1卷积核卷积(目的是升维,因为相邻两层的维度或者说通道数也不一样,下层的维度比较低),在大小和维度均一致后再相加进行融合。具体操作如图20。
 图20
图20
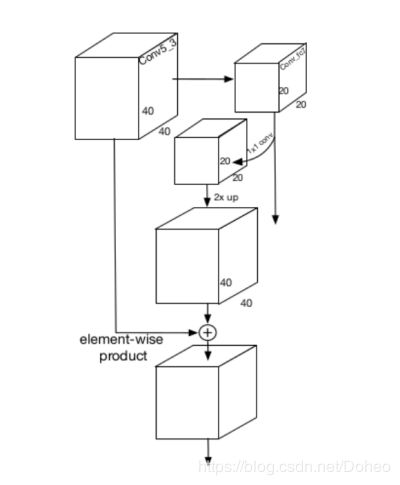 图21
图21
这里延伸出来的问题是1x1卷积核是怎么进行升维或者降维的。1x1conv我认为这里省略了维度,如果输入的通道是n,那么卷积核就是1x1xn,将相同位置不同通道乘上系数后相加,得到一个层。如图22所示,输入为4x4x3,用2个1x1x3的核就能得到4x4x2的结果从而实现降维。同理用4个1x1x3的核得到4x4x4的结果从而实现升维。结果的维度和核的个数相同。
 图22
图22
那2x up(即两倍上采样)是什么操作?(有时间补充,占个坑)
那么为什么PyramidBox不和FPN一样从最高层开始往下融合?图2示它从中间层开始往下融合。这里先介绍一下感受野。
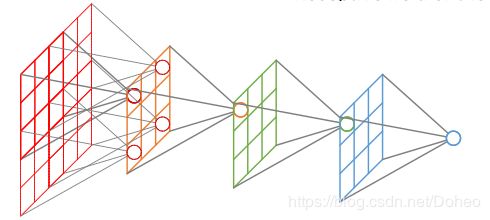 图23
图23
图23上橘色层(从左往右第二层)上的每个单位是红色层部分图像的收集,这个单位它看不到红色层其他地方,感受野是最小的,最高层(从左往右第五层)这个蓝点相当于把整张图片的信息都收入囊中了,它观察者着整张图。我们总结出金字塔式的特征层,越往上感受野越大。至于为什么要从中间开始融合特征层,举个例子:大家知道麦田怪圈是占地面积很大的一种神秘现象吧,世界未解之谜之一......(扯远了)。我如果站在麦田里(相当于处在低层),站在怪圈中,我只能看见一个线段,图案太大了我瞧不出来是个什么东西。
如果我有一个朋友他有20米高(相当于处在中层),他能看到的比我能看到的多,他能告诉我这个图案是个西瓜。我们两个合作就既能看清细节又能知道环境的语义,这是融合的目的。那如果我朋友他有2000米高,或者他坐在飞机上(相当于处在高层),他从飞机上往下看,他看到麦田也只是个绿点了。我俩互通有无也不知道是画的是啥。网络是一样的道理,它从中部开始向下融合,中部的感受野大概是最高层的一半,就比较合适。
放在人脸的检测上同理,不是所有的高层级特征都一定对检测较小的人脸有帮助。首先,较小的,模糊的,被遮挡的人脸与较大的,清晰的,完整的人脸有不同的纹理特征。所以,直接用高层级特征来提升检测器在较小人脸上的表现是过于简单粗暴的。第二,高层级特征是从缺少环境的区域中提取出来的,并且可能引入噪声信息。比如,在 PyramidBox 的主干层里,层级最高的两层 conv7_2 和 conv6_2 的感受野分别是 724 和 468,而训练图像的输入尺寸是 640。这意味着上面两层只包含大尺度的人脸而且缺少环境特征,所以可能对检测中等和小尺寸的人脸没什么帮助。
所以到这里,我们用LFPN,得到了加强版的特征层。
图2的框③也解决啦,来到④⑤,这里准备放在一起讲,还是上图。
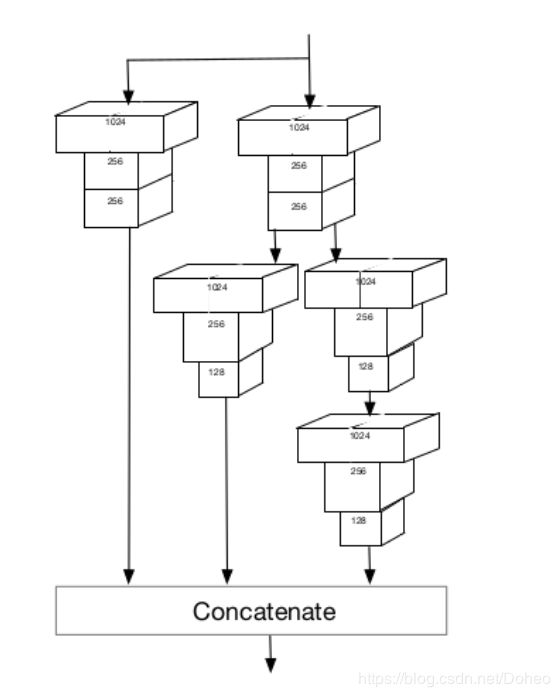 图24
图24
预测分支网络应该充分利用结合了的特征即加强版的特征层。我们采用环境敏感预测模块 (CPM) 用一个广而深的网络来吸收目标人脸周围的环境信息。那么它如何实现“广”和“深”的呢?广而深的网络为什么可以帮助吸收目标人脸周围的环境信息?如图24所示,这是一个CPM(Context-sensitive Prediction Module)。它由 Inception-ResNet 得到启发,其中Inception使网络变得更宽(广),Resnet使网络变得更深。我们当然可以同时借鉴既获得网络变宽的收益又获得网络变深的收益。那么ResNet 是如何让网络变得更深的呢?Inception又是如何让网络变得更宽(广)的呢?
先说Resnet为什么会出现呢?是因为非常深的网络在增加更多层时会表现得更差。可是网络不是越深越好吗?我们说深度学习,就是因为有“深度”才能学习得好——理论上来说网络越深表达能力越强,能处理的训练数据也更多。举个例子,我们输入一张吴彦祖的脸,第一轮,我们提取出比如说30度的折角,斜45度的线条等等。第二轮,我们得到有折角和线条组成的眼睛,嘴巴,鼻子等。就这么不断抽取,抽象,最后这些特征就组成了一个吴彦祖,是不是很神奇hhh。
假设我们已经构建了一个 n 层网络,并且实现了一定准确度。那么一个 n+1 层网络至少也应该能够实现同样的准确度——只要简单复制前面 n 层,再在最后一层增加一层恒等映射就可以了。类似地,n+2、n+3 和 n+4 层的网络都可以继续增加恒等映射,然后实现同样的准确度。但是在实际情况下,这些更深度的网络基本上都会表现得更差。网络太深,因为权重线性相乘,很容易导致梯度爆炸或梯度消失。
什么是梯度爆炸和梯度消失呢?
假设存在一个这样的前馈网络:

其表达式为
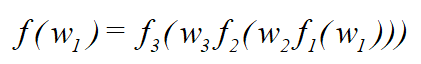
对![]() 求偏导,根据链式求导法则,得到
求偏导,根据链式求导法则,得到

通常,若使用的激活函数为sigmoid函数,

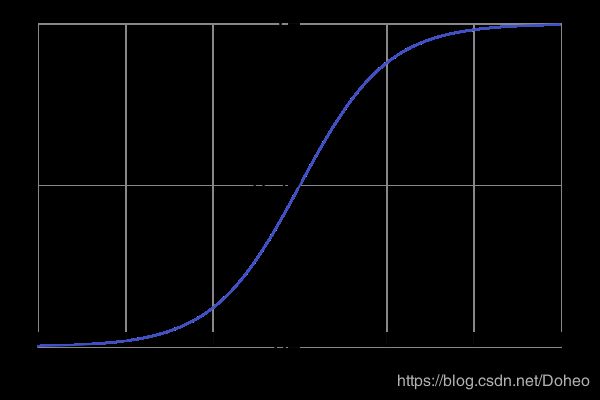 图25
图25
它有这么几个特性,第一定义域![]()
![]()
![]() ,第二值域(0,1),第三函数在定义域内为连续光滑函数,对其求导
,第二值域(0,1),第三函数在定义域内为连续光滑函数,对其求导

 图26
图26
有人可能会问,为什么需要激活函数呢?
我们知道激活函数用在一层权值与输入相乘(还有偏置)之后,那么这个输出仅仅是一个简单的线性函数——![]() ,一个一级多项式,如图27。
,一个一级多项式,如图27。
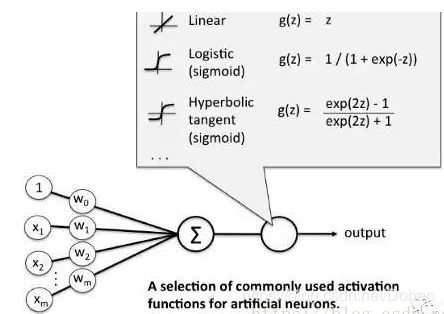 图27
图27
这样过于简单了,它只能学习和计算线性函数,但待解决的问题远比这些复杂,例如图像、视频、音频、语音等。运用激活函数,将线性函数转化为非线性函数,以便使网络更加强大,增加它的能力,使它可以学习复杂的事物。
当我们用sigmoid激活函数时,看图25、26时,得知这一层的输出![]() ,不管数值为多少,经过一趟sigmoid函数,他就像喝了爱丽丝梦游奇遇记的药水,被扔到迷你世界去了——得到0-1之间的小数。并且标准化初始的
,不管数值为多少,经过一趟sigmoid函数,他就像喝了爱丽丝梦游奇遇记的药水,被扔到迷你世界去了——得到0-1之间的小数。并且标准化初始的![]() 也为小数,我们知道小数和小数相乘,结果会更小。这么连乘之后,梯度会变得非常非常小,也就是梯度消失。
也为小数,我们知道小数和小数相乘,结果会更小。这么连乘之后,梯度会变得非常非常小,也就是梯度消失。
梯度爆炸同理,假设标准化初始的![]() 大于1,激活函数的输出也大于1,那么连乘之后,梯度会很大,导致梯度爆炸。
大于1,激活函数的输出也大于1,那么连乘之后,梯度会很大,导致梯度爆炸。
感觉一个是学不动了,一个是学疯了……
强行介绍完梯度爆炸和梯度消失。ResNet是如何解决深度太深带来的问题的呢?
ResNet的作者将这些问题归结成了一个单一的假设:直接映射是难以学习的。而且他们提出了一种修正方法:不再学习从 x 到 H(x) 的基本映射关系,而是学习这两者之间的差异,也就是「残差(residual)」。然后,为了计算 H(x),我们只需要将这个残差加到输入上即可。
假设残差为 F(x)=H(x)-x,那么现在我们的网络不会直接学习 H(x) 了,而是学习 F(x)+x。
这就带来了你可能已经见过的著名 ResNet(残差网络)模块,如图28:
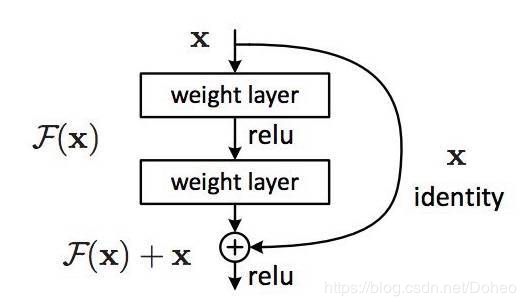 图28
图28
ResNet 的每一个「模块(block)」都由一系列层和一个「捷径(shortcut)」连接组成,这个「捷径」将该模块的输入和输出连接到了一起。然后在元素层面上执行「加法(add)」运算,如果输入和输出的大小不同,那就可以使用零填充或投射(通过 1×1 卷积)来得到匹配的大小。
回到我们的思想实验,这能大大简化我们对恒等层的构建。直觉上就能知道,比起从头开始学习一个恒等变换,学会使 F(x) 为 0 并使输出仍为 x 要容易得多。一般来说,ResNet 会给层一个「参考」点 x,以 x 为基础开始学习。这一想法在实践中的效果好得让人吃惊。
那Inception是如何使网络变得更宽的呢?我们知道不同类型的层会提取不同种类的信息。5×5 卷积核的输出中的信息就和 3×3 卷积核的输出不同,那怎么知道到底是5x5的卷积结果好还是3x3的卷积结果好,Inception 模块是个非常认真不怕累的好模块,它就都试了一遍,如图26它并行计算同一输入映射上的多个不同变换,并将它们的结果都连接到单一一个输出。换句话说,对于每一个层,Inception 都会执行 5×5 卷积变换、3×3 卷积变换和最大池化。然后该模型的下一层会决定是否以及怎样使用各个信息。大家是不是看出来问题在哪了呢?计算时间和成本都是很贵的,性能boss说你这样“烧钱”我养不起你。
 图29
图29
为了“生存”下去,Inception使用 1x1 卷积来执行降维。如图30的1x1 convolutions。比如,使用 20 个 1×1 过滤器,一个大小为 64×64×100(具有 100 个特征映射)的输入可以被压缩到 64×64×20。通过减少输入映射的数量,Inception 可以将不同的层变换并行地堆叠到一起。
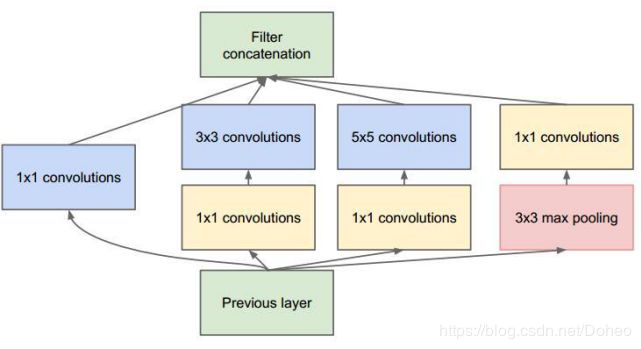 图30
图30
所以用Resnet和Inception从而得到既深又宽(宽指有很多并行操作)的网络。
在论文中,作者说到:受 Inception-ResNet 启发,我们当然可以既获得网络变宽的收益又获得网络变深的收益。我们设计了环境敏感的预测模块 (CPM),见图 2(b)。在这个模块中,我们用 DSSD 中的残差预测模块替换了 SSH 中的环境模块的卷积层。这让我们的 CPM 既具备 DSSD 模块方法的所有优势,又从 SSH 环境模块中保留了丰富的环境信息。
先看一下DSSD中的残差预测模块:
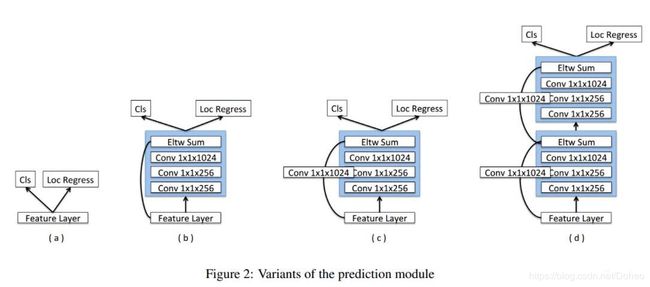 图31
图31
再看一下SSH中的环境预测模块:
 图32
图32
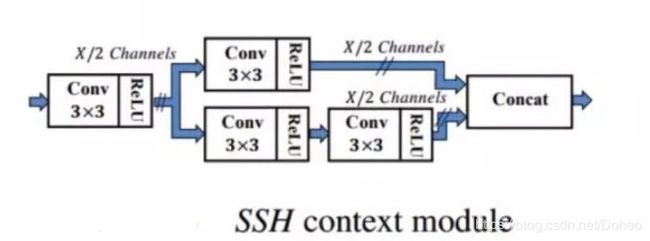 图33
图33
将图32、33画在一起为:
 图34
图34
这已经和图24神似,接下来我们将图34的卷积层替换成残差预测模块:
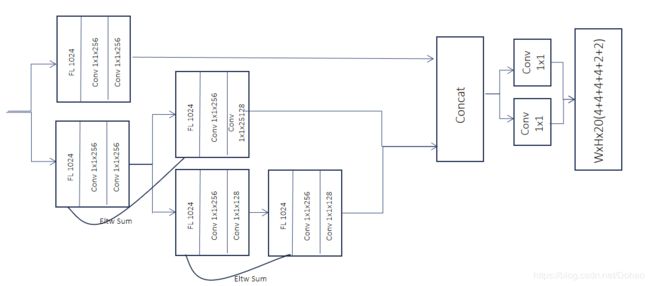 图35
图35
看整个网络的剖析图——图36,其中cpm模块可用图35代入:
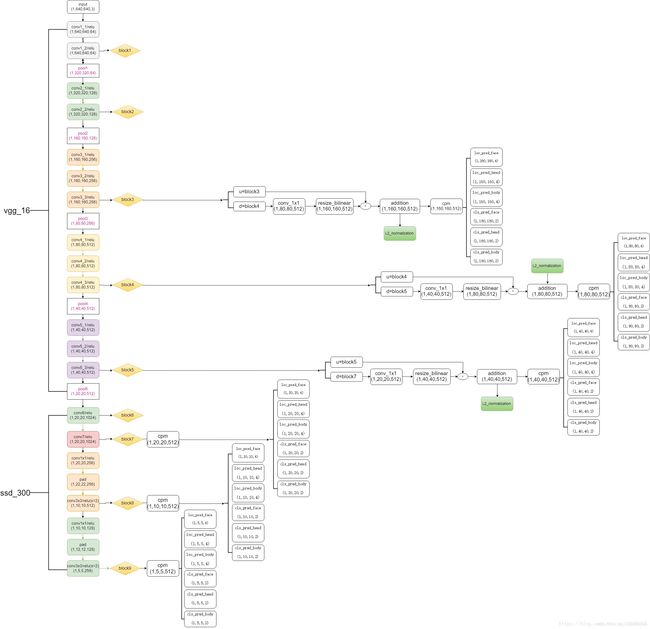 图36
图36
④就到这里,它的输出为![]() ,(l=0,1,...,5),其中
,(l=0,1,...,5),其中 ![]() 是对应的特征尺寸,通道尺寸
是对应的特征尺寸,通道尺寸 ![]() 。这里每个通道的特征分别被用来分类和回归面部,头部和身体。人脸的分类需要 4 (
。这里每个通道的特征分别被用来分类和回归面部,头部和身体。人脸的分类需要 4 (![]() )个通道,其中
)个通道,其中 ![]() 和
和 ![]() 分别是前景和背景的 max-in-out 标签,满足
分别是前景和背景的 max-in-out 标签,满足

此外,头部和身体的分类各需要两个通道,面部、头部和身体的定位各需要 4 个通道。为什么第0层的特征层是1、3的分配,非0层的是3、1的分配呢?
还是用图来说明:图37中我们可以看到在一张640x640图片上所能产生的不同size的anchor的数量,显然尺寸小的anchor占了绝大比例,这也是false positive的主要来源。
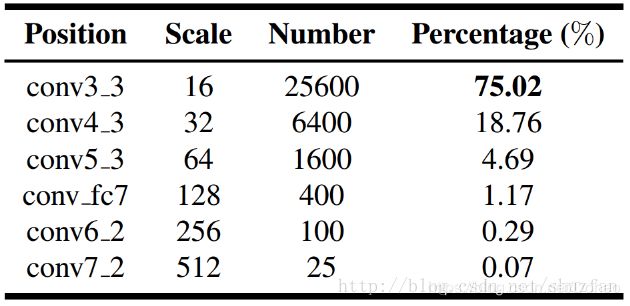 图37
图37
如图38所示,anchor分为positive anchor和negative anchor。Positive anchor指框住了目标或物体的anchor(或者说前景),negative anchor就是内容为背景的anchor。低层anchor数量大,能框住小物体的能力大,但是失败的anchor也比其他层多(因为基数大),所以失败比就越高。
 图38
图38
为了减少小目标所产生的false positive,![]() 采用了图30的方法来加强对小目标的区分,即max-out(注意PyramidBox中为max-in-out):对每个anchor分类的预测都打个分,后面有讲到如何预测。
采用了图30的方法来加强对小目标的区分,即max-out(注意PyramidBox中为max-in-out):对每个anchor分类的预测都打个分,后面有讲到如何预测。
 图39
图39
Max-out就是把许多作为negative anchor 的可能性中最大值挑出来作为最终预测它为negative anchor的打分。Max-in-out就是把positive和negative anchor都做此处理,在正负样本上都使用这个策略。那为什么negative anchor会有不同的打分呢?可以想象成是对anchor谨慎地做了多遍预测,这样它被判断为negative的概率就高了,之前说过false positive在低层很高,这样操作之后能让预测的准确率提升。
在上面我们提到CPM产生的特征层上进行分类和定位的预测。这里不得不先提这篇文章的创新——Pyramid Anchor。不过据我观察,它和传统的anchor其实差不多,只不过它在这名字前加了个Pyramid,有点像Java里的子类和父类的关系吧。子类继承父类,同时继承了父类的方法和属性,但是长江后浪推前浪,子类自己做了些适应具体环境的改变。父anchor是做什么的?PyramidAnchor又做了什么改变呢?
传统anchor的本质就是.......将相同尺寸的输出,往底层倒推得到不同尺寸的输入。图40是anchor三种不同的窗口尺寸——![]() ,
,![]() ,
,![]() 。在每一个尺寸下,都取三种不同的长宽比(1:1,1:2,2:1),这样我们这里得到了9种面积尺寸各不相同的anchor。那我们拿这些小框框做什么呢?框东西!用来框东西!它就像一个渔网在漫漫像素海里捞鱼,而且这渔网还能变大变小,变长变宽。而且特征层的尺寸决定了其上的anchor数量,也就是说特征图上每一个点不是在原始图像上都能反应一块区域码?以这个区域的中心点生成9个同心的不同尺寸形状的anchor。每一个特征层的点都能派生出9个anchor,那么
。在每一个尺寸下,都取三种不同的长宽比(1:1,1:2,2:1),这样我们这里得到了9种面积尺寸各不相同的anchor。那我们拿这些小框框做什么呢?框东西!用来框东西!它就像一个渔网在漫漫像素海里捞鱼,而且这渔网还能变大变小,变长变宽。而且特征层的尺寸决定了其上的anchor数量,也就是说特征图上每一个点不是在原始图像上都能反应一块区域码?以这个区域的中心点生成9个同心的不同尺寸形状的anchor。每一个特征层的点都能派生出9个anchor,那么![]() 的特征层上就能有
的特征层上就能有![]() 个anchor。
个anchor。
 图40
图40
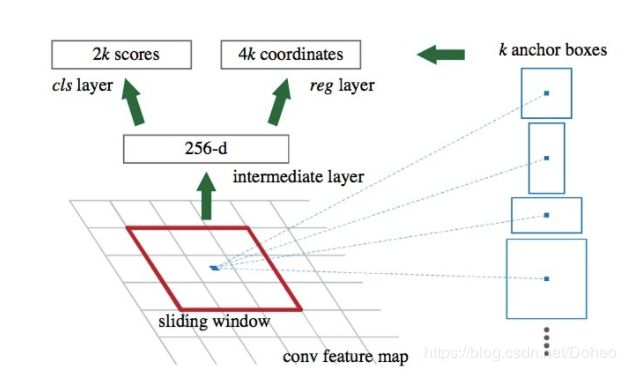 图41
图41
介绍了anchor,再介绍如何基于anchor做分类和定位的预测。图41非常形象地展示了anchor是如何被预测类别和位置的。对每个anchor进行类别上的预测(是前景或背景的概率,并且预测在每个anchor基础上物体的位置,用四个参数来表示。)我们在feature map滑动一个mini-network,这个network输入是3 * 3 * 256,经过3 * 3 * 256 * 256的卷积,得到1 * 1 * 256的低维向量;接下来进行分支:①Classification:经过1 * 1 * 256 * 18的卷积核,得到1 * 1 * 18的feature vector,分别代表9个proposals的是/不是Object的概率(这里有一个疑惑,为什么要生成一对?生成一个是Object的概率不就好了?也许是为了设计方便?);②Regression:经过1 * 1 * 256 * 36的卷积核,得到1 * 1 * 36的feature vector,分别代表9个proposals的(center_x,center_y,w,d)。当然在本文的PyramidBox中并没有9个anchor的设计。
那Pyramid Anchor是什么呢?提醒一句为了省事,PyramidBox里涉及的anchor其实都是Pyramid Anchor。特征层每个单元对应在原图里的中心点,以这个中心点为中心以每层anchor的大小的固定的尺寸能产生1个anchor而不是9个。对每个anchor我们都给他打三个label。对于一个原始图像中在目标区域 ![]() 的目标人脸,考虑
的目标人脸,考虑 ![]() 即第i个特征层的第j个anchor,步长为
即第i个特征层的第j个anchor,步长为 ![]() ,我们定义第 k 个 pyramid anchor 的标签为
,我们定义第 k 个 pyramid anchor 的标签为

![]() 是金字塔anchors的步长 (k = 0, 1, … , K),
是金字塔anchors的步长 (k = 0, 1, … , K),![]() 表示
表示 ![]() 在原始图像中对应的区域,
在原始图像中对应的区域,![]() 表示对应的以步长为
表示对应的以步长为 ![]() 进行下采样的区域。阈值与其他基于 anchor 的检测器相同。在我们的实验中,设置超参数
进行下采样的区域。阈值与其他基于 anchor 的检测器相同。在我们的实验中,设置超参数 ![]() =2,因为相邻的预测模块的步长是 2。此外,设置 threshold = 0.35,K = 2。这样 label0, label1, label2就分别是面部、头部和身体的标签。
=2,因为相邻的预测模块的步长是 2。此外,设置 threshold = 0.35,K = 2。这样 label0, label1, label2就分别是面部、头部和身体的标签。
来到⑤。如图42,这里主要是讲怎么用CPM得到的![]() ,用1x1全连接得到Cls和Reg并生成损失函数。一个人脸将会在 3 个连续的预测模块中产生 3 个目标,分别代表面部自身,以及和它对应的头部和身体。如图43。
,用1x1全连接得到Cls和Reg并生成损失函数。一个人脸将会在 3 个连续的预测模块中产生 3 个目标,分别代表面部自身,以及和它对应的头部和身体。如图43。
 图42
图42
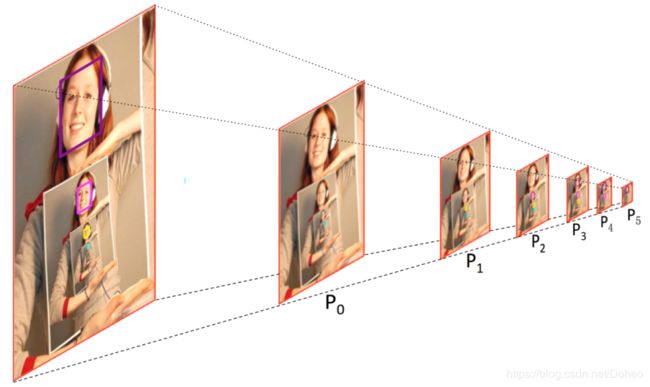 图43
图43

作为对多边框损失的一般化,我们将一张图片的 PyramidBox 损失函数定义为:
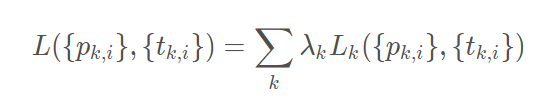
其中第 k 个 pyramid-anchor 损失是

其中 k 是 pyramid-anchors 的编号 (k = 0, 1, 2 分别表示面部、头部和身体),i 是 anchor 的编号,![]() 表示 anchor i 是第 k 个目标 (面部、头部或身体) 的预测概率。ground-truth 标签定义为
表示 anchor i 是第 k 个目标 (面部、头部或身体) 的预测概率。ground-truth 标签定义为

例如,当 k = 0 时,ground-truth 标签等于 Fast R-CNN 中的标签。当 k≥1 时,根据下采样 anchors 和 ground-truth 人脸的匹配决定对应的标签。此外,![]() 是一个 4 维向量,表示预测得到的边框的坐标。
是一个 4 维向量,表示预测得到的边框的坐标。![]() 表示与一个阳性 anchor 相关联的 ground-truth 边框,定义为
表示与一个阳性 anchor 相关联的 ground-truth 边框,定义为

如图44,脸部、头部、身体的ground-truth 边框是这样被标注的。
 图44
图44
是对 Fast R-CNN 的一个自然的泛化。分类损失 ![]() 是有脸和无脸两种类型间的对数损失。回归损失
是有脸和无脸两种类型间的对数损失。回归损失 ![]() 是 Fast R-CNN 中定义的平滑 L1 损失。
是 Fast R-CNN 中定义的平滑 L1 损失。![]() 意味着回归损失只在 anchors 为阳性时被激活。两项损失通过
意味着回归损失只在 anchors 为阳性时被激活。两项损失通过 ![]() ,
,![]() 归一化,
归一化,![]() 和
和 ![]() 是平衡权重。
是平衡权重。
博客目前比较粗糙,后期会精化改善。谢谢浏览!