tensorflow复现googlenet_v1,非高度集成模块
本次使用tensorflow的tf.nn函数,在尽可能少地定义函数的情况下复现googlenet-v1


这里demo在每一个inception是堆叠卷积后的结果,使用tf.concat函数可以。这里官方手册上给的通道在前,需要连接的多维矩阵在后,但是高版本的tensorflow是反过来的。
新版tensorflow:
layer_4a = tf.concat([layer_4a_1, layer_4a_2_2, layer_4a_3_2, layer_4a_4], 3)旧版tensorflow:
layer_4a = tf.concat(3, [layer_4a_1, layer_4a_2_2, layer_4a_3_2, layer_4a_4])最后附上完整的demo,未进行优化,demo较长,很笨重,但是较为方便理解。
import tensorflow as tf
# REGULARIZER = 0.01
BATCH_SIZE = 10
def weight_variable(shape, name=None):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial, name)
def bias_variable(shape,name=None):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial, name)
def conv2d(input, filter, strides, padding="SAME", name=None):
# filters with shape [filter_height * filter_width * in_channels, output_channels]
# Must have strides[0] = strides[3] =1
# For the most common case of the same horizontal and vertices strides, strides = [1, stride, stride, 1]
'''
Args:
input: A Tensor. Must be one of the following types: float32, float64.
filter: A Tensor. Must have the same type as input.
strides: A list of ints. 1-D of length 4. The stride of the sliding window for each dimension of input.
padding: A string from: "SAME", "VALID". The type of padding algorithm to use.
use_cudnn_on_gpu: An optional bool. Defaults to True.
name: A name for the operation (optional).
'''
return tf.nn.conv2d(input, filter, strides, padding="SAME", name=name) # padding="SAME"用零填充边界
def GoogLeNet_v1(input, keep_prob = 0.4):
'''参考论文: Going deeper with convolutions'''
# input_size:(224,224,3)
# Part1
kernel_1 = weight_variable([7,7,3,64], name = 'kernel_1')
bias_1 = bias_variable([64], name = 'bias_1')
conv_layer_1 = conv2d(input, kernel_1, [1,2,2,1], name = 'conv_layer_1') + bias_1 # size = (112,112,64)
layer_1 = tf.nn.relu(conv_layer_1, name = 'layer_1') # size = (112,112,64)
maxpool_1 = tf.nn.max_pool(layer_1, ksize=[1,3,3,1], strides=[1,2,2,1], padding="SAME", name='maxpool_1') # size = (56,56,64)
LocalRespNorm_1 = tf.nn.local_response_normalization(maxpool_1, name='LocalRespNorm_1') # size = (56,56,64)
# Part2
kernel_2_reduce = weight_variable([1,1,64,64], name = 'kernel_2_reduce')
kernel_2 = weight_variable([3,3,64,192], name = 'kernel_2')
bias_2_reduce = bias_variable([64], name = 'bias_2_reduce')
bias_2 = bias_variable([192], name = 'bias_2')
conv_layer_2_reduce = conv2d(LocalRespNorm_1, kernel_2_reduce, [1,1,1,1],padding='VALID', name = 'conv_layer_2_reduce') + bias_2_reduce # size = (56,56,64) 这里的padding不确定是不是SAME,论文上可能是VALID
layer_2_reduce = tf.nn.relu(conv_layer_2_reduce, name = 'layer_2_reduce') # size = (56,56,64)
conv_layer_2 = conv2d(layer_2_reduce, kernel_2, [1,1,1,1], name = 'conv_layer_2') + bias_2 # size = (56,56,192)
layer_2 = tf.nn.relu(conv_layer_2, name = 'layer_2') # size = (56,56,192)
LocalRespNorm_2 = tf.nn.local_response_normalization(layer_2, name='LocalRespNorm_2') # size = (56,56,192)
max_pool_2 = tf.nn.max_pool(LocalRespNorm_2, ksize=[1,3,3,1], strides=[1,2,2,1], padding="SAME", name='maxpool_2') # size = (28,28,192)
# Part3a
kernel_3a_1 = weight_variable([1,1,192,64], name = 'kernel_3a_1')
kernel_3a_2_1 = weight_variable([1,1,192,96], name = 'kernel_3a_2_1')
kernel_3a_2_2 = weight_variable([3,3,96,128], name = 'kernel_3a_2_2')
kernel_3a_3_1 = weight_variable([1,1,192,16], name = 'kernel_3a_3_1')
kernel_3a_3_2 = weight_variable([5,5,16,32], name = 'kernel_3a_3_2')
kernel_3a_4 = weight_variable([1,1,192,32], name = 'kernel_3a_4')
bias_3a_1 = bias_variable([64], name = 'bias_3a_1')
bias_3a_2_1 = bias_variable([96], name = 'bias_3a_2_1')
bias_3a_2_2 = bias_variable([128], name = 'bias_3a_2_2')
bias_3a_3_1 = bias_variable([16], name = 'bias_3a_3_1')
bias_3a_3_2 = bias_variable([32], name = 'bias_3a_3_2')
bias_3a_4 = bias_variable([32], name = 'bias_3a_4')
layer_3a_1 = tf.nn.relu(conv2d(max_pool_2, kernel_3a_1, [1,1,1,1], name = 'conv_layer_3a_1') + bias_3a_1, name = 'layer_3a_1') # size = (28,28,64)
layer_3a_2_1 = tf.nn.relu(conv2d(max_pool_2, kernel_3a_2_1, [1,1,1,1], name = 'conv_layer_3a_2_1') + bias_3a_2_1, name = 'layer_3a_2_1') # size = (28,28,96)
layer_3a_2_2 = tf.nn.relu(conv2d(layer_3a_2_1, kernel_3a_2_2, [1,1,1,1], name = 'conv_layer_3a_2_2') + bias_3a_2_2, name = 'layer_3a_2_2') # size = (28,28,128)
layer_3a_3_1 = tf.nn.relu(conv2d(max_pool_2, kernel_3a_3_1, [1,1,1,1], name = 'conv_layer_3a_3_1') + bias_3a_3_1, name = 'layer_3a_3_1') # size = (28,28,16)
layer_3a_3_2 = tf.nn.relu(conv2d(layer_3a_3_1, kernel_3a_3_2, [1,1,1,1], name = 'conv_layer_3a_3_2') + bias_3a_3_2, name = 'layer_3a_3_2') # size = (28,28,32)
max_pool_3a_1 = tf.nn.max_pool(max_pool_2, ksize=[1,3,3,1], strides=[1,1,1,1], padding="SAME", name='maxpool_3a_1') # size = (28,28,192)
layer_3a_4 = tf.nn.relu(conv2d(max_pool_3a_1, kernel_3a_4, [1,1,1,1], name = 'conv_layer_3a_4') + bias_3a_4, name = 'layer_3a_4') # size = (28,28,32)
layer_3a = tf.concat([layer_3a_1, layer_3a_2_2, layer_3a_3_2, layer_3a_4], 3) # size = (28,28,256)
# Part3b
kernel_3b_1 = weight_variable([1,1,256,128], name = 'kernel_3b_1')
kernel_3b_2_1 = weight_variable([1,1,256,128], name = 'kernel_3b_2_1')
kernel_3b_2_2 = weight_variable([3,3,128,192], name = 'kernel_3b_2_2')
kernel_3b_3_1 = weight_variable([1,1,256,32], name = 'kernel_3b_3_1')
kernel_3b_3_2 = weight_variable([5,5,32,96], name = 'kernel_3b_3_2')
kernel_3b_4 = weight_variable([1,1,256,64], name = 'kernel_3b_4')
bias_3b_1 = bias_variable([128], name = 'bias_3b_1')
bias_3b_2_1 = bias_variable([128], name = 'bias_3b_2_1')
bias_3b_2_2 = bias_variable([192], name = 'bias_3b_2_2')
bias_3b_3_1 = bias_variable([32], name = 'bias_3b_3_1')
bias_3b_3_2 = bias_variable([96], name = 'bias_3b_3_2')
bias_3b_4 = bias_variable([64], name = 'bias_3b_4')
layer_3b_1 = tf.nn.relu(conv2d(layer_3a, kernel_3b_1, [1,1,1,1], name = 'conv_layer_3b_1') + bias_3b_1, name = 'layer_3b_1') # size = (28,28,128)
layer_3b_2_1 = tf.nn.relu(conv2d(layer_3a, kernel_3b_2_1, [1,1,1,1], name = 'conv_layer_3b_2_1') + bias_3b_2_1, name = 'layer_3b_2_1') # size = (28,28,128)
layer_3b_2_2 = tf.nn.relu(conv2d(layer_3b_2_1, kernel_3b_2_2, [1,1,1,1], name = 'conv_layer_3b_2_2') + bias_3b_2_2, name = 'layer_3b_2_2') # size = (28,28,192)
layer_3b_3_1 = tf.nn.relu(conv2d(layer_3a, kernel_3b_3_1, [1,1,1,1], name = 'conv_layer_3b_3_1') + bias_3b_3_1, name = 'layer_3b_3_1') # size = (28,28,32)
layer_3b_3_2 = tf.nn.relu(conv2d(layer_3b_3_1, kernel_3b_3_2, [1,1,1,1], name = 'conv_layer_3b_3_2') + bias_3b_3_2, name = 'layer_3b_3_2') # size = (28,28,96)
max_pool_3b_1 = tf.nn.max_pool(layer_3a, ksize=[1,3,3,1], strides=[1,1,1,1], padding="SAME", name='maxpool_3b_1') # size = (28,28,256)
layer_3b_4 = tf.nn.relu(conv2d(max_pool_3b_1, kernel_3b_4, [1,1,1,1], name = 'conv_layer_3b_4') + bias_3b_4, name = 'layer_3b_4') # size = (28,28,64)
layer_3b = tf.concat([layer_3b_1, layer_3b_2_2, layer_3b_3_2, layer_3b_4], 3) # size = (28,28,480)
# Part4
MaxPool_4 = tf.nn.max_pool(layer_3b, ksize=[1,3,3,1], strides=[1,2,2,1], padding="SAME", name='MaxPool_5') # size = (14,14,480)
# Part4a
kernel_4a_1 = weight_variable([1,1,480,192], name = 'kernel_4a_1')
kernel_4a_2_1 = weight_variable([1,1,480,96], name = 'kernel_4a_2_1')
kernel_4a_2_2 = weight_variable([3,3,96,208], name = 'kernel_4a_2_2')
kernel_4a_3_1 = weight_variable([1,1,480,16], name = 'kernel_4a_3_1')
kernel_4a_3_2 = weight_variable([5,5,16,48], name = 'kernel_4a_3_2')
kernel_4a_4 = weight_variable([1,1,480,64], name = 'kernel_4a_4')
bias_4a_1 = bias_variable([192], name = 'bias_4a_1')
bias_4a_2_1 = bias_variable([96], name = 'bias_4a_2_1')
bias_4a_2_2 = bias_variable([208], name = 'bias_4a_2_2')
bias_4a_3_1 = bias_variable([16], name = 'bias_4a_3_1')
bias_4a_3_2 = bias_variable([48], name = 'bias_4a_3_2')
bias_4a_4 = bias_variable([64], name = 'bias_4a_4')
layer_4a_1 = tf.nn.relu(conv2d(MaxPool_4, kernel_4a_1, [1,1,1,1], name = 'conv_layer_4a_1') + bias_4a_1, name = 'layer_4a_1') # size = (14,14,192)
layer_4a_2_1 = tf.nn.relu(conv2d(MaxPool_4, kernel_4a_2_1, [1,1,1,1], name = 'conv_layer_4a_2_1') + bias_4a_2_1, name = 'layer_4a_2_1') # size = (14,14,96)
layer_4a_2_2 = tf.nn.relu(conv2d(layer_4a_2_1, kernel_4a_2_2, [1,1,1,1], name = 'conv_layer_4a_2_2') + bias_4a_2_2, name = 'layer_4a_2_2') # size = (14,14,208)
layer_4a_3_1 = tf.nn.relu(conv2d(MaxPool_4, kernel_4a_3_1, [1,1,1,1], name = 'conv_layer_4a_3_1') + bias_4a_3_1, name = 'layer_4a_3_1') # size = (14,14,16)
layer_4a_3_2 = tf.nn.relu(conv2d(layer_4a_3_1, kernel_4a_3_2, [1,1,1,1], name = 'conv_layer_4a_3_2') + bias_4a_3_2, name = 'layer_4a_3_2') # size = (14,14,48)
max_pool_4a_1 = tf.nn.max_pool(MaxPool_4, ksize=[1,3,3,1], strides=[1,1,1,1], padding="SAME", name='maxpool_4a_1') # size = (14,14,480)
layer_4a_4 = tf.nn.relu(conv2d(max_pool_4a_1, kernel_4a_4, [1,1,1,1], name = 'conv_layer_4a_4') + bias_4a_4, name = 'layer_4a_4') # size = (14,14,64)
layer_4a = tf.concat([layer_4a_1, layer_4a_2_2, layer_4a_3_2, layer_4a_4], 3) # size = (14,14,512)
# Part4b
kernel_4b_1 = weight_variable([1,1,512,160], name = 'kernel_4b_1')
kernel_4b_2_1 = weight_variable([1,1,512,112], name = 'kernel_4b_2_1')
kernel_4b_2_2 = weight_variable([3,3,112,224], name = 'kernel_4b_2_2')
kernel_4b_3_1 = weight_variable([1,1,512,24], name = 'kernel_4b_3_1')
kernel_4b_3_2 = weight_variable([5,5,24,64], name = 'kernel_4b_3_2')
kernel_4b_4 = weight_variable([1,1,512,64], name = 'kernel_4b_4')
bias_4b_1 = bias_variable([160], name = 'bias_4b_1')
bias_4b_2_1 = bias_variable([112], name = 'bias_4b_2_1')
bias_4b_2_2 = bias_variable([224], name = 'bias_4b_2_2')
bias_4b_3_1 = bias_variable([24], name = 'bias_4b_3_1')
bias_4b_3_2 = bias_variable([64], name = 'bias_4b_3_2')
bias_4b_4 = bias_variable([64], name = 'bias_4b_4')
layer_4b_1 = tf.nn.relu(conv2d(layer_4a, kernel_4b_1, [1,1,1,1], name = 'conv_layer_4b_1') + bias_4b_1, name = 'layer_4b_1') # size = (14,14,160)
layer_4b_2_1 = tf.nn.relu(conv2d(layer_4a, kernel_4b_2_1, [1,1,1,1], name = 'conv_layer_4b_2_1') + bias_4b_2_1, name = 'layer_4b_2_1') # size = (14,14,112)
layer_4b_2_2 = tf.nn.relu(conv2d(layer_4b_2_1, kernel_4b_2_2, [1,1,1,1], name = 'conv_layer_4b_2_2') + bias_4b_2_2, name = 'layer_4b_2_2') # size = (14,14,224)
layer_4b_3_1 = tf.nn.relu(conv2d(layer_4a, kernel_4b_3_1, [1,1,1,1], name = 'conv_layer_4b_3_1') + bias_4b_3_1, name = 'layer_4b_3_1') # size = (14,14,24)
layer_4b_3_2 = tf.nn.relu(conv2d(layer_4b_3_1, kernel_4b_3_2, [1,1,1,1], name = 'conv_layer_4b_3_2') + bias_4b_3_2, name = 'layer_4b_3_2') # size = (14,14,64)
max_pool_4b_1 = tf.nn.max_pool(layer_4a, ksize=[1,3,3,1], strides=[1,1,1,1], padding="SAME", name='maxpool_4b_1') # size = (14,14,512)
layer_4b_4 = tf.nn.relu(conv2d(max_pool_4b_1, kernel_4b_4, [1,1,1,1], name = 'conv_layer_4b_4') + bias_4b_4, name = 'layer_4b_4') # size = (14,14,64)
layer_4b = tf.concat([layer_4b_1, layer_4b_2_2, layer_4b_3_2, layer_4b_4], 3) # size = (14,14,512)
# Part4c
kernel_4c_1 = weight_variable([1,1,512,128], name = 'kernel_4c_1')
kernel_4c_2_1 = weight_variable([1,1,512,128], name = 'kernel_4c_2_1')
kernel_4c_2_2 = weight_variable([3,3,128,256], name = 'kernel_4c_2_2')
kernel_4c_3_1 = weight_variable([1,1,512,24], name = 'kernel_4c_3_1')
kernel_4c_3_2 = weight_variable([5,5,24,64], name = 'kernel_4c_3_2')
kernel_4c_4 = weight_variable([1,1,512,64], name = 'kernel_4c_4')
bias_4c_1 = bias_variable([128], name = 'bias_4c_1')
bias_4c_2_1 = bias_variable([128], name = 'bias_4c_2_1')
bias_4c_2_2 = bias_variable([256], name = 'bias_4c_2_2')
bias_4c_3_1 = bias_variable([24], name = 'bias_4c_3_1')
bias_4c_3_2 = bias_variable([64], name = 'bias_4c_3_2')
bias_4c_4 = bias_variable([64], name = 'bias_4c_4')
layer_4c_1 = tf.nn.relu(conv2d(layer_4b, kernel_4c_1, [1,1,1,1], name = 'conv_layer_4c_1') + bias_4c_1, name = 'layer_4c_1') # size = (14,14,128)
layer_4c_2_1 = tf.nn.relu(conv2d(layer_4b, kernel_4c_2_1, [1,1,1,1], name = 'conv_layer_4c_2_1') + bias_4c_2_1, name = 'layer_4c_2_1') # size = (14,14,128)
layer_4c_2_2 = tf.nn.relu(conv2d(layer_4c_2_1, kernel_4c_2_2, [1,1,1,1], name = 'conv_layer_4c_2_2') + bias_4c_2_2, name = 'layer_4c_2_2') # size = (14,14,256)
layer_4c_3_1 = tf.nn.relu(conv2d(layer_4b, kernel_4c_3_1, [1,1,1,1], name = 'conv_layer_4c_3_1') + bias_4c_3_1, name = 'layer_4c_3_1') # size = (14,14,24)
layer_4c_3_2 = tf.nn.relu(conv2d(layer_4c_3_1, kernel_4c_3_2, [1,1,1,1], name = 'conv_layer_4c_3_2') + bias_4c_3_2, name = 'layer_4c_3_2') # size = (14,14,64)
max_pool_4c_1 = tf.nn.max_pool(layer_4b, ksize=[1,3,3,1], strides=[1,1,1,1], padding="SAME", name='maxpool_4c_1') # size = (14,14,512)
layer_4c_4 = tf.nn.relu(conv2d(max_pool_4c_1, kernel_4c_4, [1,1,1,1], name = 'conv_layer_4c_4') + bias_4c_4, name = 'layer_4c_4') # size = (14,14,64)
layer_4c = tf.concat([layer_4c_1, layer_4c_2_2, layer_4c_3_2, layer_4c_4], 3) # size = (14,14,512)
# Part4d
kernel_4d_1 = weight_variable([1,1,512,112], name = 'kernel_4d_1')
kernel_4d_2_1 = weight_variable([1,1,512,144], name = 'kernel_4d_2_1')
kernel_4d_2_2 = weight_variable([3,3,144,288], name = 'kernel_4d_2_2')
kernel_4d_3_1 = weight_variable([1,1,512,32], name = 'kernel_4d_3_1')
kernel_4d_3_2 = weight_variable([5,5,32,64], name = 'kernel_4d_3_2')
kernel_4d_4 = weight_variable([1,1,512,64], name = 'kernel_4d_4')
bias_4d_1 = bias_variable([112], name = 'bias_4d_1')
bias_4d_2_1 = bias_variable([144], name = 'bias_4d_2_1')
bias_4d_2_2 = bias_variable([288], name = 'bias_4d_2_2')
bias_4d_3_1 = bias_variable([32], name = 'bias_4d_3_1')
bias_4d_3_2 = bias_variable([64], name = 'bias_4d_3_2')
bias_4d_4 = bias_variable([64], name = 'bias_4d_4')
layer_4d_1 = tf.nn.relu(conv2d(layer_4c, kernel_4d_1, [1,1,1,1], name = 'conv_layer_4d_1') + bias_4d_1, name = 'layer_4d_1') # size = (14,14,112)
layer_4d_2_1 = tf.nn.relu(conv2d(layer_4c, kernel_4d_2_1, [1,1,1,1], name = 'conv_layer_4d_2_1') + bias_4d_2_1, name = 'layer_4d_2_1') # size = (14,14,144)
layer_4d_2_2 = tf.nn.relu(conv2d(layer_4d_2_1, kernel_4d_2_2, [1,1,1,1], name = 'conv_layer_4d_2_2') + bias_4d_2_2, name = 'layer_4d_2_2') # size = (14,14,288)
layer_4d_3_1 = tf.nn.relu(conv2d(layer_4c, kernel_4d_3_1, [1,1,1,1], name = 'conv_layer_4d_3_1') + bias_4d_3_1, name = 'layer_4d_3_1') # size = (14,14,32)
layer_4d_3_2 = tf.nn.relu(conv2d(layer_4d_3_1, kernel_4d_3_2, [1,1,1,1], name = 'conv_layer_4d_3_2') + bias_4d_3_2, name = 'layer_4d_3_2') # size = (14,14,64)
max_pool_4d_1 = tf.nn.max_pool(layer_4c, ksize=[1,3,3,1], strides=[1,1,1,1], padding="SAME", name='maxpool_4d_1') # size = (14,14,512)
layer_4d_4 = tf.nn.relu(conv2d(max_pool_4d_1, kernel_4d_4, [1,1,1,1], name = 'conv_layer_4d_4') + bias_4d_4, name = 'layer_4d_4') # size = (14,14,64)
layer_4d = tf.concat([layer_4d_1, layer_4d_2_2, layer_4d_3_2, layer_4d_4], 3) # size = (14,14,528)
# Part4e
kernel_4e_1 = weight_variable([1,1,528,256], name = 'kernel_4e_1')
kernel_4e_2_1 = weight_variable([1,1,528,160], name = 'kernel_4e_2_1')
kernel_4e_2_2 = weight_variable([3,3,160,320], name = 'kernel_4e_2_2')
kernel_4e_3_1 = weight_variable([1,1,528,32], name = 'kernel_4e_3_1')
kernel_4e_3_2 = weight_variable([5,5,32,128], name = 'kernel_4e_3_2')
kernel_4e_4 = weight_variable([1,1,528,128], name = 'kernel_4e_4')
bias_4e_1 = bias_variable([256], name = 'bias_4e_1')
bias_4e_2_1 = bias_variable([160], name = 'bias_4e_2_1')
bias_4e_2_2 = bias_variable([320], name = 'bias_4e_2_2')
bias_4e_3_1 = bias_variable([32], name = 'bias_4e_3_1')
bias_4e_3_2 = bias_variable([128], name = 'bias_4e_3_2')
bias_4e_4 = bias_variable([128], name = 'bias_4e_4')
layer_4e_1 = tf.nn.relu(conv2d(layer_4d, kernel_4e_1, [1,1,1,1], name = 'conv_layer_4e_1') + bias_4e_1, name = 'layer_4e_1') # size = (14,14,256)
layer_4e_2_1 = tf.nn.relu(conv2d(layer_4d, kernel_4e_2_1, [1,1,1,1], name = 'conv_layer_4e_2_1') + bias_4e_2_1, name = 'layer_4e_2_1') # size = (14,14,160)
layer_4e_2_2 = tf.nn.relu(conv2d(layer_4e_2_1, kernel_4e_2_2, [1,1,1,1], name = 'conv_layer_4e_2_2') + bias_4e_2_2, name = 'layer_4e_2_2') # size = (14,14,320)
layer_4e_3_1 = tf.nn.relu(conv2d(layer_4d, kernel_4e_3_1, [1,1,1,1], name = 'conv_layer_4e_3_1') + bias_4e_3_1, name = 'layer_4e_3_1') # size = (14,14,32)
layer_4e_3_2 = tf.nn.relu(conv2d(layer_4e_3_1, kernel_4e_3_2, [1,1,1,1], name = 'conv_layer_4e_3_2') + bias_4e_3_2, name = 'layer_4e_3_2') # size = (14,14,128)
max_pool_4e_1 = tf.nn.max_pool(layer_4d, ksize=[1,3,3,1], strides=[1,1,1,1], padding="SAME", name='maxpool_4e_1') # size = (14,14,528)
layer_4e_4 = tf.nn.relu(conv2d(max_pool_4e_1, kernel_4e_4, [1,1,1,1], name = 'conv_layer_4e_4') + bias_4e_4, name = 'layer_4e_4') # size = (14,14,128)
layer_4e = tf.concat([layer_4e_1, layer_4e_2_2, layer_4e_3_2, layer_4e_4], 3) # size = (14,14,832)
# Part5
MaxPool_5 = tf.nn.max_pool(layer_4e, ksize=[1,3,3,1], strides=[1,2,2,1], padding="SAME", name='MaxPool_5') # size = (7,7,832)
# Part5a
kernel_5a_1 = weight_variable([1,1,832,256], name = 'kernel_5a_1')
kernel_5a_2_1 = weight_variable([1,1,832,160], name = 'kernel_5a_2_1')
kernel_5a_2_2 = weight_variable([3,3,160,320], name = 'kernel_5a_2_2')
kernel_5a_3_1 = weight_variable([1,1,832,32], name = 'kernel_5a_3_1')
kernel_5a_3_2 = weight_variable([5,5,32,128], name = 'kernel_5a_3_2')
kernel_5a_4 = weight_variable([1,1,832,128], name = 'kernel_5a_4')
bias_5a_1 = bias_variable([256], name = 'bias_5a_1')
bias_5a_2_1 = bias_variable([160], name = 'bias_5a_2_1')
bias_5a_2_2 = bias_variable([320], name = 'bias_5a_2_2')
bias_5a_3_1 = bias_variable([32], name = 'bias_5a_3_1')
bias_5a_3_2 = bias_variable([128], name = 'bias_5a_3_2')
bias_5a_4 = bias_variable([128], name = 'bias_5a_4')
layer_5a_1 = tf.nn.relu(conv2d(MaxPool_5, kernel_5a_1, [1,1,1,1], name = 'conv_layer_5a_1') + bias_5a_1, name = 'layer_5a_1') # size = (7,7,256)
layer_5a_2_1 = tf.nn.relu(conv2d(MaxPool_5, kernel_5a_2_1, [1,1,1,1], name = 'conv_layer_5a_2_1') + bias_5a_2_1, name = 'layer_5a_2_1') # size = (7,7,160)
layer_5a_2_2 = tf.nn.relu(conv2d(layer_5a_2_1, kernel_5a_2_2, [1,1,1,1], name = 'conv_layer_5a_2_2') + bias_5a_2_2, name = 'layer_5a_2_2') # size = (7,7,320)
layer_5a_3_1 = tf.nn.relu(conv2d(MaxPool_5, kernel_5a_3_1, [1,1,1,1], name = 'conv_layer_5a_3_1') + bias_5a_3_1, name = 'layer_5a_3_1') # size = (7,7,32)
layer_5a_3_2 = tf.nn.relu(conv2d(layer_5a_3_1, kernel_5a_3_2, [1,1,1,1], name = 'conv_layer_5a_3_2') + bias_5a_3_2, name = 'layer_5a_3_2') # size = (7,7,128)
max_pool_5a_1 = tf.nn.max_pool(MaxPool_5, ksize=[1,3,3,1], strides=[1,1,1,1], padding="SAME", name='maxpool_5a_1') # size = (7,7,832)
layer_5a_4 = tf.nn.relu(conv2d(max_pool_5a_1, kernel_5a_4, [1,1,1,1], name = 'conv_layer_5a_4') + bias_5a_4, name = 'layer_5a_4') # size = (7,7,128)
layer_5a = tf.concat([layer_5a_1, layer_5a_2_2, layer_5a_3_2, layer_5a_4], 3) # size = (7,7,832)
# Part5b
kernel_5b_1 = weight_variable([1,1,832,384], name = 'kernel_5b_1')
kernel_5b_2_1 = weight_variable([1,1,832,192], name = 'kernel_5b_2_1')
kernel_5b_2_2 = weight_variable([3,3,192,384], name = 'kernel_5b_2_2')
kernel_5b_3_1 = weight_variable([1,1,832,48], name = 'kernel_5b_3_1')
kernel_5b_3_2 = weight_variable([5,5,48,128], name = 'kernel_5b_3_2')
kernel_5b_4 = weight_variable([1,1,832,128], name = 'kernel_5b_4')
bias_5b_1 = bias_variable([384], name = 'bias_5b_1')
bias_5b_2_1 = bias_variable([192], name = 'bias_5b_2_1')
bias_5b_2_2 = bias_variable([384], name = 'bias_5b_2_2')
bias_5b_3_1 = bias_variable([48], name = 'bias_5b_3_1')
bias_5b_3_2 = bias_variable([128], name = 'bias_5b_3_2')
bias_5b_4 = bias_variable([128], name = 'bias_5b_4')
layer_5b_1 = tf.nn.relu(conv2d(layer_5a, kernel_5b_1, [1,1,1,1], name = 'conv_layer_5b_1') + bias_5b_1, name = 'layer_5b_1') # size = (7,7,384)
layer_5b_2_1 = tf.nn.relu(conv2d(layer_5a, kernel_5b_2_1, [1,1,1,1], name = 'conv_layer_5b_2_1') + bias_5b_2_1, name = 'layer_5b_2_1') # size = (7,7,192)
layer_5b_2_2 = tf.nn.relu(conv2d(layer_5b_2_1, kernel_5b_2_2, [1,1,1,1], name = 'conv_layer_5b_2_2') + bias_5b_2_2, name = 'layer_5b_2_2') # size = (7,7,384)
layer_5b_3_1 = tf.nn.relu(conv2d(layer_5a, kernel_5b_3_1, [1,1,1,1], name = 'conv_layer_5b_3_1') + bias_5b_3_1, name = 'layer_5b_3_1') # size = (7,7,48)
layer_5b_3_2 = tf.nn.relu(conv2d(layer_5b_3_1, kernel_5b_3_2, [1,1,1,1], name = 'conv_layer_5b_3_2') + bias_5b_3_2, name = 'layer_5b_3_2') # size = (7,7,128)
max_pool_5b_1 = tf.nn.max_pool(layer_5a, ksize=[1,3,3,1], strides=[1,1,1,1], padding="SAME", name='maxpool_5b_1') # size = (7,7,832)
layer_5b_4 = tf.nn.relu(conv2d(max_pool_5b_1, kernel_5b_4, [1,1,1,1], name = 'conv_layer_5b_4') + bias_5b_4, name = 'layer_5b_4') # size = (7,7,128)
layer_5b = tf.concat([layer_5b_1, layer_5b_2_2, layer_5b_3_2, layer_5b_4], 3) # size = (7,7,1024)
# Softmax_assist_0
Avg_assist_0 = tf.nn.avg_pool(layer_4a, ksize=[1,5,5,1], strides=[1,3,3,1], padding="VALID", name='Avg') # size = (4,4,512)
kernel_assist_0 = weight_variable([1,1,512,1024], name = 'kernel_assist_0')
bias_assist_0 = bias_variable([1024], name = 'bias_assist_0')
conv_layer_assist_0 = tf.nn.relu(conv2d(Avg_assist_0, kernel_assist_0, [1,1,1,1]) + bias_assist_0,name = 'conv_layer_assist_0') # size = (4,4,1024)
line_assist_0 = tf.reshape(conv_layer_assist_0, [-1, 16384])
fc_assist_0_weight_1 = weight_variable([16384,1000], name = 'fc_assist_0_weight_1')
fc_assist_0_bias_1 = bias_variable([1000], name = 'fc_assist_0_bias_1')
fc_assist_0_weight_2 = weight_variable([1000,1000], name = 'fc_assist_0_weight_2')
fc_assist_0_bias_2 = bias_variable([1000], name = 'fc_assist_0_bias_2')
layer_assist_0_dropout_1 = tf.nn.dropout(line_assist_0, keep_prob, name = 'layer_assist_0_dropout_1')
layer_assist_0_1 = tf.nn.relu(tf.matmul(layer_assist_0_dropout_1, fc_assist_0_weight_1, name = 'matmul_layer_assist_0_1') + fc_assist_0_bias_1, name = 'layer_assist_0_1')
layer_assist_0_dropout_2 = tf.nn.dropout(layer_assist_0_1, keep_prob, name = 'layer_assist_0_dropout_2')
layer_assist_0_2 = tf.nn.relu(tf.matmul(layer_assist_0_dropout_2, fc_assist_0_weight_2, name = 'matmul_layer_assist_0_2') + fc_assist_0_bias_2, name = 'layer_assist_0_2')
output_assist_0 = tf.nn.softmax(layer_assist_0_2, name = 'output_assist_0')
# Softmax_assist_1
Avg_assist_1 = tf.nn.avg_pool(layer_4d, ksize=[1,5,5,1], strides=[1,3,3,1], padding="VALID", name='Avg') # size = (4,4,528)
kernel_assist_1 = weight_variable([1,1,528,1024], name = 'kernel_assist_1')
bias_assist_1 = bias_variable([1024], name = 'bias_assist_1')
conv_layer_assist_1 = tf.nn.relu(conv2d(Avg_assist_1, kernel_assist_1, [1,1,1,1]) + bias_assist_1,name = 'conv_layer_assist_1') # size = (4,4,1024)
line_assist_1 = tf.reshape(conv_layer_assist_1, [-1, 16384])
fc_assist_1_weight_1 = weight_variable([16384,1000], name = 'fc_assist_1_weight_1')
fc_assist_1_bias_1 = bias_variable([1000], name = 'fc_assist_1_bias_1')
fc_assist_1_weight_2 = weight_variable([1000,1000], name = 'fc_assist_1_weight_2')
fc_assist_1_bias_2 = bias_variable([1000], name = 'fc_assist_1_bias_2')
layer_assist_1_dropout_1 = tf.nn.dropout(line_assist_1, keep_prob, name = 'layer_assist_1_dropout_1')
layer_assist_1_1 = tf.nn.relu(tf.matmul(layer_assist_1_dropout_1, fc_assist_1_weight_1, name = 'matmul_layer_assist_1_1') + fc_assist_1_bias_1, name = 'layer_assist_1_1')
layer_assist_1_dropout_2 = tf.nn.dropout(layer_assist_1_1, keep_prob, name = 'layer_assist_1_dropout_2')
layer_assist_1_2 = tf.nn.relu(tf.matmul(layer_assist_1_dropout_2, fc_assist_1_weight_2, name = 'matmul_layer_assist_1_2') + fc_assist_1_bias_2, name = 'layer_assist_1_2')
output_assist_1 = tf.nn.softmax(layer_assist_1_2, name = 'output_assist_1')
# Softmax
Avg = tf.nn.avg_pool(layer_5b, ksize=[1,7,7,1], strides=[1,1,1,1], padding="VALID", name='Avg') # size = (1,1,1024)
line = tf.reshape(Avg, [-1, 1024])
fc_weight = weight_variable([1024,1000], name = 'fc_weight')
fc_bias = bias_variable([1000], name = 'fc_bias')
layer_dropout = tf.nn.dropout(line, keep_prob, name = 'layer_dropout')
layer = tf.nn.relu(tf.matmul(layer_dropout, fc_weight, name = 'matmul_layer') + fc_bias, name = 'layer')
output = tf.nn.softmax(layer, name = 'output')
return output, output_assist_0, output_assist_1
def backward(datasets, label, test_data, test_label):
X = tf.placeholder(tf.float32, [None, 224,224,3], name = "Input")
Y_ = tf.placeholder(tf.float32, [None, 1], name = 'Estimation')
LEARNING_RATE_BASE = 0.0001 # 最初学习率
LEARNING_RATE_DECAY = 0.99 # 学习率的衰减率
LEARNING_RATE_STEP = 1000 # 喂入多少轮BATCH-SIZE以后,更新一次学习率。一般为总样本数量/BATCH_SIZE
gloabl_steps = tf.Variable(0, trainable=False) # 计数器,用来记录运行了几轮的BATCH_SIZE,初始为0,设置为不可训练
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, gloabl_steps, LEARNING_RATE_STEP, LEARNING_RATE_DECAY, staircase=True)
keep_prob = tf.placeholder(tf.float32, name = "keep_prob")
y = GoogLeNet_v1(X)
global_step = tf.Variable(0, trainable=False)
loss_mse = tf.reduce_mean(-tf.reduce_sum(Y_ * tf.log(y), reduction_indices=[1]))
# loss_mse = tf.reduce_mean(tf.square(y-Y_))
# train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss_mse)
# train_step=tf.train.MomentumOptimizer(0.001,0.9).minimize(loss_mse) #其他方法
train_step=tf.train.AdamOptimizer(0.001).minimize(loss_mse)
saver = tf.train.Saver()
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
# 训练模型。
STEPS = 500001
min_loss = 1
for i in range(STEPS):
start = (i*BATCH_SIZE) % 862
end = start + BATCH_SIZE
sess.run(train_step, feed_dict={X: datasets[start:end], Y_: label[start:end]})
if i % 100 == 0:
train_loss = sess.run(loss_mse, feed_dict={X: datasets, Y_: label, keep_prob:1})
total_loss = sess.run(loss_mse, feed_dict={X: test_data, Y_: test_label, keep_prob:1})
if total_loss < min_loss:
min_loss = total_loss
f = open('./text/loss.txt', 'a')
f.write("After %d training step(s), loss_mse on train data is %g, loss_mse on val data is %g, min_loss is %g\n" % (i, train_loss, total_loss, min_loss))
print("After %d training step(s), loss_mse on train data is %g, loss_mse on val data is %g, min_loss is %g" % (i, train_loss, total_loss, min_loss))
f.close()
if i % 10000 == 0:
saver.save(sess, './checkpoint/variable', global_step = i)
def main():
# datasets, label, test_data, test_label = reload_all_data()
datasets, label, test_data, test_label = Sequential_disruption()
backward(datasets, label, test_data, test_label)
if __name__ == '__main__':
main()
建议在inception这一块可以写一个函数,主要控制每个卷积核的个数,我这里为了直观就每写。
demo不能直接运行,如果要运行请修改最后一个main函数里面的代码段,直接把训练集和val集输入到background就行。这里输入一定是224*224*3的矩阵,输出是1000个的标签,如果想减小请在最后一个softmax区域把输出向量长度改小。
虽然有3个辅助分类器,最后输出三个,但是可以直接选择其中的一个,而不是3个共同训练。
这里再给出可视化demo:
import tensorflow as tf
# REGULARIZER = 0.01
BATCH_SIZE = 10
def weight_variable(shape, name=None):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial, name)
def bias_variable(shape, name=None):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial, name)
def conv2d(input, filter, strides, padding="SAME", name=None):
# filters with shape [filter_height * filter_width * in_channels, output_channels]
# Must have strides[0] = strides[3] =1
# For the most common case of the same horizontal and vertices strides, strides = [1, stride, stride, 1]
'''
Args:
input: A Tensor. Must be one of the following types: float32, float64.
filter: A Tensor. Must have the same type as input.
strides: A list of ints. 1-D of length 4. The stride of the sliding window for each dimension of input.
padding: A string from: "SAME", "VALID". The type of padding algorithm to use.
use_cudnn_on_gpu: An optional bool. Defaults to True.
name: A name for the operation (optional).
'''
return tf.nn.conv2d(input, filter, strides, padding="SAME", name=name) # padding="SAME"用零填充边界
def GoogLeNet_v1(input, keep_prob=0.4):
'''参考论文: Going deeper with convolutions'''
# input_size:(224,224,3)
# Part1
with tf.name_scope('Conv_7x7'):
kernel_1 = weight_variable([7, 7, 3, 64], name='kernel_1')
bias_1 = bias_variable([64], name='bias_1')
conv_layer_1 = conv2d(input, kernel_1, [1, 2, 2, 1], name='conv_layer_1') + bias_1 # size = (112,112,64)
layer_1 = tf.nn.relu(conv_layer_1, name='layer_1') # size = (112,112,64)
with tf.name_scope('MaxPool_1'):
maxpool_1 = tf.nn.max_pool(layer_1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding="SAME",
name='maxpool_1') # size = (56,56,64)
with tf.name_scope('LocalRespNorm_1'):
LocalRespNorm_1 = tf.nn.local_response_normalization(maxpool_1, name='LocalRespNorm_1') # size = (56,56,64)
# Part2
with tf.name_scope('Conv_1x1'):
kernel_2_reduce = weight_variable([1, 1, 64, 64], name='kernel_2_reduce')
bias_2_reduce = bias_variable([64], name='bias_2_reduce')
conv_layer_2_reduce = conv2d(LocalRespNorm_1, kernel_2_reduce, [1, 1, 1, 1], padding='VALID',
name='conv_layer_2_reduce') + bias_2_reduce # size = (56,56,64) 这里的padding不确定是不是SAME,论文上可能是VALID
layer_2_reduce = tf.nn.relu(conv_layer_2_reduce, name='layer_2_reduce') # size = (56,56,64)
with tf.name_scope('Conv_3x3'):
kernel_2 = weight_variable([3, 3, 64, 192], name='kernel_2')
bias_2 = bias_variable([192], name='bias_2')
conv_layer_2 = conv2d(layer_2_reduce, kernel_2, [1, 1, 1, 1], name='conv_layer_2') + bias_2 # size = (56,56,192)
layer_2 = tf.nn.relu(conv_layer_2, name='layer_2') # size = (56,56,192)
with tf.name_scope('LocalRespNorm_2'):
LocalRespNorm_2 = tf.nn.local_response_normalization(layer_2, name='LocalRespNorm_2') # size = (56,56,192)
with tf.name_scope('MaxPool_2'):
max_pool_2 = tf.nn.max_pool(LocalRespNorm_2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding="SAME",
name='maxpool_2') # size = (28,28,192)
# Part3a
with tf.name_scope('inception_3a'):
with tf.name_scope('Part1'):
kernel_3a_1 = weight_variable([1, 1, 192, 64], name='kernel_3a_1')
bias_3a_1 = bias_variable([64], name='bias_3a_1')
with tf.name_scope('conv1x1'):
layer_3a_1 = tf.nn.relu(conv2d(max_pool_2, kernel_3a_1, [1, 1, 1, 1], name='conv_layer_3a_1') + bias_3a_1,
name='layer_3a_1') # size = (28,28,64)
with tf.name_scope('Part2'):
kernel_3a_2_1 = weight_variable([1, 1, 192, 96], name='kernel_3a_2_1')
bias_3a_2_1 = bias_variable([96], name='bias_3a_2_1')
kernel_3a_2_2 = weight_variable([3, 3, 96, 128], name='kernel_3a_2_2')
bias_3a_2_2 = bias_variable([128], name='bias_3a_2_2')
with tf.name_scope('conv1x1'):
layer_3a_2_1 = tf.nn.relu(
conv2d(max_pool_2, kernel_3a_2_1, [1, 1, 1, 1], name='conv_layer_3a_2_1') + bias_3a_2_1,
name='layer_3a_2_1') # size = (28,28,96)
with tf.name_scope('conv3x3'):
layer_3a_2_2 = tf.nn.relu(
conv2d(layer_3a_2_1, kernel_3a_2_2, [1, 1, 1, 1], name='conv_layer_3a_2_2') + bias_3a_2_2,
name='layer_3a_2_2') # size = (28,28,128)
with tf.name_scope('Part3'):
kernel_3a_3_1 = weight_variable([1, 1, 192, 16], name='kernel_3a_3_1')
bias_3a_3_1 = bias_variable([16], name='bias_3a_3_1')
kernel_3a_3_2 = weight_variable([5, 5, 16, 32], name='kernel_3a_3_2')
bias_3a_3_2 = bias_variable([32], name='bias_3a_3_2')
with tf.name_scope('conv1x1'):
layer_3a_3_1 = tf.nn.relu(
conv2d(max_pool_2, kernel_3a_3_1, [1, 1, 1, 1], name='conv_layer_3a_3_1') + bias_3a_3_1,
name='layer_3a_3_1') # size = (28,28,16)
with tf.name_scope('conv5x5'):
layer_3a_3_2 = tf.nn.relu(
conv2d(layer_3a_3_1, kernel_3a_3_2, [1, 1, 1, 1], name='conv_layer_3a_3_2') + bias_3a_3_2,
name='layer_3a_3_2') # size = (28,28,32)
with tf.name_scope('Part4'):
kernel_3a_4 = weight_variable([1, 1, 192, 32], name='kernel_3a_4')
bias_3a_4 = bias_variable([32], name='bias_3a_4')
with tf.name_scope('MaxPool_3x3'):
max_pool_3a_1 = tf.nn.max_pool(max_pool_2, ksize=[1, 3, 3, 1], strides=[1, 1, 1, 1], padding="SAME",
name='maxpool_3a_1') # size = (28,28,192)
with tf.name_scope('conv1x1'):
layer_3a_4 = tf.nn.relu(conv2d(max_pool_3a_1, kernel_3a_4, [1, 1, 1, 1], name='conv_layer_3a_4') + bias_3a_4,
name='layer_3a_4') # size = (28,28,32)
with tf.name_scope('DepthConcat'):
layer_3a = tf.concat([layer_3a_1, layer_3a_2_2, layer_3a_3_2, layer_3a_4], 3) # size = (28,28,256)
# Part3b
with tf.name_scope('inception_3b'):
with tf.name_scope('Part1'):
kernel_3b_1 = weight_variable([1, 1, 256, 128], name='kernel_3b_1')
bias_3b_1 = bias_variable([128], name='bias_3b_1')
with tf.name_scope('conv1x1'):
layer_3b_1 = tf.nn.relu(conv2d(layer_3a, kernel_3b_1, [1, 1, 1, 1], name='conv_layer_3b_1') + bias_3b_1,
name='layer_3b_1') # size = (28,28,128)
with tf.name_scope('Part2'):
kernel_3b_2_1 = weight_variable([1, 1, 256, 128], name='kernel_3b_2_1')
bias_3b_2_1 = bias_variable([128], name='bias_3b_2_1')
kernel_3b_2_2 = weight_variable([3, 3, 128, 192], name='kernel_3b_2_2')
bias_3b_2_2 = bias_variable([192], name='bias_3b_2_2')
with tf.name_scope('conv1x1'):
layer_3b_2_1 = tf.nn.relu(conv2d(layer_3a, kernel_3b_2_1, [1, 1, 1, 1], name='conv_layer_3b_2_1') + bias_3b_2_1,
name='layer_3b_2_1') # size = (28,28,128)
with tf.name_scope('conv3x3'):
layer_3b_2_2 = tf.nn.relu(
conv2d(layer_3b_2_1, kernel_3b_2_2, [1, 1, 1, 1], name='conv_layer_3b_2_2') + bias_3b_2_2,
name='layer_3b_2_2') # size = (28,28,192)
with tf.name_scope('Part3'):
kernel_3b_3_1 = weight_variable([1, 1, 256, 32], name='kernel_3b_3_1')
bias_3b_3_1 = bias_variable([32], name='bias_3b_3_1')
kernel_3b_3_2 = weight_variable([5, 5, 32, 96], name='kernel_3b_3_2')
bias_3b_3_2 = bias_variable([96], name='bias_3b_3_2')
with tf.name_scope('conv1x1'):
layer_3b_3_1 = tf.nn.relu(conv2d(layer_3a, kernel_3b_3_1, [1, 1, 1, 1], name='conv_layer_3b_3_1') + bias_3b_3_1,
name='layer_3b_3_1') # size = (28,28,32)
with tf.name_scope('conv5x5'):
layer_3b_3_2 = tf.nn.relu(
conv2d(layer_3b_3_1, kernel_3b_3_2, [1, 1, 1, 1], name='conv_layer_3b_3_2') + bias_3b_3_2,
name='layer_3b_3_2') # size = (28,28,96)
with tf.name_scope('Part4'):
kernel_3b_4 = weight_variable([1, 1, 256, 64], name='kernel_3b_4')
bias_3b_4 = bias_variable([64], name='bias_3b_4')
with tf.name_scope('MaxPool_3x3'):
max_pool_3b_1 = tf.nn.max_pool(layer_3a, ksize=[1, 3, 3, 1], strides=[1, 1, 1, 1], padding="SAME",
name='maxpool_3b_1') # size = (28,28,256)
with tf.name_scope('conv1x1'):
layer_3b_4 = tf.nn.relu(conv2d(max_pool_3b_1, kernel_3b_4, [1, 1, 1, 1], name='conv_layer_3b_4') + bias_3b_4,
name='layer_3b_4') # size = (28,28,64)
with tf.name_scope('DepthConcat'):
layer_3b = tf.concat([layer_3b_1, layer_3b_2_2, layer_3b_3_2, layer_3b_4], 3) # size = (28,28,480)
# Part4
with tf.name_scope('MaxPool_3'):
MaxPool_3 = tf.nn.max_pool(layer_3b, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding="SAME",
name='MaxPool_5') # size = (14,14,480)
# Part4a
with tf.name_scope('inception_4a'):
with tf.name_scope('Part1'):
kernel_4a_1 = weight_variable([1, 1, 480, 192], name='kernel_4a_1')
bias_4a_1 = bias_variable([192], name='bias_4a_1')
with tf.name_scope('conv1x1'):
layer_4a_1 = tf.nn.relu(conv2d(MaxPool_3, kernel_4a_1, [1, 1, 1, 1], name='conv_layer_4a_1') + bias_4a_1,
name='layer_4a_1') # size = (14,14,192)
with tf.name_scope('Part2'):
kernel_4a_2_1 = weight_variable([1, 1, 480, 96], name='kernel_4a_2_1')
bias_4a_2_1 = bias_variable([96], name='bias_4a_2_1')
kernel_4a_2_2 = weight_variable([3, 3, 96, 208], name='kernel_4a_2_2')
bias_4a_2_2 = bias_variable([208], name='bias_4a_2_2')
with tf.name_scope('conv1x1'):
layer_4a_2_1 = tf.nn.relu(
conv2d(MaxPool_3, kernel_4a_2_1, [1, 1, 1, 1], name='conv_layer_4a_2_1') + bias_4a_2_1,
name='layer_4a_2_1') # size = (14,14,96)
with tf.name_scope('conv3x3'):
layer_4a_2_2 = tf.nn.relu(
conv2d(layer_4a_2_1, kernel_4a_2_2, [1, 1, 1, 1], name='conv_layer_4a_2_2') + bias_4a_2_2,
name='layer_4a_2_2') # size = (14,14,208)
with tf.name_scope('Part3'):
kernel_4a_3_1 = weight_variable([1, 1, 480, 16], name='kernel_4a_3_1')
bias_4a_3_1 = bias_variable([16], name='bias_4a_3_1')
kernel_4a_3_2 = weight_variable([5, 5, 16, 48], name='kernel_4a_3_2')
bias_4a_3_2 = bias_variable([48], name='bias_4a_3_2')
with tf.name_scope('conv1x1'):
layer_4a_3_1 = tf.nn.relu(
conv2d(MaxPool_3, kernel_4a_3_1, [1, 1, 1, 1], name='conv_layer_4a_3_1') + bias_4a_3_1,
name='layer_4a_3_1') # size = (14,14,16)
with tf.name_scope('conv5x5'):
layer_4a_3_2 = tf.nn.relu(
conv2d(layer_4a_3_1, kernel_4a_3_2, [1, 1, 1, 1], name='conv_layer_4a_3_2') + bias_4a_3_2,
name='layer_4a_3_2') # size = (14,14,48)
with tf.name_scope('Part4'):
kernel_4a_4 = weight_variable([1, 1, 480, 64], name='kernel_4a_4')
bias_4a_4 = bias_variable([64], name='bias_4a_4')
with tf.name_scope('MaxPool_3x3'):
max_pool_4a_1 = tf.nn.max_pool(MaxPool_3, ksize=[1, 3, 3, 1], strides=[1, 1, 1, 1], padding="SAME",
name='maxpool_4a_1') # size = (14,14,480)
with tf.name_scope('conv1x1'):
layer_4a_4 = tf.nn.relu(conv2d(max_pool_4a_1, kernel_4a_4, [1, 1, 1, 1], name='conv_layer_4a_4') + bias_4a_4,
name='layer_4a_4') # size = (14,14,64)
with tf.name_scope('DepthConcat'):
layer_4a = tf.concat([layer_4a_1, layer_4a_2_2, layer_4a_3_2, layer_4a_4], 3) # size = (14,14,512)
# Part4b
with tf.name_scope('inception_4b'):
with tf.name_scope('Part1'):
kernel_4b_1 = weight_variable([1, 1, 512, 160], name='kernel_4b_1')
bias_4b_1 = bias_variable([160], name='bias_4b_1')
with tf.name_scope('conv1x1'):
layer_4b_1 = tf.nn.relu(conv2d(layer_4a, kernel_4b_1, [1, 1, 1, 1], name='conv_layer_4b_1') + bias_4b_1,
name='layer_4b_1') # size = (14,14,160)
with tf.name_scope('Part2'):
kernel_4b_2_1 = weight_variable([1, 1, 512, 112], name='kernel_4b_2_1')
bias_4b_2_1 = bias_variable([112], name='bias_4b_2_1')
kernel_4b_2_2 = weight_variable([3, 3, 112, 224], name='kernel_4b_2_2')
bias_4b_2_2 = bias_variable([224], name='bias_4b_2_2')
with tf.name_scope('conv1x1'):
layer_4b_2_1 = tf.nn.relu(conv2d(layer_4a, kernel_4b_2_1, [1, 1, 1, 1], name='conv_layer_4b_2_1') + bias_4b_2_1,
name='layer_4b_2_1') # size = (14,14,112)
with tf.name_scope('conv3x3'):
layer_4b_2_2 = tf.nn.relu(
conv2d(layer_4b_2_1, kernel_4b_2_2, [1, 1, 1, 1], name='conv_layer_4b_2_2') + bias_4b_2_2,
name='layer_4b_2_2') # size = (14,14,224)
with tf.name_scope('Part3'):
kernel_4b_3_1 = weight_variable([1, 1, 512, 24], name='kernel_4b_3_1')
bias_4b_3_1 = bias_variable([24], name='bias_4b_3_1')
kernel_4b_3_2 = weight_variable([5, 5, 24, 64], name='kernel_4b_3_2')
bias_4b_3_2 = bias_variable([64], name='bias_4b_3_2')
with tf.name_scope('conv1x1'):
layer_4b_3_1 = tf.nn.relu(conv2d(layer_4a, kernel_4b_3_1, [1, 1, 1, 1], name='conv_layer_4b_3_1') + bias_4b_3_1,
name='layer_4b_3_1') # size = (14,14,24)
with tf.name_scope('conv5x5'):
layer_4b_3_2 = tf.nn.relu(
conv2d(layer_4b_3_1, kernel_4b_3_2, [1, 1, 1, 1], name='conv_layer_4b_3_2') + bias_4b_3_2,
name='layer_4b_3_2') # size = (14,14,64)
with tf.name_scope('Part4'):
kernel_4b_4 = weight_variable([1, 1, 512, 64], name='kernel_4b_4')
bias_4b_4 = bias_variable([64], name='bias_4b_4')
with tf.name_scope('MaxPool_3x3'):
max_pool_4b_1 = tf.nn.max_pool(layer_4a, ksize=[1, 3, 3, 1], strides=[1, 1, 1, 1], padding="SAME",
name='maxpool_4b_1') # size = (14,14,512)
with tf.name_scope('conv1x1'):
layer_4b_4 = tf.nn.relu(conv2d(max_pool_4b_1, kernel_4b_4, [1, 1, 1, 1], name='conv_layer_4b_4') + bias_4b_4,
name='layer_4b_4') # size = (14,14,64)
with tf.name_scope('DepthConcat'):
layer_4b = tf.concat([layer_4b_1, layer_4b_2_2, layer_4b_3_2, layer_4b_4], 3) # size = (14,14,512)
# Part4c
with tf.name_scope('inception_4c'):
with tf.name_scope('Part1'):
kernel_4c_1 = weight_variable([1, 1, 512, 128], name='kernel_4c_1')
bias_4c_1 = bias_variable([128], name='bias_4c_1')
with tf.name_scope('conv1x1'):
layer_4c_1 = tf.nn.relu(conv2d(layer_4b, kernel_4c_1, [1, 1, 1, 1], name='conv_layer_4c_1') + bias_4c_1,
name='layer_4c_1') # size = (14,14,128)
with tf.name_scope('Part2'):
kernel_4c_2_1 = weight_variable([1, 1, 512, 128], name='kernel_4c_2_1')
bias_4c_2_1 = bias_variable([128], name='bias_4c_2_1')
kernel_4c_2_2 = weight_variable([3, 3, 128, 256], name='kernel_4c_2_2')
bias_4c_2_2 = bias_variable([256], name='bias_4c_2_2')
with tf.name_scope('conv1x1'):
layer_4c_2_1 = tf.nn.relu(conv2d(layer_4b, kernel_4c_2_1, [1, 1, 1, 1], name='conv_layer_4c_2_1') + bias_4c_2_1,
name='layer_4c_2_1') # size = (14,14,128)
with tf.name_scope('conv3x3'):
layer_4c_2_2 = tf.nn.relu(
conv2d(layer_4c_2_1, kernel_4c_2_2, [1, 1, 1, 1], name='conv_layer_4c_2_2') + bias_4c_2_2,
name='layer_4c_2_2') # size = (14,14,256)
with tf.name_scope('Part3'):
kernel_4c_3_1 = weight_variable([1, 1, 512, 24], name='kernel_4c_3_1')
bias_4c_3_1 = bias_variable([24], name='bias_4c_3_1')
kernel_4c_3_2 = weight_variable([5, 5, 24, 64], name='kernel_4c_3_2')
bias_4c_3_2 = bias_variable([64], name='bias_4c_3_2')
with tf.name_scope('conv1x1'):
layer_4c_3_1 = tf.nn.relu(conv2d(layer_4b, kernel_4c_3_1, [1, 1, 1, 1], name='conv_layer_4c_3_1') + bias_4c_3_1,
name='layer_4c_3_1') # size = (14,14,24)
with tf.name_scope('conv5x5'):
layer_4c_3_2 = tf.nn.relu(
conv2d(layer_4c_3_1, kernel_4c_3_2, [1, 1, 1, 1], name='conv_layer_4c_3_2') + bias_4c_3_2,
name='layer_4c_3_2') # size = (14,14,64)
with tf.name_scope('Part4'):
kernel_4c_4 = weight_variable([1, 1, 512, 64], name='kernel_4c_4')
bias_4c_4 = bias_variable([64], name='bias_4c_4')
with tf.name_scope('MaxPool_3x3'):
max_pool_4c_1 = tf.nn.max_pool(layer_4b, ksize=[1, 3, 3, 1], strides=[1, 1, 1, 1], padding="SAME",
name='maxpool_4c_1') # size = (14,14,512)
with tf.name_scope('conv1x1'):
layer_4c_4 = tf.nn.relu(conv2d(max_pool_4c_1, kernel_4c_4, [1, 1, 1, 1], name='conv_layer_4c_4') + bias_4c_4,
name='layer_4c_4') # size = (14,14,64)
with tf.name_scope('DepthConcat'):
layer_4c = tf.concat([layer_4c_1, layer_4c_2_2, layer_4c_3_2, layer_4c_4], 3) # size = (14,14,512)
# Part4d
with tf.name_scope('inception_4d'):
with tf.name_scope('Part1'):
kernel_4d_1 = weight_variable([1, 1, 512, 112], name='kernel_4d_1')
bias_4d_1 = bias_variable([112], name='bias_4d_1')
with tf.name_scope('conv1x1'):
layer_4d_1 = tf.nn.relu(conv2d(layer_4c, kernel_4d_1, [1, 1, 1, 1], name='conv_layer_4d_1') + bias_4d_1,
name='layer_4d_1') # size = (14,14,112)
with tf.name_scope('Part2'):
kernel_4d_2_1 = weight_variable([1, 1, 512, 144], name='kernel_4d_2_1')
bias_4d_2_1 = bias_variable([144], name='bias_4d_2_1')
kernel_4d_2_2 = weight_variable([3, 3, 144, 288], name='kernel_4d_2_2')
bias_4d_2_2 = bias_variable([288], name='bias_4d_2_2')
with tf.name_scope('conv1x1'):
layer_4d_2_1 = tf.nn.relu(conv2d(layer_4c, kernel_4d_2_1, [1, 1, 1, 1], name='conv_layer_4d_2_1') + bias_4d_2_1,
name='layer_4d_2_1') # size = (14,14,144)
with tf.name_scope('conv3x3'):
layer_4d_2_2 = tf.nn.relu(
conv2d(layer_4d_2_1, kernel_4d_2_2, [1, 1, 1, 1], name='conv_layer_4d_2_2') + bias_4d_2_2,
name='layer_4d_2_2') # size = (14,14,288)
with tf.name_scope('Part3'):
kernel_4d_3_1 = weight_variable([1, 1, 512, 32], name='kernel_4d_3_1')
bias_4d_3_1 = bias_variable([32], name='bias_4d_3_1')
kernel_4d_3_2 = weight_variable([5, 5, 32, 64], name='kernel_4d_3_2')
bias_4d_3_2 = bias_variable([64], name='bias_4d_3_2')
with tf.name_scope('conv1x1'):
layer_4d_3_1 = tf.nn.relu(conv2d(layer_4c, kernel_4d_3_1, [1, 1, 1, 1], name='conv_layer_4d_3_1') + bias_4d_3_1,
name='layer_4d_3_1') # size = (14,14,32)
with tf.name_scope('conv5x5'):
layer_4d_3_2 = tf.nn.relu(
conv2d(layer_4d_3_1, kernel_4d_3_2, [1, 1, 1, 1], name='conv_layer_4d_3_2') + bias_4d_3_2,
name='layer_4d_3_2') # size = (14,14,64)
with tf.name_scope('Part4'):
kernel_4d_4 = weight_variable([1, 1, 512, 64], name='kernel_4d_4')
bias_4d_4 = bias_variable([64], name='bias_4d_4')
with tf.name_scope('MaxPool_3x3'):
max_pool_4d_1 = tf.nn.max_pool(layer_4c, ksize=[1, 3, 3, 1], strides=[1, 1, 1, 1], padding="SAME",
name='maxpool_4d_1') # size = (14,14,512)
with tf.name_scope('conv1x1'):
layer_4d_4 = tf.nn.relu(conv2d(max_pool_4d_1, kernel_4d_4, [1, 1, 1, 1], name='conv_layer_4d_4') + bias_4d_4,
name='layer_4d_4') # size = (14,14,64)
with tf.name_scope('DepthConcat'):
layer_4d = tf.concat([layer_4d_1, layer_4d_2_2, layer_4d_3_2, layer_4d_4], 3) # size = (14,14,528)
# Part4e
with tf.name_scope('inception_4e'):
with tf.name_scope('Part1'):
kernel_4e_1 = weight_variable([1, 1, 528, 256], name='kernel_4e_1')
bias_4e_1 = bias_variable([256], name='bias_4e_1')
with tf.name_scope('conv1x1'):
layer_4e_1 = tf.nn.relu(conv2d(layer_4d, kernel_4e_1, [1, 1, 1, 1], name='conv_layer_4e_1') + bias_4e_1,
name='layer_4e_1') # size = (14,14,256)
with tf.name_scope('Part2'):
kernel_4e_2_1 = weight_variable([1, 1, 528, 160], name='kernel_4e_2_1')
bias_4e_2_1 = bias_variable([160], name='bias_4e_2_1')
kernel_4e_2_2 = weight_variable([3, 3, 160, 320], name='kernel_4e_2_2')
bias_4e_2_2 = bias_variable([320], name='bias_4e_2_2')
with tf.name_scope('conv1x1'):
layer_4e_2_1 = tf.nn.relu(conv2d(layer_4d, kernel_4e_2_1, [1, 1, 1, 1], name='conv_layer_4e_2_1') + bias_4e_2_1,
name='layer_4e_2_1') # size = (14,14,160)
with tf.name_scope('conv3x3'):
layer_4e_2_2 = tf.nn.relu(
conv2d(layer_4e_2_1, kernel_4e_2_2, [1, 1, 1, 1], name='conv_layer_4e_2_2') + bias_4e_2_2,
name='layer_4e_2_2') # size = (14,14,320)
with tf.name_scope('Part3'):
kernel_4e_3_1 = weight_variable([1, 1, 528, 32], name='kernel_4e_3_1')
bias_4e_3_1 = bias_variable([32], name='bias_4e_3_1')
kernel_4e_3_2 = weight_variable([5, 5, 32, 128], name='kernel_4e_3_2')
bias_4e_3_2 = bias_variable([128], name='bias_4e_3_2')
with tf.name_scope('conv1x1'):
layer_4e_3_1 = tf.nn.relu(conv2d(layer_4d, kernel_4e_3_1, [1, 1, 1, 1], name='conv_layer_4e_3_1') + bias_4e_3_1,
name='layer_4e_3_1') # size = (14,14,32)
with tf.name_scope('conv5x5'):
layer_4e_3_2 = tf.nn.relu(
conv2d(layer_4e_3_1, kernel_4e_3_2, [1, 1, 1, 1], name='conv_layer_4e_3_2') + bias_4e_3_2,
name='layer_4e_3_2') # size = (14,14,128)
with tf.name_scope('Part4'):
kernel_4e_4 = weight_variable([1, 1, 528, 128], name='kernel_4e_4')
bias_4e_4 = bias_variable([128], name='bias_4e_4')
with tf.name_scope('MaxPool_3x3'):
max_pool_4e_1 = tf.nn.max_pool(layer_4d, ksize=[1, 3, 3, 1], strides=[1, 1, 1, 1], padding="SAME",
name='maxpool_4e_1') # size = (14,14,528)
with tf.name_scope('conv1x1'):
layer_4e_4 = tf.nn.relu(conv2d(max_pool_4e_1, kernel_4e_4, [1, 1, 1, 1], name='conv_layer_4e_4') + bias_4e_4,
name='layer_4e_4') # size = (14,14,128)
with tf.name_scope('DepthConcat'):
layer_4e = tf.concat([layer_4e_1, layer_4e_2_2, layer_4e_3_2, layer_4e_4], 3) # size = (14,14,832)
# Part5
with tf.name_scope('MaxPool_4'):
MaxPool_4 = tf.nn.max_pool(layer_4e, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding="SAME",
name='MaxPool_5') # size = (7,7,832)
# Part5a
with tf.name_scope('inception_5a'):
with tf.name_scope('Part1'):
kernel_5a_1 = weight_variable([1, 1, 832, 256], name='kernel_5a_1')
bias_5a_1 = bias_variable([256], name='bias_5a_1')
with tf.name_scope('conv1x1'):
layer_5a_1 = tf.nn.relu(conv2d(MaxPool_4, kernel_5a_1, [1, 1, 1, 1], name='conv_layer_5a_1') + bias_5a_1,
name='layer_5a_1') # size = (7,7,256)
with tf.name_scope('Part2'):
kernel_5a_2_1 = weight_variable([1, 1, 832, 160], name='kernel_5a_2_1')
bias_5a_2_1 = bias_variable([160], name='bias_5a_2_1')
kernel_5a_2_2 = weight_variable([3, 3, 160, 320], name='kernel_5a_2_2')
bias_5a_2_2 = bias_variable([320], name='bias_5a_2_2')
with tf.name_scope('conv1x1'):
layer_5a_2_1 = tf.nn.relu(
conv2d(MaxPool_4, kernel_5a_2_1, [1, 1, 1, 1], name='conv_layer_5a_2_1') + bias_5a_2_1,
name='layer_5a_2_1') # size = (7,7,160)
with tf.name_scope('conv3x3'):
layer_5a_2_2 = tf.nn.relu(
conv2d(layer_5a_2_1, kernel_5a_2_2, [1, 1, 1, 1], name='conv_layer_5a_2_2') + bias_5a_2_2,
name='layer_5a_2_2') # size = (7,7,320)
with tf.name_scope('Part3'):
kernel_5a_3_1 = weight_variable([1, 1, 832, 32], name='kernel_5a_3_1')
bias_5a_3_1 = bias_variable([32], name='bias_5a_3_1')
kernel_5a_3_2 = weight_variable([5, 5, 32, 128], name='kernel_5a_3_2')
bias_5a_3_2 = bias_variable([128], name='bias_5a_3_2')
with tf.name_scope('conv1x1'):
layer_5a_3_1 = tf.nn.relu(
conv2d(MaxPool_4, kernel_5a_3_1, [1, 1, 1, 1], name='conv_layer_5a_3_1') + bias_5a_3_1,
name='layer_5a_3_1') # size = (7,7,32)
with tf.name_scope('conv5x5'):
layer_5a_3_2 = tf.nn.relu(
conv2d(layer_5a_3_1, kernel_5a_3_2, [1, 1, 1, 1], name='conv_layer_5a_3_2') + bias_5a_3_2,
name='layer_5a_3_2') # size = (7,7,128)
with tf.name_scope('Part4'):
kernel_5a_4 = weight_variable([1, 1, 832, 128], name='kernel_5a_4')
bias_5a_4 = bias_variable([128], name='bias_5a_4')
with tf.name_scope('MaxPool_3x3'):
max_pool_5a_1 = tf.nn.max_pool(MaxPool_4, ksize=[1, 3, 3, 1], strides=[1, 1, 1, 1], padding="SAME",
name='maxpool_5a_1') # size = (7,7,832)
with tf.name_scope('conv1x1'):
layer_5a_4 = tf.nn.relu(conv2d(max_pool_5a_1, kernel_5a_4, [1, 1, 1, 1], name='conv_layer_5a_4') + bias_5a_4,
name='layer_5a_4') # size = (7,7,128)
with tf.name_scope('DepthConcat'):
layer_5a = tf.concat([layer_5a_1, layer_5a_2_2, layer_5a_3_2, layer_5a_4], 3) # size = (7,7,832)
# Part5b
with tf.name_scope('inception_5b'):
with tf.name_scope('Part1'):
kernel_5b_1 = weight_variable([1, 1, 832, 384], name='kernel_5b_1')
bias_5b_1 = bias_variable([384], name='bias_5b_1')
with tf.name_scope('conv1x1'):
layer_5b_1 = tf.nn.relu(conv2d(layer_5a, kernel_5b_1, [1, 1, 1, 1], name='conv_layer_5b_1') + bias_5b_1,
name='layer_5b_1') # size = (7,7,384)
with tf.name_scope('Part2'):
kernel_5b_2_1 = weight_variable([1, 1, 832, 192], name='kernel_5b_2_1')
bias_5b_2_1 = bias_variable([192], name='bias_5b_2_1')
kernel_5b_2_2 = weight_variable([3, 3, 192, 384], name='kernel_5b_2_2')
bias_5b_2_2 = bias_variable([384], name='bias_5b_2_2')
with tf.name_scope('conv1x1'):
layer_5b_2_1 = tf.nn.relu(conv2d(layer_5a, kernel_5b_2_1, [1, 1, 1, 1], name='conv_layer_5b_2_1') + bias_5b_2_1,
name='layer_5b_2_1') # size = (7,7,192)
with tf.name_scope('conv3x3'):
layer_5b_2_2 = tf.nn.relu(
conv2d(layer_5b_2_1, kernel_5b_2_2, [1, 1, 1, 1], name='conv_layer_5b_2_2') + bias_5b_2_2,
name='layer_5b_2_2') # size = (7,7,384)
with tf.name_scope('Part3'):
kernel_5b_3_1 = weight_variable([1, 1, 832, 48], name='kernel_5b_3_1')
bias_5b_3_1 = bias_variable([48], name='bias_5b_3_1')
kernel_5b_3_2 = weight_variable([5, 5, 48, 128], name='kernel_5b_3_2')
bias_5b_3_2 = bias_variable([128], name='bias_5b_3_2')
with tf.name_scope('conv1x1'):
layer_5b_3_1 = tf.nn.relu(conv2d(layer_5a, kernel_5b_3_1, [1, 1, 1, 1], name='conv_layer_5b_3_1') + bias_5b_3_1,
name='layer_5b_3_1') # size = (7,7,48)
with tf.name_scope('conv5x5'):
layer_5b_3_2 = tf.nn.relu(
conv2d(layer_5b_3_1, kernel_5b_3_2, [1, 1, 1, 1], name='conv_layer_5b_3_2') + bias_5b_3_2,
name='layer_5b_3_2') # size = (7,7,128)
with tf.name_scope('Part4'):
kernel_5b_4 = weight_variable([1, 1, 832, 128], name='kernel_5b_4')
bias_5b_4 = bias_variable([128], name='bias_5b_4')
with tf.name_scope('MaxPool_3x3'):
max_pool_5b_1 = tf.nn.max_pool(layer_5a, ksize=[1, 3, 3, 1], strides=[1, 1, 1, 1], padding="SAME",
name='maxpool_5b_1') # size = (7,7,832)
with tf.name_scope('conv1x1'):
layer_5b_4 = tf.nn.relu(conv2d(max_pool_5b_1, kernel_5b_4, [1, 1, 1, 1], name='conv_layer_5b_4') + bias_5b_4,
name='layer_5b_4') # size = (7,7,128)
with tf.name_scope('DepthConcat'):
layer_5b = tf.concat([layer_5b_1, layer_5b_2_2, layer_5b_3_2, layer_5b_4], 3) # size = (7,7,1024)
# Softmax_assist_0
with tf.name_scope('Auxiliary_classifier_1'):
with tf.name_scope('AveragePool'):
Avg_assist_0 = tf.nn.avg_pool(layer_4a, ksize=[1, 5, 5, 1], strides=[1, 3, 3, 1], padding="VALID",
name='Avg') # size = (4,4,512)
with tf.name_scope('Conv'):
kernel_assist_0 = weight_variable([1, 1, 512, 1024], name='kernel_assist_0')
bias_assist_0 = bias_variable([1024], name='bias_assist_0')
conv_layer_assist_0 = tf.nn.relu(conv2d(Avg_assist_0, kernel_assist_0, [1, 1, 1, 1]) + bias_assist_0,
name='conv_layer_assist_0') # size = (4,4,1024)
with tf.name_scope('FC1'):
line_assist_0 = tf.reshape(conv_layer_assist_0, [-1, 16384])
fc_assist_0_weight_1 = weight_variable([16384, 1000], name='fc_assist_0_weight_1')
fc_assist_0_bias_1 = bias_variable([1000], name='fc_assist_0_bias_1')
layer_assist_0_dropout_1 = tf.nn.dropout(line_assist_0, keep_prob, name='layer_assist_0_dropout_1')
layer_assist_0_1 = tf.nn.relu(
tf.matmul(layer_assist_0_dropout_1, fc_assist_0_weight_1,
name='matmul_layer_assist_0_1') + fc_assist_0_bias_1,
name='layer_assist_0_1')
with tf.name_scope('FC2'):
fc_assist_0_weight_2 = weight_variable([1000, 1000], name='fc_assist_0_weight_2')
fc_assist_0_bias_2 = bias_variable([1000], name='fc_assist_0_bias_2')
layer_assist_0_dropout_2 = tf.nn.dropout(layer_assist_0_1, keep_prob, name='layer_assist_0_dropout_2')
layer_assist_0_2 = tf.nn.relu(
tf.matmul(layer_assist_0_dropout_2, fc_assist_0_weight_2, name='matmul_layer_assist_0_2') + fc_assist_0_bias_2,
name='layer_assist_0_2')
with tf.name_scope('softmax0'):
output_assist_0 = tf.nn.softmax(layer_assist_0_2, name='output_assist_0')
# Softmax_assist_1
with tf.name_scope('Auxiliary_classifier_2'):
with tf.name_scope('AveragePool'):
Avg_assist_1 = tf.nn.avg_pool(layer_4d, ksize=[1, 5, 5, 1], strides=[1, 3, 3, 1], padding="VALID",
name='Avg') # size = (4,4,528)
with tf.name_scope('Conv'):
kernel_assist_1 = weight_variable([1, 1, 528, 1024], name='kernel_assist_1')
bias_assist_1 = bias_variable([1024], name='bias_assist_1')
conv_layer_assist_1 = tf.nn.relu(conv2d(Avg_assist_1, kernel_assist_1, [1, 1, 1, 1]) + bias_assist_1,
name='conv_layer_assist_1') # size = (4,4,1024)
with tf.name_scope('FC1'):
line_assist_1 = tf.reshape(conv_layer_assist_1, [-1, 16384])
fc_assist_1_weight_1 = weight_variable([16384, 1000], name='fc_assist_1_weight_1')
fc_assist_1_bias_1 = bias_variable([1000], name='fc_assist_1_bias_1')
layer_assist_1_dropout_1 = tf.nn.dropout(line_assist_1, keep_prob, name='layer_assist_1_dropout_1')
layer_assist_1_1 = tf.nn.relu(
tf.matmul(layer_assist_1_dropout_1, fc_assist_1_weight_1,
name='matmul_layer_assist_1_1') + fc_assist_1_bias_1,
name='layer_assist_1_1')
with tf.name_scope('FC2'):
fc_assist_1_weight_2 = weight_variable([1000, 1000], name='fc_assist_1_weight_2')
fc_assist_1_bias_2 = bias_variable([1000], name='fc_assist_1_bias_2')
layer_assist_1_dropout_2 = tf.nn.dropout(layer_assist_1_1, keep_prob, name='layer_assist_1_dropout_2')
layer_assist_1_2 = tf.nn.relu(
tf.matmul(layer_assist_1_dropout_2, fc_assist_1_weight_2, name='matmul_layer_assist_1_2') + fc_assist_1_bias_2,
name='layer_assist_1_2')
with tf.name_scope('softmax1'):
output_assist_1 = tf.nn.softmax(layer_assist_1_2, name='output_assist_1')
# Softmax
with tf.name_scope('Classifier'):
with tf.name_scope('AveragePool'):
Avg = tf.nn.avg_pool(layer_5b, ksize=[1, 7, 7, 1], strides=[1, 1, 1, 1], padding="VALID",
name='Avg') # size = (1,1,1024)
with tf.name_scope('FC'):
line = tf.reshape(Avg, [-1, 1024])
fc_weight = weight_variable([1024, 1000], name='fc_weight')
fc_bias = bias_variable([1000], name='fc_bias')
layer_dropout = tf.nn.dropout(line, keep_prob, name='layer_dropout')
layer = tf.nn.relu(tf.matmul(layer_dropout, fc_weight, name='matmul_layer') + fc_bias, name='layer')
with tf.name_scope('Output'):
output = tf.nn.softmax(layer, name='output')
return output, output_assist_0, output_assist_1
def backward(datasets, label, test_data, test_label):
with tf.name_scope('Input_data'):
X = tf.placeholder(tf.float32, [None, 224, 224, 3], name="Input")
Y_ = tf.placeholder(tf.float32, [None, 1], name='Estimation')
LEARNING_RATE_BASE = 0.00001 # 最初学习率
LEARNING_RATE_DECAY = 0.99 # 学习率的衰减率
LEARNING_RATE_STEP = 1000 # 喂入多少轮BATCH-SIZE以后,更新一次学习率。一般为总样本数量/BATCH_SIZE
gloabl_steps = tf.Variable(0, trainable=False) # 计数器,用来记录运行了几轮的BATCH_SIZE,初始为0,设置为不可训练
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, gloabl_steps, LEARNING_RATE_STEP,
LEARNING_RATE_DECAY, staircase=True)
keep_prob = tf.placeholder(tf.float32, name="keep_prob")
y = VGG16(X)
global_step = tf.Variable(0, trainable=False)
with tf.name_scope('Accuracy'):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(Y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
with tf.name_scope('loss'):
loss_mse = tf.reduce_mean(-tf.reduce_sum(Y_ * tf.log(y), reduction_indices=[1]))
tf.summary.scalar('loss', loss)
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(0.001).minimize(loss_mse)
saver = tf.train.Saver()
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
writer = tf.summary.FileWriter("./logs", sess.graph)
sess.run(init_op)
# 训练模型。
STEPS = 500001
min_loss = 1
for i in range(STEPS):
start = (i * BATCH_SIZE) % len(datasets)
end = start + BATCH_SIZE
if i % 100 == 0:
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
summary_str, step, _ = sess.run([merged, gloabl_steps, train_step],
feed_dict={X: datasets[start:end], Y_: label[start:end], keep_prob:1.0},
options=run_options, run_metadata=run_metadata)
writer.add_summary(summary_str, i)
writer.add_run_metadata(run_metadata, 'step%d' % (i))
test_accuracy = accuracy.eval(feed_dict={X: test_data, Y_: test_label, keep_prob: 1.0})
print("After %d training step(s), accuracy is %g" % (i, test_accuracy))
saver.save(sess, './logs/variable', global_step=i)
else:
summary_str, step, _ = sess.run([merged, gloabl_steps, train_step],
feed_dict={X: datasets[start:end], Y_: label[start:end]})
writer.add_summary(summary_str, i)
def main():
with tf.name_scope('Input_data'):
X = tf.placeholder(tf.float32, [None, 224, 224, 3], name="Input")
y = GoogLeNet_v1(X)
sess = tf.Session()
writer = tf.summary.FileWriter("./logs", sess.graph)
writer.close()
if __name__ == '__main__':
main()
然后我们用tensorboard打开图观察:
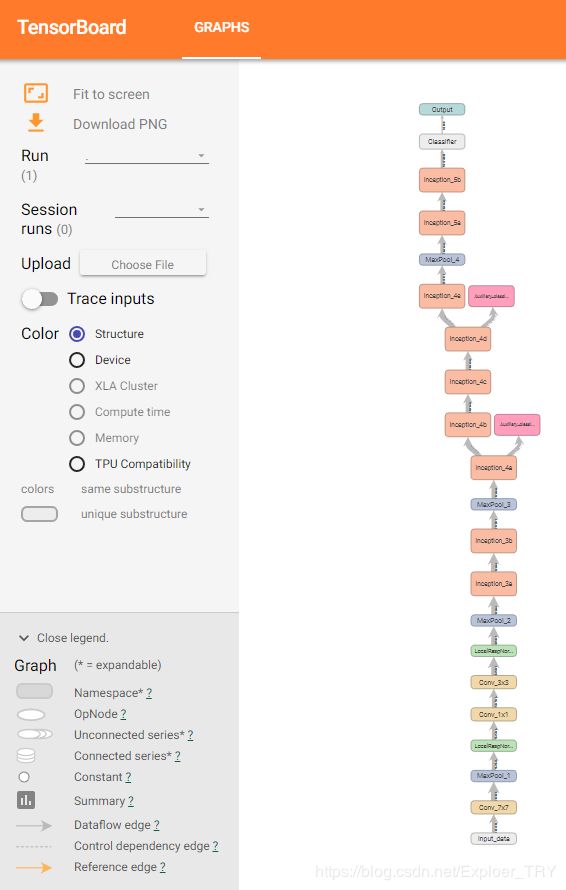
这里与真实的模型的结构相当 ,验证我们的demo编程的正确性。