把Caffe的模型转换为Pytorch模型
系列博客目录:Caffe转Pytorch模型系列教程 概述
目录
- 一、可视化Caffe的网络模型
- 1、在线网站
- 2、本地可视化
- 二、SfSNet的第一部分
- 1、网络名
- 2、输入层
- 3、第一个卷积层conv1
- 4、第一个BN层bn1
- 5、第一个Relu层relu1
- 6、第一部分的完整Pytorch代码
- 二、SfSNet的残差块
- 1、Caffe的Eltwise层
- 2、实现一个“ResidualBlock”
- 三、反卷积层、Concat层、池化层以及全连接层
- 1、反卷积层
- 2、Concat层
- 3、池化层
- 4、全连接层
- 四、总结
本文用的Caffe网络模型文件:SfSNet_deploy.prototxt(右键另存为)。这是一个很牛逼的模型,SfSNet_deploy.prototxt的定义也很长,本文就以它(SfSNet)为例,说明如何把Caffe网络手动转换为Pytorch网络。转换后的Pytorch代码地址:model.py(右键另存为)。
一、可视化Caffe的网络模型
可视化网络模型的好处是可以直观地看到网络模型,对网络模型能先有个大概的了解,再结合.prototxt文件,就能完整无误的把Caffe模型转换为Pytorch模型。在线网站要比本地可视化直观准确得多。在后面的实现过程中,请大家结合结合.prototxt和可视化结果来转换模型,很重要。
1、在线网站
打开网站http://ethereon.github.io/netscope/#/editor之后,把SfSNet_deploy.prototxt的内容粘贴到编辑框里,然后按Shift+Enter,右边的框就会出现网络模型。鼠标移动到右边的方块上时,会显示每层的参数。
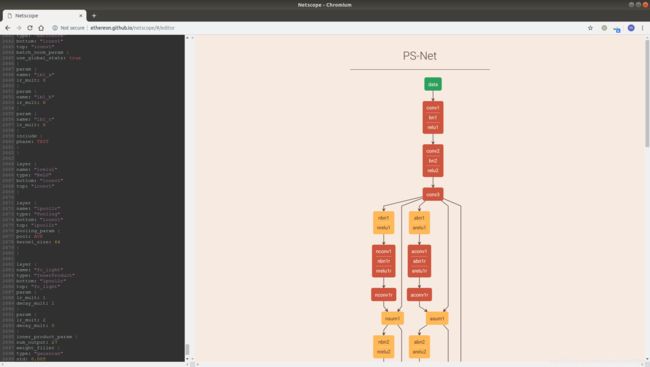
2、本地可视化
请参考:https://www.cnblogs.com/denny402/p/5106764.html
二、SfSNet的第一部分
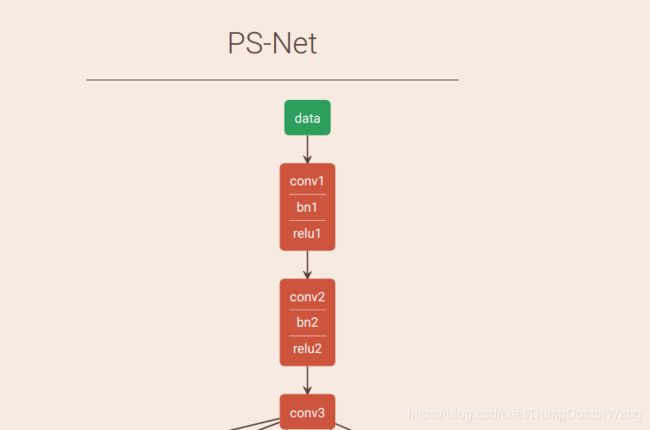
第一部分的网络结构图。Caffe模型中所有的操作都定义为层。
1、网络名
打开SfSNet_deploy.prototxt中,第一行是:
name : "PS-Net"
指定此网络的名称是"PS-Net"。
2、输入层
#data
layer {
name: "data" # 名称,使用Caffe的Python接口时会用到这个。
type: "Input" # 类型,为输入
top: "data" # “顶”,暂时可以理解为数据流向。
input_param { shape: { dim: 1 dim: 3 dim: 128 dim: 128 } }
}
此部分代码的输入层:shape=(1, 3, 128, 128)。 “#”后面是我添加的注释,之后也是如此。
3、第一个卷积层conv1
#C64
layer {
name: "conv1" # 层名
type: "Convolution" # 类型:卷积
bottom: "data" # 数据输入:data
top: "conv1" # 数据输出:conv1
param { # 权重 weight
name : "c1_w" # 权重名
lr_mult: 1 # 权重学习率
decay_mult: 1 # 衰减系数
}
param { # 偏置 bias
name : "c1_b" # 偏置名
lr_mult: 2 # 偏置学习率
decay_mult: 0 # 衰减系数
}
convolution_param { # 卷积层参数
num_output: 64 # 卷积核个数,对应torch.nn.Conv2d的out_channels
kernel_size: 7 # 卷积核大小
stride: 1 # 步长大小
pad: 3 # padding大小
weight_filler { # 权重初始化器参数
type: "xavier" # 权重初始化器类型
}
}
}
以上就是一个卷积层的定义。Pytorch中,卷积层是:
Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
in_channels是输入卷积层的通道数,也就是data层中的“3”;out_channels对应num_output,也就是卷积核的个数:“64”;其他的就是一一对应。在Pytorch中,conv1就定义为:
conv1 = nn.Conv2d(3, 64, 7, 1, 3)
4、第一个BN层bn1
下图是Pytorch中BatchNorm完成的工作,“*”号左边的部分是使用E[x](均值)和Var[x](方差) 归一化x,乘以γ加上β是缩放x和平移x。Caffe中的BatchNorm层只完成了归一化x的工作,缩放和平移由Scale层完成,所以:BatchNorm(Pytorch)= BatchNorm(Caffe)+ Scale(Caffe)。

SfSNet只是使用了BatchNorm层,没有使用Scale层。所以使用Pytorch的BatchNorm层来替换Caffe中的层时,需要把nn.BatchNorm参数affine设置为True,且要把BatchNorm层的weight(相当于γ)设置为全1,bias(相当于β)设置为全0。如果affine=False,weight会被设置为范围在0~1之间的随机数,bias会被设置为0。 至于如何设置,将会在下一篇博客给出,本文只关注如何转换模型。给出bn1的.prototxt定义:
layer {
name: "bn1" # 层名
type: "BatchNorm" # 类型:BatchNorm
bottom: "conv1" # 数据输入:conv1
top: "conv1" # 数据输出:conv1
batch_norm_param {
use_global_stats: false # 训练时为false,不使用保存的E[x]和Var[x]
}
param {
name : "b1_a"
lr_mult: 0
}
param {
name: "b1_b"
lr_mult: 0
}
param {
name: "b1_c"
lr_mult: 0
}
include {
phase: TRAIN # 训练时包含此层
}
}
layer {
name: "bn1"
type: "BatchNorm"
bottom: "conv1"
top: "conv1"
batch_norm_param {
use_global_stats: true # 测试模型是使用保存的E[x]和Var[x]
}
param {
name : "b1_a"
lr_mult: 0
}
param {
name : "b1_b"
lr_mult: 0
}
param {
name: "b1_c"
lr_mult: 0
}
include {
phase: TEST # 测试时包含此层
}
}
bn1的输入和输出均为conv1,所以bn1是“In-Place”操作,把修改完的数据又存回了conv1。 可以发现,bn1层被定义了两次,主要差别是参数use_global_stats和phase。第一个定义是在训练网络(phase:TRAIN)时使用,第二个定义是在测试时(phase:TEST)时使用。Caffe的BatchNorm对应Pytorch中的BatchNorm2d,定义如下:
BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
num_features是特征数量,数值和Conv2d的out_channels相同;eps是ϵ;affine默认为True,不要修改;track_running_stats=True 保持默认。所以bn1的对应的pytorch定义为:
bn1 = nn.BatchNorm2d(64)
64对应out_channels。
5、第一个Relu层relu1
layer {
name: "relu1" # 层名
type: "ReLU" # 类型:relu
bottom: "conv1" # 输入:conv1
top: "conv1" # 输出:conv1
}
这是一个ReLU层的定义,也是一个in-Place层, 输入输出均为conv1。在Pytorch中,可以直接使用:
torch.nn.functional.relu(conv1)
6、第一部分的完整Pytorch代码
上面只是简单的介绍了三个层,实际上只完成了:

这一小部分。但是我不再重复举例说明,而是直接给出第一部分模型的代码,相信读者可以举一反三,完成第一部分模型的转换。请读者先自行完成conv1到conv3的Pytorch代码,再和下面的比对。
# coding=utf-8
from __future__ import absolute_import, division, print_function
import torch
import torchvision
import pickle as pkl
from torch import nn
import torch.nn.functional as F
class SfSNet(nn.Module): # SfSNet = PS-Net in SfSNet_deploy.prototxt
def __init__(self):
# C64
super(SfSNet, self).__init__()
# TODO 初始化器 xavier
self.conv1 = nn.Conv2d(3, 64, 7, 1, 3)
self.bn1 = nn.BatchNorm2d(64)
# C128
self.conv2 = nn.Conv2d(64, 128, 3, 1, 1)
self.bn2 = nn.BatchNorm2d(128)
# C128 S2
self.conv3 = nn.Conv2d(128, 128, 3, 2, 1)
def forward(self, inputs):
# C64
x = F.relu(self.bn1(self.conv1(inputs)))
# C128
x = F.relu(self.bn2(self.conv2(x)))
# C128 S2
conv3 = self.conv3(x)
二、SfSNet的残差块
观察网络的可视化结果,可以发现有很多重复的结构(下面框框里面包着的),SfSNet的作者说它们是残差块(ResidualBlock),其实还是有丢丢区别的,不过不影响我们转换模型。这些重复的结构层数相同,参数相同,就是名字不一样,因此我把每个框框里面的结构实现为一个“ResidualBlock”,以便于重复利用,还能减少出错。
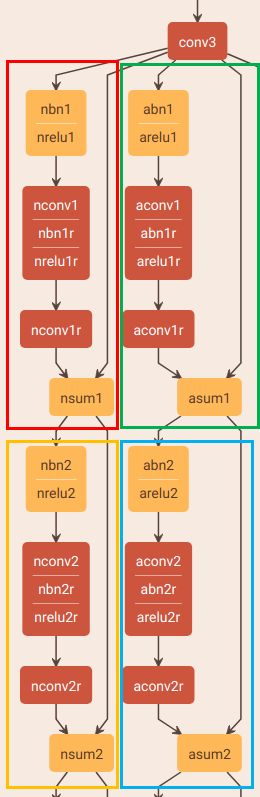
1、Caffe的Eltwise层
layer {
name: "nsum1" # 层名
type: "Eltwise" # 类型:Eltwise
bottom: "nconv1r" # 输入1:nconv1r
bottom: "conv3" # 输入2:conv3
top: "nsum1" # 输出:nsum1
eltwise_param { # 操作类型
operation: SUM # 求和
}
}
顾名思义,Eltwise层就是逐元素的操作(相加、相减等等)。operation指定了类型是SUM(求和)。所以,此层就是将nconv1r和conv3求和,存到nsum1里面。
2、实现一个“ResidualBlock”
直接上代码:
class ResidualBlock(nn.Module):
def __init__(self, in_channel, out_channel):
super(ResidualBlock, self).__init__()
# nbn1/nbn2/.../nbn5 abn1/abn2/.../abn5
self.bn = nn.BatchNorm2d(in_channel)
# nconv1/nconv2/.../nconv5 aconv1/aconv2/.../aconv5
self.conv = nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=1, padding=1)
# nbn1r/nbn2r/.../nbn5r abn1r/abn2r/.../abn5r
self.bnr = nn.BatchNorm2d(out_channel)
# nconv1r/nconv2r/.../nconv5r aconv1r/aconv2r/.../anconv5r
self.convr = nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=1, padding=1)
def forward(self, x):
out = self.conv(F.relu(self.bn(x)))
out = self.convr(F.relu(self.bnr(out)))
# num1/nsum2/.../nsum5 aum1/asum2/.../asum5
out += x
return out
上面就是一个框框内的所有层,都定义在一个ResidualBlock内,并且可以重复使用。Eltwise层使用“+=”替代了,ReLU层使用“F.relu”替代了。接下来就举个例子,说明ResidualBlock怎么用:
class SfSNet(nn.Module): # SfSNet = PS-Net in SfSNet_deploy.prototxt
def __init__(self):
# C64
super(SfSNet, self).__init__()
# TODO 初始化器 xavier
self.conv1 = nn.Conv2d(3, 64, 7, 1, 3)
self.bn1 = nn.BatchNorm2d(64)
# C128
self.conv2 = nn.Conv2d(64, 128, 3, 1, 1)
self.bn2 = nn.BatchNorm2d(128)
# C128 S2
self.conv3 = nn.Conv2d(128, 128, 3, 2, 1)
# ------------RESNET for normals------------
# RES1
self.n_res1 = ResidualBlock(128, 128)
# RES2
self.n_res2 = ResidualBlock(128, 128)
def forward(self, inputs):
# C64
x = F.relu(self.bn1(self.conv1(inputs)))
# C128
x = F.relu(self.bn2(self.conv2(x)))
# C128 S2
conv3 = self.conv3(x)
# ------------RESNET for normals------------
# RES1
x = self.n_res1(conv3)
# RES2
x = self.n_res2(x)
return x
三、反卷积层、Concat层、池化层以及全连接层
1、反卷积层
SfSNet中,还用到了反卷积层,分别为nup6和aup6。

在.prototxt中,一个反卷积层定义为:
#CD128
layer {
name: "nup6" # 层名
type: "Deconvolution" # 类型:Deconvolution
bottom: "nsum5" # 输入:nsum5
top: "nup6" # 输出:nup6
convolution_param { # 卷积参数
kernel_size: 4 # 卷积核大小
stride: 2 # 步长
num_output: 128 # 输出特征数
group: 128 # group大小,不理解是啥意思,不过Pytorch中的反卷积层有同名参数,不慌,小场面
pad: 1 # padding大小
weight_filler { # 权重初始化参数
type: "bilinear" # 权重初始化器类型
}
bias_term: false # 使用偏置:false为不使用
}
param { # 权重学习参数
lr_mult: 0 # 学习率:0
decay_mult: 0 # 学习率衰减率:0
}
}
Pytorch中,反卷积层的定义为:
ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1)
in_channels为输入通道数,在SfSNet中是128;out_channels为输出通道数,也为128;groups对应.prototxt中的“group: 128 ”;bias要设置为false,因为“bias_term: false”,其他参数保持默认,所以,nup6的Pytorch代码为:
aup6 = nn.ConvTranspose2d(128, 128, 4, 2, 1, groups=128, bias=False)
2、Concat层
#concat
layer {
name: "lconcat1" # 层名
bottom: "nsum5" # 输入1:nsum5
bottom: "asum5" # 输入2:asum5
top: "lconcat1" # 输出:lconcat1
type: "Concat" # 类型:lconcat1
concat_param { # Concat参数
axis: 1 # 轴:连接(N, C, H, W)第二维,也就是C(channel)。当axis=0是,连接N,也就是一批的数量
}
}
Pytorch里和Caffe中的Concat层对应的操作是:
torch.cat(tensors, dim=0, out=None) → Tensor
tensors是Tenor组成的列表;dim对应axis;out保持默认。所以,lconcat1对应的Python代码就是:
lconcat1 = torch.cat((nsum5, asum5), 1)
感觉没毛病吧?大错特错!!!,让我们再次打开网络可视化之后的结果:
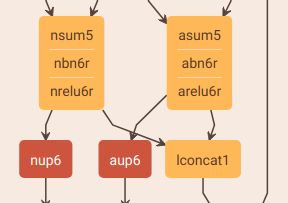
可以看到,lconcat1的两个输入明明是nrelu6r和arelu6r啊,难道是可视化结果错了?为啥.prototxt文件中写成num5和asum5呢?因为nbn6r/abn6r和nrelu6r/arelu6r都是“In-Place”操作(输入输出都是num5/asum5),计算完之后又存回num5/asum5了,所以.prototxt文件写成num5和asum5,实际应为nrelu6r/arelu6r处理后的结果。所以,lconcat1的Pytorch代码应为:
lconcat1 = torch.cat((nrelu6r, arelu6r), 1)
需要特别注意那种“In-Place”操作,要结合可视化图和.prototxt文件来完成模型的转换,免得走弯路啊啊啊啊啊。
3、池化层
layer {
name: "lpool2r" # 层名
type: "Pooling" # 类型:Pooling
bottom: "lconv1" # 输入:lconv1
top: "lpool2r" # 输出:lpool2r
pooling_param { # 池化层参数
pool: AVE # 池化类型:AVE,对应AvgPool2d;还有MAX,对应MaxPool2d.
kernel_size: 64 # 池化核大小
}
}
上面就是池化层的定义。在Pytorch中,上述池化层的对应:
AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True)
kernel_size是池化核大小;其他参数不做说明。lpool2r对应的Pytorch代码为:
lpool2r = nn.AvgPool2d(64)
如果“pool: AVE”里的“AVE”换成“MAX”,那么lpool2r对应的Pytorch代码为:
lpool2r = nn.MaxPool2d(64)
4、全连接层
layer {
name: "fc_light" # 层明
type: "InnerProduct" # 类型:InnerProduct,也就是全连接层
bottom: "lpool2r" # 输入:lpool2r
top: "fc_light" # 输出:fc_light
param { # 权重参数
lr_mult: 1
decay_mult: 1
}
param { # 偏置参数
lr_mult: 2
decay_mult: 0
}
inner_product_param { # 全连接层参数
num_output: 27 # 输出通道数:27
weight_filler { # 权重初始化器参数
type: "gaussian" # 类型:gaussian
std: 0.005 # 标准差:0.005
}
bias_filler { # 偏置初始化参数
type: "constant" # 类型:constant
value: 1 # 值:1
}
}
}
越写到后面越不想写,这篇博客都编辑了五六个小时了(哭,还是坚持写完吧)。上面就是全连接层fc_light的定义,在Pytorch中,对应的层是:
Linear(in_features, out_features, bias=True)
fc_light对应的Pytorch代码为:
fc_light = nn.Linear(128, 27)
等等!!!fc_light前面不是一个lpool2r层吗?
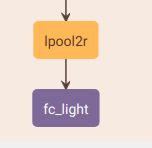
lpool2r层的输出形状是(1, 128, 1, 1),也就是四维啊,全连接层前面应该是一维的啊,所以在Pytorch的模型的forward函数里,还需要reshape(调整为[1, 128]) lpool2r的结果:
class SfSNet(nn.Module):
def __init__(self):
...
def forward(self, inputs):
...
x = self.lpool2r(x)
# 调整输出的shape
x = x.view(-1, 128)
# fc_light
light = self.fc_light(x)
四、总结
- 不懂的多查多看!
- 转换模型要结合.prototxt和可视化结果。