CAM论文笔记--Learning Deep Features for Discriminative Localization
CAM:Learning Deep Features for Discriminative Localization
背景
论文主要针对图片中不同类别物体定位的弱监督学习问题,提出了基于分类网络的图片识别与定位。
分类网络如VGGnet和Alexnet等基本由卷积操作对图片的特征进行提取,在网络末端使用全连接层进行信息综合和分类。在监督学习中,分类问题需要带类别标签的数据集,定位问题需要带BBox(BoundingBox)标签的数据集,分别计算预测与真值之间的loss并进行优化,达到网络训练的目的。而对于只提供分类标签的数据集,但需要完成分类和定位两个功能的网络训练时,就属于弱监督学习问题。
论文笔记
论文中提出,CNN网络中各卷积核除了提取特征外,其实本身已经具有物体检测功能,即使没有单独对物体的位置检测进行监督学习,而这种能力在使用全连接层进行分类的时候会丧失。通过使用GAP(global average pooling)替代全连接层,可以保持网络定位物体的能力,且相对于全连接网络而言参数更少。论文中提出一种CAM(Class Activation Mapping)方法,可以将CNN在分类时使用的分类依据(图中对应的类别特征)在原图的位置进行可视化,并绘制成热图,以此作为物体定位的依据。
1、全连接层和卷积层对空间信息影响
卷积操作是在空间维度(Spatial Dimension)上进行特征抽提,所以可以保留语义和空间维度上的信息。如图1所示,该图片的分类标签为猫、狗、相机,对于分类为猫的结果而言,卷积之后图片右边内容由于具备更多猫的属性特征,故得到的feature-map激活值更大,而对于分类为狗的结果而言,卷积后图片左边的feature-map激活值更大。故网络在做分类的前向传播过程中,其实已经保留了物体的位置信息。对于全连接层而言,是将得到的feature-map信息进行综合,最后送到分类器中(常用softmax)进行分类,全连接得到的信息主要关注物体的类别特征而不是位置,即使将图片中的狗和猫对换位置,对全连接层后的分类结果也不会有太大影响。

图 1 类别标签为猫、狗、相机的图片
2、全局平均池化层(GAP)和全局最大池化层(GMP)对比
GAP和GMP都是全局池化的方法,也有学者在做弱监督物体定位时采用了这两种方法,而文章之所以选择GAP有以下两个原因:
- GMP希望网络更关注物体的1个discriminaltive part,更关注物体的边缘识别,取最大的部分,而GAP则更希望网络识别物体的整个范围。在求平均值时,GAP可以综合并找到所有discriminaltive part来得到最大激活,对于低激活的区域就会减少特定输出,即GAP相对于GMP来说识别这个物体辨别性区域的损失更小。
- GMP由于只取了区域最大值,所以其他低分的区域对最终分类的得分都不会有影响
通过在ILSVRC数据集上进行验证发现,GMP的分类性能和GAP相当,但GAP的定位能力强于GMP
3、整体思路
CNN网络做分类时之所以丢失了物体的位置信息,是因为网络末端使用了全连接层,通过使用GAP替代全连接层,从而使卷积网络的定位能力能延续到网络的最后一层(全局平均池化的技术不是本论文提出的,论文主要挖掘出GAP可以用于定位区别性区域的特点,即discriminative localization)
4、类激活图(CAM)
保持经典网络(如VGGnet、Alexnet和GoogleNet)的卷积部分,只在输出层前(用于分类的softmax)将全连接层替换为GAP,并将它们作为得出分类的特征。通过这样的连接结构,可以把图片中重要的区域用输出层权重映射回卷积层特征的方式标记出来,这种方法称为类别激活映射或类别激活图。
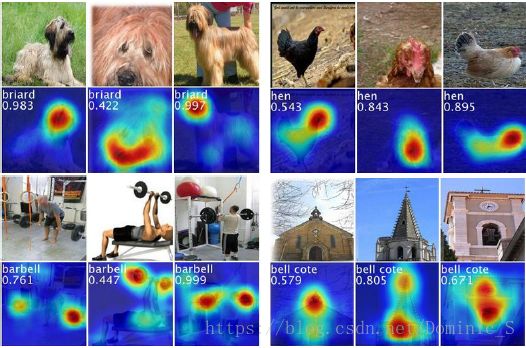
图2 四个分类的CAM图(高亮表示区别性区域)
5、类激活图理论依据
表1 公式参数表
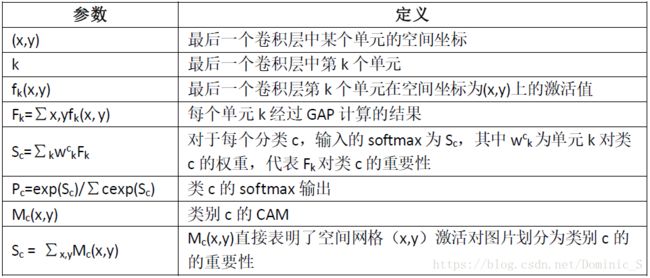
**注:**偏置项bias置为0,因为bias对分类表现基本无影响
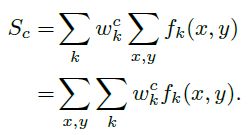
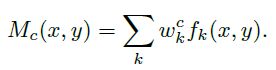
图 3 GAP连接图
图 4 预测的类别分数被映射回先前的卷积层以生成类别激活图(CAM)
如图4所示,GAP操作后输出最后一个卷积层每个单元feature-map的平均值,之后再接一个softmax层用于分类,而该层的所有参数作为权重wck,对前方的GAP得到的feature-map做加权总和得到最后的输出,即CAM输出。此时CAM的输出尺寸和feature-map大小一致,故需要通过上采样方式还原叠加到原图中。
CAM的可视化是通过fk激活值实现的,激活值越大的地方说明该区域越有可能属于对应某个分类,通过改变图像尺寸,将激活图还原成原图大小的图片,即可得到该分类对应在原图的位置,加权越多的区域颜色亮度越大,在通过设置阈值即可画出覆盖该区域的BBox,从而得到物体在图片中的定位边框。
如图5所示,对于同一张图片,不同的分类对应图片中的物体不一样,从CAM还原到原图时高亮的区域也不一样(被激活的区域),且和所属分类相对应,证明了该方法的可行性。
图5 同一图片不同分类对应的热图
6、实验结果
在ILSVRC数据集上,分别使用基于AlexNet、VGGnet和GoogLeNet,将卷积后的全连接层改为GAP得到新的网络进行训练和结果对比
- 对分类性能的影响
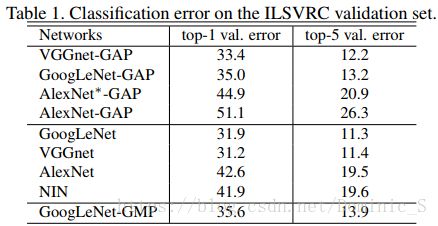
该弱监督的定位方法是基于分类网络的,所以分类网络的性能决定了修改后网络的定位能力。通过实验对比,发现修改后的网络依旧保持了良好的分类性能,只比原网络的准确率降低了1%~2%。不同网络受到的影响不同,其中AlexNet分类性能影响最大(可能是因为AlexNet网络中有三个全连接层,网络提取特征能力较依赖于这些全连接层,直接替换为GAP对网络改变太大),故作者对AlexNet网络在GAP之前新增了两个卷积层进行补偿,得到AlexNet*-GAP,网络的分类性能与AlexNet相差不大。
- 定位性能
实验分别设定CAM最大值的20%的阈值和最大连通分量画BBox,在ILSVRC上测试得到数据,如下表和图6所示,得到了不错的定位效果,且和反向传播的方法对比,此方法得到的准确率更高。
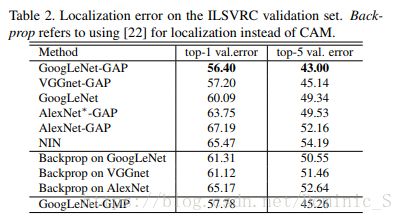
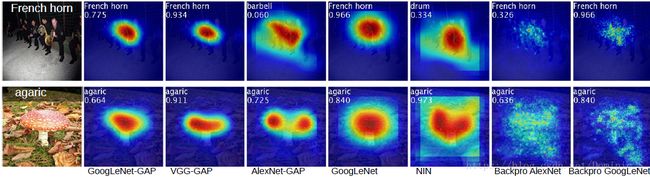
图6 CNN-GAPs的CAM和特定类的反向传播方法
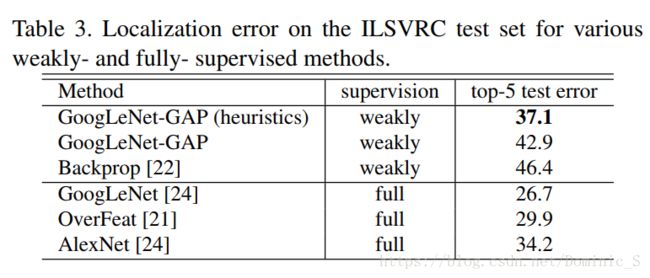
作者也对比了此弱监督学习方法和全监督学习方法的性能,如下表所示,弱监督学习方法得到的定位性能和全监督学习的定位性能还是存在一定差距的,但也可看出,启发式的GoogleNet-GAP得到的top-5错误率(37.1%)和AlexNet的top-5错误率(34.2%)很接近,AlexNet使用的是带有BBox真值标签的训练数据,而GoogleNet-GAP使用的是无任何BBox的训练数据,能达到这样的定位表现已经相当不错了。
总结
文章主要提出了一种基于普通分类卷积神经网络的GAP改良,并提出CAM技术,使得定位任务可以融合进普通的分类任务中。对于只有分类标签而无定位标签的数据集,网络的训练不仅能保持原基础网络的分类性能,还能得到分类物体在原图的定位。其中CAM可以可视化预测类在任何给定图片上的得分,并标出CNN检测到的物体的区别性区域。
从成果上来看,该文章提出了一种弱监督学习定位的可能,并达到了不错的效果。但免去人工标注BBox成本的代价可能就是定位精度的降低,可以发现相对于监督学习来说,此方法的定位性能还是有一定差距,还有更多提升性能的可能。文章中提到定位的性能很大程度上依赖于原网络的分类性能,且对不同的网络在进行改造需要注意对其分类性能的影响。如对AlexNet(3个全连接层)的改造需要新增卷积进行补偿,对GoogleNet的改造需要考虑过多卷积使网络末端得到的feature-map太小而降低分辨率从而影响还原效果的问题等。
CAM的实现需要将网络的全连接层替换为GAP(即卷积特征映射→全局平均池化→softmax层),一定程度上改变了原卷积网络的结构,所以适用性受到一些影响。在CAM的基础上有人也提出了更泛化的版本Grad-CAM,这是一种使用梯度信号组合特征映射的方法,该方法不需要对网络架构进行任何修改,所以基本适用于所有的CNN结构得到网络,具体请见Grad-CAM论文《Visual Explanations from Deep Networks via Gradient-based Localization》。
名词解释
CAM: Class Activation Mapping 类激活图
GMP: Global Max Pooling,全局最大池化
GAP: Global Average Pooling,全局平均池化
BBox: Bounding Box,检测边框
参考文章
《Learning Deep Features for Discriminative Localization》
https://blog.csdn.net/yaoqi_isee/article/details/62214648
https://www.jianshu.com/p/1a207e7ca460
https://www.jianshu.com/p/1d7b5c4ecb93