实时海量日志分析系统的架构设计、实现以及思考
1 序
对ETL系统中数据转换和存储操作的相关日志进行记录以及实时分析有助于我们更好的观察和监控ETL系统的相关指标(如单位时间某些操作的处理时间),发现系统中出现的缺陷和性能瓶颈。
由于需要对日志进行实时分析,所以Storm是我们想到的首个框架。Storm是一个分布式实时计算系统,它可以很好的处理流式数据。利用storm我们几乎可以直接实现一个日志分析系统,但是将日志分析系统进行模块化设计可以收到更好的效果。模块化的设计至少有两方面的优点:
- 模块化设计可以使功能更加清晰。整个日志分析系统可以分为“数据采集-数据缓冲-数据处理-数据存储”四个步骤。Apache项目下的flumeng框架可以很好的从多源目标收集数据,所以我们用它来从ETL系统中收集日志信息;由于采集数据与处理数据的速度可能会出现不一致,所以我们需要一个消息中间件来作为缓冲,kafka是一个极好的选择;然后对流式数据的处理,我们将选择大名鼎鼎的storm了,同时为了更好的对数据进行处理,我们把drools与storm进行了整合,分离出了数据处理规则,这样更有利于管理规则;最后,我们选择redis作为我们处理数据的存储工具,redis是一个内存数据库,可以基于健值进行快速的存取。
- 模块化设计之后,storm和前两个步骤之间就获得了很好的解耦,storm集群如果出现问题,数据采集以及数据缓冲的操作还可以继续运行,数据不会丢失。
2 相关框架的介绍和安装
2.1 flumeng
2.1.1 原理介绍
Flume是一个高可用、高可靠、分布式的海量日志采集、聚合和传输系统。Flume支持在日志系统中定制日志发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接收方的能力。它拥有一个简单的、可扩展的流式数据流架构,如下图所示:
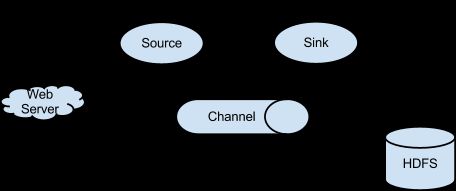
日志收集系统就是由一个或者多个agent(代理)组成,每个agent由source、channel、sink三部分组成,source是数据的来源,channel是数据进行传输的通道,sink用于将数据传输到指定的地方。我们可以把agent看做一段水管,source是水管的入口,sink是水管的出口,数据流就是水流。 Agent本质上是一个jvm进程,agent各个组件之间是通过event来进行触发和协调的。
2.1.2 flumeng的安装
- 从官方网站下载apache-flume-1.4.0-bin.tar.gz压缩包
-
解压缩,并在conf目录下面新建一个文件flume-conf.properties,内容如下:
01234567891011121314151617181920212223a1 . sources = r1a1 . sinks = k1a1 . channels = c1#source配置信息#r1的type为avro表示该source接收的数据协议为avro,且接收数据由avro客户端事件驱动#(也就是说resource要通过avro-cliet向其发送数据)a1 . sources . r1 . type = avroa1 . sources . r1 . bind = localhosta1 . sources . r1 . port = 44444#sink配置信息# type为logger意将数据输出至日志中(也就是打印在屏幕上)a1 . sinks . k1 . type = logger#channel配置信息#type为memory意将数据存储至内存中a1 . channels . c1 . type = memorya1 . channels . c1 . capacity = 1000a1 . channels . c1 . transactionCapacity = 100#将source和sink绑定至该channel上a1 . sources . r1 . channels = c1a1 . sinks . k1 . channel = c1该配置文件,配置了一个 source为 avro的服务器端用于日志的收集。具体的情况将在后面 ETL系统与 flume整合中介绍。 启动代理。flume-ng agent –n a1 –f flume-conf.properties
2.2 kafka
2.2.1 原理介绍
Kafka是linkedin用于日志处理的分布式消息队列。Kafka的架构如下图所示:

Kafka的存储策略有一下几点:
- kafka以topic来进行消息管理,每个topic包括多个partition,每个partition包括一个逻辑log,由多个segment组成。
- 每个segment中存储多条消息,消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。
- 每个partition在内存中对应一个index,记录每个segment中的第一条消息的偏移。
- 发布者发到某个topic的消息会被均匀的分布到多个partition上(随机或根据用户指定的回调函数进行分布),broker收到发布消息往对应partition的最后一个segment上添加该消息,当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被flush到磁盘,只有flush到磁盘上的消息订阅者才能订阅到,segment达到一定的大小后将不会再往该segment写数据,broker会创建新的segment。
2.2.2 kafka集群的搭建
Kafka集群的搭建需要依赖zookeeper来进行负载均衡,所以我们需要在安装kafka之前搭建zookeeper集群。
- zookeeper集群的搭建,本系统用到了两台机器。具体搭建过程见http://blog.csdn.net/itleochen/article/details/17453881
- 分别下载kafka_2.9.2-0.8.1的安装包到两台机器,并解压该安装包。
- 打开conf/server.properties文件,修改配置项broker.id、zookeeper.connect、partitions以及host.name为相应的值。
- 分别启动kafka即完成了集群的搭建。
2.3 storm
2.3.1 原理介绍
Storm是一个分布式的、高容错的实时计算系统。Storm对于实时计算的的意义相当于Hadoop对于批处理的意义。hadoop为我们提供了Map和Reduce原语,使我们对数据进行批处理变的非常的简单和优美。同样,Storm也对数据的实时计算提供了简单Spout和Bolt原语。
Strom集群里面有两种节点,控制节点和工作节点,控制节点上面运行一个nimbus(类似于hadoop中的JobTracker)后台程序,Nimbus负责在集群里面分布代码,分配工作给机器, 并且监控状态。每一个工作节点上面运行一个叫做Supervisor(类似Hadoop中的TaskTracker)的节点。Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程。每一个工作进程执行一个Topology(类似hadoop中的Job)的一个子集;一个运行的Topology由运行在很多机器上的很多工作进程 Worker(类似Hadoop中的Child)组成。结构如下图所示:

Stream是storm里面的关键抽象。一个stream是一个没有边界的tuple序列。storm提供一些原语来分布式地、可靠地把一个stream传输进一个新的stream。比如: 你可以把一个tweets流传输到热门话题的流。
storm提供的最基本的处理stream的原语是spout和bolt。你可以实现Spout和Bolt对应的接口以处理你的应用的逻辑。
Spout是流的源头。比如一个spout可能从Kestrel队列里面读取消息并且把这些消息发射成一个流。通常Spout会从外部数据源(队列、数据库等)读取数据,然后封装成Tuple形式,之后发送到Stream中。Spout是一个主动的角色,在接口内部有个nextTuple函数,Storm框架会不停的调用该函数。
Bolt可以接收任意多个输入stream。Bolt处理输入的Stream,并产生新的输出Stream。Bolt可以执行过滤、函数操作、Join、操作数据库等任何操作。Bolt是一个被动的角色,其接口中有一个execute(Tuple input)方法,在接收到消息之后会调用此函数,用户可以在此方法中执行自己的处理逻辑。
spout和bolt所组成一个网络会被打包成topology, topology是storm里面最高一级的抽象(类似 Job), 你可以把topology提交给storm的集群来运行。Topology的结构如下图所示:

2.3.2 storm集群的搭建
Storm集群的搭建也要依赖于zookeeper,本系统中storm与kafka共用同样一个zookeeper集群。
- 下载安装包storm-0.9.0.1.tar.gz,并对该包进行解压。
配置nimbus。 修改storm的conf/storm.yaml文件如下:
012345678910111213storm . zookeeper . servers : //zookeeper集群- “ 10.200.187.71″- “ 10.200.187.73″storm . local . dir : “ / usr / endy / fks / storm - workdir “storm . messaging . transport : “ backtype . storm . messaging . netty . Context”storm . messaging . netty . server_worker_threads : 1storm . messaging . netty . client_worker_threads : 1storm . messaging . netty . buffer_size : 5242880storm . messaging . netty . max_retries : 100storm . messaging . netty . max_wait_ms : 1000storm . messaging . netty . min_wait_ms : 100注意:在每个配置项前面必须留有空格,否则会无法识别。storm.messaging.* 部分是Netty的配置。如果没有该部分。那么Storm默认还是使用ZeroMQ。
-
配置supervisor 修改storm的conf/storm.yaml文件如下:
0123456789101112131415161718storm . zookeeper . servers :- “ 10.200.187.71″- “ 10.200.187.73″nimbus . host : “ 10.200.187.71″supervisor . slots . ports :- 6700- 6701- 6702storm . local . dir : “ / usr / endy / fks / storm - workdir”storm . messaging . transport : “ backtype . storm . messaging . netty . Context”storm . messaging . netty . server_worker_threads : 1storm . messaging . netty . client_worker_threads : 1storm . messaging . netty . buffer_size : 5242880storm . messaging . netty . max_retries : 100storm . messaging . netty . max_wait_ms : 1000storm . messaging . netty . min_wait_ms : 100
注意
- nimbus.host是nimbus的IP或hostname
- supervisor.slots.ports 是配置slot的ip地址。配了几个地址,就有几个slot,即几个worker。如果尝试提交的topology所声明的worker数超过当前可用的slot,该topology提交会失败。
- storm.messaging 部分是Netty的配置。
2.4 drools
Drools是一个基于Java的、开源的规则引擎,可以将复杂多变的规则从硬编码中解放出来,以规则脚本的形式存放在文件中,使得规则的变更不需要修正代码重启机器就可以立即在线上环境生效。 日志分析系统中,drools的作用是利用不同的规则对日志信息进行处理,以获得我们想要的数据。但是,Drools本身不是一个分布式框架,所以规则引擎对log的处理无法做到分布式。我们的策略是将drools整合到storm的bolt中去,这就就解决了drools无法分布式的问题。这是因为bolt可以作为task分发给多个worker来处理,这样drools中的规则也自然被多个worker处理了。
2.5 redis
Redis是key-value存储系统,它支持较为丰富的数据结构,有String,list,set,hash以及zset。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。 Redis是内存数据库,所以有非常快速的存取效率。日志分析系统数据量并不是特别大,但是对存取的速度要求较高,所以选择redis有很大的优势。
3 各个框架的整合
3.1 ETL系统整合flumeng
Flume如何收集ETL系统中的日志是我需要考虑的第一个问题。log4j2提供了专门的Appender-FlumeAppender用于将log信息发送到flume系统,并不需要我们来实现。我们在log4j2的配置文件中配置了ETL系统将log信息发送到的目的地,即avro服务器端。该服务器端我们在flume的配置文件中进行了配置。配置信息如下所示:
|
0
1
2
3
4
5
6
7
8
9
|
producer
.
sources
=
s
producer
.
channels
=
c
producer
.
sinks
=
r
producer
.
sources
.
s
.
type
=
avro
producer
.
sources
.
s
.
channels
=
c
producer
.
sources
.
s
.
bind
=
10.200.187.71
producer
.
sources
.
s
.
port
=
4141
|
3.2 flumeng与kafka的整合
我们从ETL系统中获得了日志信息,将该信息不作任何处理传递到sink端,sink端发送数据到kafka。这个发送过程需要我们编写代码来实现,我们的实现代码为KafkaSink类。主要代码如下所示:
|
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
public
class
KafkaSink
extends
AbstractSink
implements
Configurable
{
private
static
final
Logger
LOGGER
=
LoggerFactory
.
getLogger
(
KafkaSink
.
class
)
;
private
Properties
parameters
;
private
Producer
<
String
,
String
>
producer
;
private
Context
context
;
@
Override
public
void
configure
(
Context
context
)
{
this
.
context
=
context
;
ImmutableMap
<
String
,
String
>
props
=
context
.
getParameters
(
)
;
parameters
=
new
Properties
(
)
;
for
(
String
key
:
props
.
keySet
(
)
)
{
String
value
=
props
.
get
(
key
)
;
this
.
parameters
.
put
(
key
,
value
)
;
}
}
@
Override
public
synchronized
void
start
(
)
{
super
.
start
(
)
;
ProducerConfig
config
=
new
ProducerConfig
(
this
.
parameters
)
;
this
.
producer
=
new
Producer
<
String
,
String
>
(
config
)
;
}
@
Override
public
Status
process
(
)
throws
EventDeliveryException
{
Status
status
=
null
;
// Start transaction
Channel
ch
=
getChannel
(
)
;
Transaction
txn
=
ch
.
getTransaction
(
)
;
txn
.
begin
(
)
;
try
{
// This try clause includes whatever Channel operations you want to do
Event
event
=
ch
.
take
(
)
;
String
partitionKey
=
(
String
)
parameters
.
get
(
KafkaFlumeConstans
.
PARTITION_KEY_NAME
)
;
String
encoding
=
StringUtils
.
defaultIfEmpty
(
(
String
)
this
.
parameters
.
get
(
KafkaFlumeConstans
.
ENCODING_KEY_NAME
)
,
KafkaFlumeConstans
.
DEFAULT_ENCODING
)
;
String
topic
=
Preconditions
.
checkNotNull
(
(
String
)
this
.
parameters
.
get
(
KafkaFlumeConstans
.
CUSTOME_TOPIC_KEY_NAME
)
,
“
custom
.
topic
.
name
is
required”
)
;
String
eventData
=
new
String
(
event
.
getBody
(
)
,
encoding
)
;
KeyedMessage
<
String
,
String
>
data
;
// if partition key does’nt exist
if
(
StringUtils
.
isEmpty
(
partitionKey
)
)
{
data
=
new
KeyedMessage
<
String
,
String
>
(
topic
,
eventData
)
;
}
else
{
data
=
new
KeyedMessage
<
String
,
String
>
(
topic
,
String
.
valueOf
(
new
Random
(
)
.
nextInt
(
Integer
.
parseInt
(
partitionKey
)
)
)
,
eventData
)
;
}
if
(
LOGGER
.
isInfoEnabled
(
)
)
{
LOGGER
.
info
(“
Send
Message
to
Kafka
:
[
" + eventData + "
]
—
[
" + EventHelper.dumpEvent(event) + "
]“
)
;
}
producer
.
send
(
data
)
;
txn
.
commit
(
)
;
status
=
Status
.
READY
;
}
catch
(
Throwable
t
)
{
txn
.
rollback
(
)
;
status
=
Status
.
BACKOFF
;
// re-throw all Errors
if
(
t
instanceof
Error
)
{
throw
(
Error
)
t
;
}
}
finally
{
txn
.
close
(
)
;
}
return
status
;
}
@
Override
public
void
stop
(
)
{
producer
.
close
(
)
;
}
}
|
该类中,我们读取了一些配置信息,这些配置信息我们在flumeng的flume-conf.properties文件中进行了定义,定义内容如下:
|
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
producer
.
sinks
.
r
.
type
=
org
.
apache
.
flume
.
plugins
.
KafkaSink
producer
.
sinks
.
r
.
metadata
.
broker
.
list
=
10.200.187.71
:
9092
producer
.
sinks
.
r
.
partition
.
key
=
0
producer
.
sinks
.
r
.
serializer
.
class
=
kafka
.
serializer
.
StringEncoder
producer
.
sinks
.
r
.
request
.
required
.
acks
=
0
producer
.
sinks
.
r
.
max
.
message
.
size
=
1000000
producer
.
sinks
.
r
.
producer
.
type
=
sync
producer
.
sinks
.
r
.
custom
.
encoding
=
UTF
-
8
producer
.
sinks
.
r
.
custom
.
topic
.
name
=
fks1
producer
.
sinks
.
r
.
channel
=
c
producer
.
channels
.
c
.
type
=
memory
producer
.
channels
.
c
.
capacity
=
1000
|
将上面的KafkaSink类打包成flumeng-kafka.jar,并将该jar包以及kafka_2.9.2-0.8.1.jar、metrics-annotation-2.2.0.jar、metrics-core-2.2.0.jar、Scala-compiler.jar、scala-library.jar、zkclient-0.3.jar放到flume的lib目录下,启动flume,我们就可以将ETL系统中产生的日志信息发送到kafka中的fks1这个topic中去了。
3.3 kafka与storm的整合
Storm中的spout如何主动消费kafka中的消息需要我们编写代码来实现,httpsgithub.comwurstmeisterstorm-kafka-0.8-plus实现了一个kafka与storm整合的插件,下载该插件,将插件中的jar包以及metrics-core-2.2.0.jar、scala-compiler2.9.2.jar放到storm的lib目录下。利用插件中的StormSpout类,我们就可以消费kafka中的消息了。主要代码如下所示:
|
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
|
public
class
KafkaSpout
extends
BaseRichSpout
{
public
static
class
MessageAndRealOffset
{
public
Message
msg
;
public
long
offset
;
public
MessageAndRealOffset
(
Message
msg
,
long
offset
)
{
this
.
msg
=
msg
;
this
.
offset
=
offset
;
}
}
static
enum
EmitState
{
EMITTED_MORE_LEFT
,
EMITTED_END
,
NO
_EMITTED
}
public
static
final
Logger
LOG
=
LoggerFactory
.
getLogger
(
KafkaSpout
.
class
)
;
String
_uuid
=
UUID
.
randomUUID
(
)
.
toString
(
)
;
SpoutConfig
_spoutConfig
;
SpoutOutputCollector
_collector
;
PartitionCoordinator
_coordinator
;
DynamicPartitionConnections
_connections
;
ZkState
_state
;
long
_lastUpdateMs
=
0
;
int
_currPartitionIndex
=
0
;
public
KafkaSpout
(
SpoutConfig
spoutConf
)
{
_spoutConfig
=
spoutConf
;
}
@
Override
public
void
open
(
Map
conf
,
final
TopologyContext
context
,
final
SpoutOutputCollector
collector
)
{
_collector
=
collector
;
Map
stateConf
=
new
HashMap
(
conf
)
;
List
zkServers
=
_spoutConfig
.
zkServers
;
if
(
zkServers
==
null
)
{
zkServers
=
(
List
)
conf
.
get
(
Config
.
STORM_ZOOKEEPER_SERVERS
)
;
}
Integer
zkPort
=
_spoutConfig
.
zkPort
;
if
(
zkPort
==
null
)
{
zkPort
=
(
(
Number
)
conf
.
get
(
Config
.
STORM_ZOOKEEPER_PORT
)
)
.
intValue
(
)
;
}
stateConf
.
put
(
Config
.
TRANSACTIONAL_ZOOKEEPER_SERVERS
,
zkServers
)
;
stateConf
.
put
(
Config
.
TRANSACTIONAL_ZOOKEEPER_PORT
,
zkPort
)
;
stateConf
.
put
(
Config
.
TRANSACTIONAL_ZOOKEEPER_ROOT
,
_spoutConfig
.
zkRoot
)
;
_state
=
new
ZkState
(
stateConf
)
;
_connections
=
new
DynamicPartitionConnections
(
_spoutConfig
,
KafkaUtils
.
makeBrokerReader
(
conf
,
_spoutConfig
)
)
;
// using TransactionalState like this is a hack
int
totalTasks
=
context
.
getComponentTasks
(
context
.
getThisComponentId
(
)
)
.
size
(
)
;
if
(
_spoutConfig
.
hosts
instanceof
StaticHosts
)
{
_coordinator
=
new
StaticCoordinator
(
_connections
,
conf
,
_spoutConfig
,
_state
,
context
.
getThisTaskIndex
(
)
,
totalTasks
,
_uuid
)
;
}
else
{
_coordinator
=
new
ZkCoordinator
(
_connections
,
conf
,
_spoutConfig
,
_state
,
context
.
getThisTaskIndex
(
)
,
totalTasks
,
_uuid
)
;
}
context
.
registerMetric
(“
kafkaOffset”
,
new
IMetric
(
)
{
KafkaUtils
.
KafkaOffsetMetric
_kafkaOffsetMetric
=
new
KafkaUtils
.
KafkaOffsetMetric
(
_spoutConfig
.
topic
,
_connections
)
;
@
Override
public
Object
getValueAndReset
(
)
{
List
pms
=
_coordinator
.
getMyManagedPartitions
(
)
;
Set
latestPartitions
=
new
HashSet
(
)
;
for
(
PartitionManager
pm
:
pms
)
{
latestPartitions
.
add
(
pm
.
getPartition
(
)
)
;
}
_kafkaOffsetMetric
.
refreshPartitions
(
latestPartitions
)
;
for
(
PartitionManager
pm
:
pms
)
{
_kafkaOffsetMetric
.
setLatestEmittedOffset
(
pm
.
getPartition
(
)
,
pm
.
lastCompletedOffset
(
)
)
;
}
return
_kafkaOffsetMetric
.
getValueAndReset
(
)
;
}
}
,
60
)
;
context
.
registerMetric
(“
kafkaPartition”
,
new
IMetric
(
)
{
@
Override
public
Object
getValueAndReset
(
)
{
List
pms
=
_coordinator
.
getMyManagedPartitions
(
)
;
Map
concatMetricsDataMaps
=
new
HashMap
(
)
;
for
(
PartitionManager
pm
:
pms
)
{
concatMetricsDataMaps
.
putAll
(
pm
.
getMetricsDataMap
(
)
)
;
}
return
concatMetricsDataMaps
;
}
}
,
60
)
;
}
@
Override
public
void
close
(
)
{
_state
.
close
(
)
;
}
@
Override
public
void
nextTuple
(
)
{
List
managers
=
_coordinator
.
getMyManagedPartitions
(
)
;
for
(
int
i
=
0
;
i
<
managers
.
size
(
)
;
i
++
)
{
// in case the number of managers decreased _currPartitionIndex = _currPartitionIndex % managers.size(); EmitState state = managers.get(_currPartitionIndex).next(_collector); if (state != EmitState.EMITTED_MORE_LEFT) { _currPartitionIndex = (_currPartitionIndex + 1) % managers.size(); } if (state != EmitState.NO_EMITTED) { break; } } long now = System.currentTimeMillis(); if ((now – _lastUpdateMs) > _spoutConfig.stateUpdateIntervalMs) {
commit
(
)
;
}
}
@
Override
public
void
ack
(
Object
msgId
)
{
KafkaMessageId
id
=
(
KafkaMessageId
)
msgId
;
PartitionManager
m
=
_coordinator
.
getManager
(
id
.
partition
)
;
if
(
m
!=
null
)
{
m
.
ack
(
id
.
offset
)
;
}
}
@
Override
public
void
fail
(
Object
msgId
)
{
KafkaMessageId
id
=
(
KafkaMessageId
)
msgId
;
PartitionManager
m
=
_coordinator
.
getManager
(
id
.
partition
)
;
if
(
m
!=
null
)
{
m
.
fail
(
id
.
offset
)
;
}
}
@
Override
public
void
deactivate
(
)
{
commit
(
)
;
}
@
Override
public
void
declareOutputFields
(
OutputFieldsDeclarer
declarer
)
{
declarer
.
declare
(
_spoutConfig
.
scheme
.
getOutputFields
(
)
)
;
}
private
void
commit
(
)
{
_lastUpdateMs
=
System
.
currentTimeMillis
(
)
;
for
(
PartitionManager
manager
:
_coordinator
.
getMyManagedPartitions
(
)
)
{
manager
.
commit
(
)
;
}
}
}
|
3.4
storm中bolt与drools的整合 Drools可以将storm中处理数据的规则提取到一个drl文件中,该文件就成了唯一处理规则的文件。任何时候规则出现变化,我们只需要修改该drl文件,而不会改变其它的代码。Bolt与drools的整合代码如下所示:
|
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
public
class
LogRulesBolt
implements
IBasicBolt
{
Logger
logger
=
LoggerFactory
.
getLogger
(
LogRulesBolt
.
class
)
;
private
static
final
long
serialVersionUID
=
1L
;
public
static
final
String
LOG_ENTRY
=
“
str”
;
private
StatelessKnowledgeSession
ksession
;
private
String
drlFile
;
public
LogRulesBolt
(
)
{
}
public
LogRulesBolt
(
String
drlFile
)
{
this
.
drlFile
=
drlFile
;
}
@
Override
public
void
prepare
(
Map
stormConf
,
TopologyContext
context
)
{
KnowledgeBuilder
kbuilder
=
KnowledgeBuilderFactory
.
newKnowledgeBuilder
(
)
;
try
{
kbuilder
.
add
(
ResourceFactory
.
newInputStreamResource
(
new
FileInputStream
(
new
File
(
drlFile
)
)
)
,
ResourceType
.
DRL
)
;
}
catch
(
FileNotFoundException
e
)
{
logger
.
error
(
e
.
getMessage
(
)
)
;
}
KnowledgeBase
kbase
=
KnowledgeBaseFactory
.
newKnowledgeBase
(
)
;
kbase
.
addKnowledgePackages
(
kbuilder
.
getKnowledgePackages
(
)
)
;
ksession
=
kbase
.
newStatelessKnowledgeSession
(
)
;
}
@
Override
public
void
execute
(
Tuple
input
,
BasicOutputCollector
collector
)
{
String
logContent
=
(
String
)
input
.
getValueByField
(
LOG_ENTRY
)
;
logContent
=
logContent
.
trim
(
)
;
if
(
!””
.
equals
(
logContent
)
&&
logContent
!=
null
)
{
LogEntry
entry
=
new
LogEntry
(
logContent
)
;
try
{
ksession
.
execute
(
entry
)
;
}
catch
(
Exception
e
)
{
logger
.
error
(“
drools
to
handle
log
[
"+logContent+"
]
is
failure
!”
)
;
logger
.
error
(
e
.
getMessage
(
)
)
;
}
collector
.
emit
(
new
Values
(
entry
)
)
;
}
else
{
logger
.
error
(“
log
content
is
empty
!”
)
;
}
}
@
Override
|