按图索骥:SQL中数据倾斜问题的处理思路与方法

数据倾斜即表中某个字段的值分布不均匀,比如有100万条记录,其中字段A中有90万都是相同的值。这种情况下,字段A作为过滤条件时,可能会引起一些性能问题。
未使用绑定变量
使用绑定变量
几种特殊场景
1
测试环境说明
数据库版本:ORACLE 11.2.0.4
新建测试表tb_test:
create tablescott.tb_test as select * from dba_objects;
创建索引:
create indexscott.idx_tb_test_01 on scott.tb_test(object_id);
更新数据,使用数据分布不均匀:
update scott.tb_testset object_id=10 where object_id>10;
commit;
查看数据分布情况:
select object_id,count(1) from scott.tb_test groupby object_id;
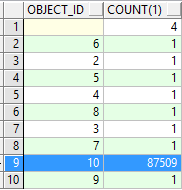
2
未使用绑定变量
未使用绑定变量的情况下通常数据分布不均匀不会造成问题,但这主要依赖于三个方面:
数据分布不均匀的字段是否做为过滤条件或连接条件。
数据分布不均匀的字段是否有收集直方图,如果没有收集直方图就可能会有问题。在没有收集直方图的情况下,这个字段的过滤性DENSITY都是等于1/NUM_DISTINCT;在收集了直方图的情况下,这个字段的过滤性会根据条件值在直方图中的分布比例来计算。
数据库cursor_sharing参数的值是否为exact,如果参数的值为force,相当于使用绑定变量。那就会存在类似使用绑定变量时存在的问题,下节会讲到。
未收集直方图的情况:
对测试表tb_test进行统计信息收集,收集时指定不收集字段object_id的直方图:
begin
dbms_stats.gather_table_stats('scott','TB_TEST', method_opt => 'forcolumns object_id size 1',cascade=>true);
end;
确认是否收集了直方图:
selecttable_name,column_name,histogram from dba_tab_col_statistics
wheretable_name='TB_TEST' and column_name='OBJECT_ID';
![]()
从上图可以看出字段OBJECT_ID未收集直方图。
执行测试SQL:
返回记录比较少的值:
select * fromscott.TB_TEST where object_id=1;
返回记录比较多的值:
select * fromscott.TB_TEST where object_id=10;
查看SQL信息:
selectsql_text,sql_id,plan_hash_value from v$sql
where sql_text like'select * from scott.TB_TEST where object_id=%';

从上图可以看出,两条SQL的PLAN_HASH_VALUE是一样的,也就是走了相同的执行计划。
再看一下这两条SQL的执行计划:
SELECT SQL_ID,
PLAN_HASH_VALUE,
LPAD(' ', 4 * DEPTH) || OPERATION ||OPTIONS OPERATION,
OBJECT_NAME,
CARDINALITY,
BYTES,
COST,
TIME
FROM V$SQL_PLAN
WHERE sql_id in('8zqcak67wwh8f','bfag4mr23qht5')
ORDER BY ADDRESS, ID

从上面也可以看出两条SQL的执行计划是相同的。
收集直方图的情况:
下面收集字段OBJECT_ID的直方图:
begin
dbms_stats.gather_table_stats('scott','TB_TEST', method_opt => 'forcolumns object_id size auto',cascade=>true);
end;
确认是否收集了直方图:
selecttable_name,column_name,histogram from dba_tab_col_statistics
wheretable_name='TB_TEST' and column_name='OBJECT_ID';
![]()
select * fromdba_tab_histograms
wheretable_name='TB_TEST' and column_name='OBJECT_ID';
![]()
从上图可以看出字段OBJECT_ID有收集直方图。
重新执行SQL:
返回记录比较少的值:
select * from scott.TB_TEST where object_id=1;
返回记录比较多的值:
select * fromscott.TB_TEST where object_id=10;
查看SQL信息:
selectsql_text,sql_id,plan_hash_value,address,hash_value from v$sql
where sql_text like'select * from scott.TB_TEST where object_id=%';
![]()
从上面可以看出,两条SQL依然使用之前相同的执行计划,执行计划并没有根据数据分布发生改变。
这是因为我们在收集统计信息时,未指定参数no_invalidate => false,原本这两条SQL的CURSOR未失效,没有进行重新解析。
我们通过以下存储过程将这两个CURSOR清除,这样再执行就会重新解析了。
BEGIN
DBMS_SHARED_POOL.PURGE('00000000B34598F8,2412658958', 'C');
DBMS_SHARED_POOL.PURGE('00000000B37AEDE8,3292218149', 'C');
END;
确认是否已清除:
selectsql_text,sql_id,plan_hash_value,address,hash_value from v$sql
where sql_text like 'select *from scott.TB_TEST where object_id=%';
![]()
从上面可以看出查询无结果,说明已经清除。
让已存在的CURSOR失效的方法:
1、在收集统计时,加no_invalidate => false参数:
begin
dbms_stats.gather_table_stats('scott','TB_TEST', method_opt => 'forcolumns object_id size auto',cascade=>true,no_invalidate =>false );
end;
2、整个刷新share pool
alter system flushshared_pool;
3、对这个表做ddl操作或授权都可以。
但以上说的这些方法,因为影响范围的不同,风险也不同。
相对来讲,DBMS_SHARED_POOL.PURGE影响是最小的,只对指定的CURSOR做清除。由于我是在个人的测试环境上演示,后面我为了方便操作,直接alter system flush shared_pool。
上面通过DBMS_SHARED_POOL.PURGE将两个CURSOR清除后,再次执行SQL:
返回记录比较少的值:
select * fromscott.TB_TEST where object_id=1;
返回记录比较多的值:
select * fromscott.TB_TEST where object_id=10;
查看SQL信息:
selectsql_text,sql_id,plan_hash_value from v$sql
where sql_text like'select * from scott.TB_TEST where object_id=%';

从上图的PLAN_HASH_VALUE可以看出,两条SQL使用了不同的执行计划。
对于数据分布不均匀是否可使用非绑定变量来解决,主要注意两个方面,SQL执行的频率,数据分布不均匀字段上的NUM_DISTINCT值的数量。注意这两个方面根本上都是为了防止使用非绑定变量引起的硬解析问题。
3
使用绑定变量
以下讨论的前提是已经对字段object_id收集过直方图的情况。
执行下面两个pl/sql,两个绑定变量的数据分布不同:
返回记录比较少的值:
DECLARE
V_SQL VARCHAR2(3000);
BEGIN
V_SQL := 'select * from scott.tb_test whereobject_id=:1';
EXECUTE IMMEDIATE V_SQL
USING 1;
END;
返回记录比较多的值:
DECLARE
V_SQLVARCHAR2(3000);
BEGIN
V_SQL := 'select* from scott.tb_test where object_id=:1';
EXECUTE IMMEDIATEV_SQL
USING 10;
END;
从下面的查询结果可以看出,两个绑定变量的数据分布不同,但SQL只生成了一个执行计划:
select sql_id,plan_hash_value,a.sql_text from v$sql a
where sql_text like'select * from scott.tb_test where object_id=:1';
![]()
从上面可以看出虽然字段OBJECT_ID上有使用直方图,但因为使用了绑定变量,ORACLE只硬解析了一次。Oracle 9i就开始引入的BIND PEEK不能解决这个问题,因为BIND PEEK只是发生在第一次硬解析。
解决方法:
方法1:通过在应用代码中判断
为了避免非绑定变量的解析问题,并且可以在逻辑上将倾斜的值区分出来,则可以在应用代码中根据值的不同让其它走不同的执行计划。
伪代码:
if variable =10then
execute‘select /*+full(TB_TEST)*/ * from scott.TB_TEST where object_id=:1’using variable;
else
execute‘select /*+index(TB_TEST IDX_TB_TEST_01)*/* from scott.TB_TEST whereobject_id=:1’using variable;
…
end if;
方法2:通过HINT:bindaware
上面刚才讲到Oracle 9i就开始引入的BIND PEEK不能解决这个问题,因为只会在第一次硬解析的时候去窥视绑定变量的值。从ORACLE11G开始引入了ACS的特性,即AdaptiveCursor Sharing自适应游标,它可以共享监视候选查询的执行统计信息,并使相同的查询能够生成和使用不同的绑定值集合的不同执行计划。例如,优化器可能会选择绑定值1的一个执行计划和绑定值10的一个执行计划。
自适应游标的主要依赖于bind_sensitive游标的绑定敏感性和bind_aware游标的绑定感知性。大概的作用就是在数据库第一次执行一条SQL语句时,做一次硬解析,优化器发现使用绑定变量并在过滤条件上有直方图,它将存储游标的执行统计信息。在下一次使用不同绑定值执行相同SQL进行软解析时,把执行统计信息和存储在游标中的执行统计信息进行比较,来决定是否产生新的执行计划。这些执行统计信息可以在V$SQL_CS_*相关的视图查看。
V$SQL_CS_HISTOGRAM:在执行历史直方图上显示执行统计的分布。
V$SQL_CS_SELECTIVITY:对带绑定变量的过滤条件显示存储在游标中的选择性区域或范围。
V$SQL_CS_STATISTICS:包含数据库收集的执行信息,用来确定是否应该使用BIND_AWARE的游标共享。
另外在V$SQL中增加了IS_BIND_SENSITIVE和IS_BIND_AWARE列,来标识一个游标是否为绑定敏感和是否感知游标共享。
自适应游标的概念文档可参考:Adaptive Cursor Sharing: Overview(Doc ID 740052.1)。
默认自适应游标特性是开启的,默认参数为:
--_optim_peek_user_binds=TRUE
_optimizer_adaptive_cursor_sharing=TRUE
_optimizer_extended_cursor_sharing=UDO
_optimizer_extended_cursor_sharing_rel=SIMPLE
但根据我们的最佳实践是不建议开启的,防止大量SQL执行计划的可变性引起的不稳定和新特性带来的Bug,但我们可以针对指定的SQL语句使用。
下面演示通过SQL_PATCH对SQL加BIND_AWARE的HINT,解决数据倾斜的问题。
同样是上面测试的SQL,我们对SQL增加BIND_AWARE的HINT:
DECLARE
V_SQL CLOB;
begin
--取出原SQL的文本
SELECTSQL_FULLTEXT INTO V_SQL FROM V$SQL WHERE SQL_ID = 'fgagrcttxvq2a' AND ROWNUM =1;
--增加HINT
sys.dbms_sqldiag_internal.i_create_patch(sql_text => V_SQL,
hint_text => 'BIND_AWARE',
name => 'sql_fgagrcttxvq2a');
end;
执行成功后,可在dba_sql_patches视图中查看相关信息
select * from dba_sql_patches
where name='sql_fgagrcttxvq2a';
![]()
顺便说一下,下面是dbms_sqldiag_internal.i_create_patch的存储过程,可以看出它其实也是调用了I_CREATE_SQL_PROFILE这个过程,和使用SQL_PROFILE在底层是一样的。只是当前的场景使用sql_patch要比使用SQL_PROFILE要方便。
PACKAGE dbms_sqldiag_internal
PROCEDURE I_CREATE_PATCH(
SQL_TEXT IN CLOB,
HINT_TEXT IN VARCHAR2,
NAME IN VARCHAR2 := NULL,
DESCRIPTION IN VARCHAR2 := NULL,
CATEGORY IN VARCHAR2 :='DEFAULT',
VALIDATE IN BOOLEAN := TRUE)
IS
RET_NAME VARCHAR2(30);
HS SYS.SQLPROF_ATTR;
BEGIN
COMMIT;
DBMS_SMB.CHECK_SMB_PRIV;
HS:= SYS.SQLPROF_ATTR(HINT_TEXT);
RET_NAME := DBMS_SQLTUNE_INTERNAL.I_CREATE_SQL_PROFILE(
SQL_TEXT => SQL_TEXT,
PROFILE_XML =>DBMS_SMB_INTERNAL.VARR_TO_HINTS_XML(HS),
NAME => NAME,
DESCRIPTION => DESCRIPTION,
CATEGORY => CATEGORY,
CREATOR => SYS_CONTEXT('USERENV', 'SESSION_USER'),
VALIDATE => VALIDATE,
TYPE => 'PATCH',
IS_PATCH => TRUE);
END;
清空共享池:
alter system flush shared_pool;
下面看一下使用BIND_AWARE这个HINT后的效果:执行下面两个pl/sql,两个绑定变量的数据分布不同
返回记录比较少的值:
DECLARE
V_SQLVARCHAR2(3000);
BEGIN
V_SQL := 'select* from scott.tb_test where object_id=:1';
EXECUTE IMMEDIATEV_SQL
USING 1;
END;
返回记录比较多的值:
DECLARE
V_SQLVARCHAR2(3000);
BEGIN
V_SQL := 'select* from scott.tb_test where object_id=:1';
EXECUTE IMMEDIATEV_SQL
USING 10;
END;
查看SQL信息:
select sql_id,plan_hash_value,a.sql_text,is_bind_sensitive,is_bind_aware,is_shareable,sql_patchfrom v$sql a
where sql_text like 'select * from scott.tb_test whereobject_id=:1';

从上面可以看出,ORACLE根据数据分布选择了不同的执行计划,并且都有使用到这个SQL_PATCH。
查看ACS(adaptive cursor sharing)和bind peek相关参数:
select name,value
from (selectnam.ksppinm name,
val.KSPPSTVL value,
--nam.ksppdesc description,
val.ksppstdf isdefault
fromsys.x$ksppi nam, sys.x$ksppcv val
wherenam.inst_id = val.inst_id
andnam.indx = val.indx)
where name in('_optimizer_adaptive_cursor_sharing',
'_optimizer_extended_cursor_sharing_rel',
'_optimizer_extended_cursor_sharing',
'_optim_peek_user_binds')
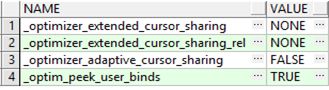
从上面可以看出ACS是关闭的,说明这种方法在ACS关闭的情况下也是可以生效的。
上面的测试中,_optim_peek_user_binds=TRUE,如果_optim_peek_user_binds=FALSE,将dbms_sqldiag_internal.i_create_patch中的hint_text值改为'OPT_PARAM(''_optim_peek_user_binds'' ''true'') BIND_AWARE'即可。
如果不再需要SQLPATCH,可通过dbms_sqldiag.drop_sql_patch删除。
方法3:通过SPM
通过DBMS_SPM.evolve_sql_plan_baseline演化基线的方式。此方法不再演示,可参考文档:How to Evolve a SQL Plan Baseline and Adjust the AcceptanceThreshold (Doc ID 1617790.1)。
4
其它特殊情况
单字段分布不均匀,多字段分布均匀
举个简单的例子:
select * from tb where a=:1 and b=:2
字段a和字段b都是数据分布不均匀的字段,但业务逻辑上,在同一行记录中,字段a或者字段b,会有一个是过滤性强的。之前用户分别在字段a和字段b上建了两个索引。这样在绑定变量的情况下,就会出现这条SQL一直选择其中一个索引做索引范围扫描,当遇到倾斜的值时就会出现性能问题。最后通过将字段a和字段b建复合索引解决了此问题,当创建复合索引后,字段a或字段b其中一个值是倾斜时不会影响索引扫描的性能。
Null分布问题
举个简单的例子:
select * from tb where a isnull;
表tb中大部分记录中字段a的值都为非空,经常要查询字段a为 空的记录。单独在字段a上建索引,由于此索引中不存null值,所以where条件a is null无法走索引。可通过建(a,1)的复合索引将字段a的NULL值也存进去,使a is null使用索引。
!=分布问题
举个简单的例子:
select * from tb where a !=1;
表tb中大部分记录中字段a的值都为1,经常要查询字段a!=1的记录,字段a为not null。单独在字段a上建索引,通常这样的SQL是会走全表扫描,如果强制走索引会走index full scan效率也不高。对于这种情况,如果想提高此SQL的性能,当字段a中!=1的值种类固定且不多时,可以将where条件a!=1改写为a in (x,y,z) 的形式--X/Y/Z为!=1的值;当字段a中!=1的值种类不固定,可以建函数索引decode(a,1,null,'2'),并将where条件a!=1改写为decode(a,1,null,'2')='2',使其走索引范围扫描,提高SQL性能。
关注本公众号,回复:prelection,你可以找到本文的相关视频文档。
![]()
相关阅读:
循序渐进Oracle - 全面认识Oracle ASH
从数据倾斜到布隆过滤深度理解Oracle的并行
从生产者到消费者模型深度理解Oracle的并行
深入剖析:oracle 的并行机制
资源下载
关注公众号:数据和云(OraNews)回复关键字获取
‘2017DTC’,2017DTC大会PPT
‘DBALIFE’,“DBA的一天”海报
‘DBA04’,DBA手记4经典篇章电子书
‘RACV1’, RAC系列课程视频及ppt
‘122ARCH’,Oracle 12.2体系结构图
‘2017OOW’,Oracle OpenWorld资料
‘PRELECTION’,大讲堂讲师课程资料
