mmdetection中的mmdet.datasets
1.collate
用来拼接batch中的数据。与标准的pytorch中的default_collate不同,这里的collate返回的是一个列表,每个列表中的元素是一个minibatch,应该是为了用于多个gpu,每个gpu上运行一个minibatch。
collate支持对于DataContainer数据类型的操作,
对于meta data,直接拼成minibatch,返回
对于图像,先pad成同样大小,再拼成minibatch,返回
对于bbox,直接拼接,返回。
一般来说,distributed为FALSE,进而使用**_non_dist_train**,进而build_dataloader的dist参数为FALSE,
所以build_dataloader中sampler和batch_size等是这么定义的:
else:
sampler = GroupSampler(dataset, imgs_per_gpu) if shuffle else None
batch_size = num_gpus * imgs_per_gpu
num_workers = num_gpus * workers_per_gpu
def collate(batch, samples_per_gpu=1):
"""Puts each data field into a tensor/DataContainer with outer dimension
batch size.
Extend default_collate to add support for
:type:`~mmcv.parallel.DataContainer`. There are 3 cases.
1. cpu_only = True, e.g., meta data
2. cpu_only = False, stack = True, e.g., images tensors
3. cpu_only = False, stack = False, e.g., gt bboxes
"""
if not isinstance(batch, collections.Sequence):
raise TypeError("{} is not supported.".format(batch.dtype))
if isinstance(batch[0], DataContainer):
assert len(batch) % samples_per_gpu == 0
stacked = []
if batch[0].cpu_only:
# 如果是cpu_only,说明是meta data,数据类型不固定,例如字符串。
# 那么将data一个一个的append进stacked中,每个mini_batch的大小为samples_per_gpu
# stacked = [[d1, d2, d3], [d4, d5, d6], [...], ...],由于batch % samples_per_gpu == 0,每个mini_batch中个数相同。
# stacked被装进一个DataContainer返回。
for i in range(0, len(batch), samples_per_gpu):
stacked.append(
[sample.data for sample in batch[i:i + samples_per_gpu]])
return DataContainer(
stacked, batch[0].stack, batch[0].padding_value, cpu_only=True)
# 如果是stack,且不是cpu,说明是图像,是Tensor。
# 那么首先对图像进行pad,使得图像的形状一样,之后使用标准的default_collate,将每一个mini_batch中的图像进行拼接
elif batch[0].stack:
for i in range(0, len(batch), samples_per_gpu):
assert isinstance(batch[i].data, torch.Tensor)
# pad用来给图像进行pad,添加边框,边框的值为batch[0]padding_value。
# pad的目的是让所有图像的大小一致
if batch[i].pad_dims is not None:
# ndim为图像的维度(指标的个数)
ndim = batch[i].dim()
assert ndim > batch[i].pad_dims
max_shape = [0 for _ in range(batch[i].pad_dims)]
for dim in range(1, batch[i].pad_dims + 1):
max_shape[dim - 1] = batch[i].size(-dim)
# pad_dims取值在[None, 1, 2, 3]内
# max_shape最终得到的是batch[i]的size的倒序,如原本为3 * 255 * 255,则max_shape = [255, 255, 3]
for sample in batch[i:i + samples_per_gpu]:
for dim in range(0, ndim - batch[i].pad_dims):
assert batch[i].size(dim) == sample.size(dim)
for dim in range(1, batch[i].pad_dims + 1):
max_shape[dim - 1] = max(max_shape[dim - 1],
sample.size(-dim))
# max_shape与其他sample比较,取shape的max。
padded_samples = []
for sample in batch[i:i + samples_per_gpu]:
pad = [0 for _ in range(batch[i].pad_dims * 2)]
# pad的大小为pad_dims的2倍,2指的是在该维度的前后进行pad。
for dim in range(1, batch[i].pad_dims + 1):
pad[2 * dim -
1] = max_shape[dim - 1] - sample.size(-dim)
# 目的是进行pad之后所有图像的大小一致。
padded_samples.append(
F.pad(
sample.data, pad, value=sample.padding_value))
stacked.append(default_collate(padded_samples))
elif batch[i].pad_dims is None:
stacked.append(
default_collate([
sample.data
for sample in batch[i:i + samples_per_gpu]
]))
else:
raise ValueError(
'pad_dims should be either None or integers (1-3)')
# 这种情况对应bbox,这个时候直接取出来(是一个列表),分割成成samples_per_gpu大小的mini batch,直接返回
else:
for i in range(0, len(batch), samples_per_gpu):
stacked.append(
[sample.data for sample in batch[i:i + samples_per_gpu]])
return DataContainer(stacked, batch[0].stack, batch[0].padding_value)
# 有可能出现递归操作,这些与default_collate一致
elif isinstance(batch[0], collections.Sequence):
transposed = zip(*batch)
return [collate(samples, samples_per_gpu) for samples in transposed]
elif isinstance(batch[0], collections.Mapping):
return {
key: collate([d[key] for d in batch], samples_per_gpu)
for key in batch[0]
}
# 对于其他操作使用default_collate
else:
return default_collate(batch)
pytorch自带的default_collate解释如下:
def default_collate(batch):
r"""Puts each data field into a tensor with outer dimension batch size"""
elem = batch[0]
elem_type = type(elem)
# 如果元素是Tensor,首先查看类型是否为Tensor,如果是Tensor,则查看get_worker_info()是否为空。
# torch.utils.data.get_worker_info()的作用是返回工作进程中的各种有用信息(包括工作者ID,数据集副本,初始种子等)
# 如果get_worker_info不为空,说明在另外的进程中,这个时候,首先numel获得所需内存大小,用_new_shared创建一块新的内存,用new创建一个在该内存上的Tensor
# 最终,使用stack直接拼接起来。
# Creates a new storage in shared memory with the same data type
if isinstance(elem, torch.Tensor):
out = None
if torch.utils.data.get_worker_info() is not None:
# If we're in a background process, concatenate directly into a
# shared memory tensor to avoid an extra copy
numel = sum([x.numel() for x in batch])
storage = elem.storage()._new_shared(numel)
out = elem.new(storage)
return torch.stack(batch, 0, out=out)
# 如果元素是numpy中的类型,并且是ndarray,则变成Tensor之后,再递归调用自身进行gather
elif elem_type.__module__ == 'numpy' and elem_type.__name__ != 'str_' \
and elem_type.__name__ != 'string_':
elem = batch[0]
if elem_type.__name__ == 'ndarray':
# array of string classes and object
if np_str_obj_array_pattern.search(elem.dtype.str) is not None:
raise TypeError(default_collate_err_msg_format.format(elem.dtype))
return default_collate([torch.as_tensor(b) for b in batch])
elif elem.shape == (): # scalars
return torch.as_tensor(batch)
# 如果元素是标量,直接初始化为Tensor
elif isinstance(elem, float):
return torch.tensor(batch, dtype=torch.float64)
elif isinstance(elem, int_classes):
return torch.tensor(batch)
# 如果元素是字符串,直接返回
elif isinstance(elem, string_classes):
return batch
# 如果元素是字典,对字典中的每个value递归进行gather
# 如[{'a': [1, 2]}, {'a': [3, 4]}],collate之后变成{'a': [1, 2, 3, 4]}
elif isinstance(elem, container_abcs.Mapping):
return {key: default_collate([d[key] for d in batch]) for key in elem}
# 如果元素是元组的话,
elif isinstance(elem, tuple) and hasattr(elem, '_fields'): # namedtuple
return elem_type(*(default_collate(samples) for samples in zip(*batch)))
# 如果元素是序列的话,先用zip将batch中对应位置的元素集合到一起形成新元素,之后对新元素进行递归的gather操作
elif isinstance(elem, container_abcs.Sequence):
transposed = zip(*batch)
return [default_collate(samples) for samples in transposed]
raise TypeError(default_collate_err_msg_format.format(elem_type))
举一个例子:
batch = [{‘name’: ‘a’, ‘bbox’: [[[1, 2], [3, 4]]]},
{‘name’: ‘b’, ‘bbox’: [[[5, 6], [7, 8]]]}
则首先batch的元素是dict,因此先集合成{‘name’: [‘a’, ‘b’], ‘bbox’: [[[[1, 2], [3, 4]]], [[[5, 6], [7, 8]]]]}
再对每个value进行collate,字符串序列保持不变,bbox则stack到一起。
更一般的例子:
如果每个elem是一个树形结构,则default_collate会递归的调用,将每棵树对应的部分(string,Tensor等)使用collate拼接起来。
2. sampler
就如collate一开始所说,一般dist=False, 因此采用GroupSampler。
其有一些属性。
dataset:数据集
samples_per_gpu:每张gpu的样本个数
flag:长宽比是否大于1的0, 1序列,将data分为了两组。在customdataset中定义
group_sizes:上面划分的两组的组内个数
num_samples:对groups_sizes中的每个数先除以samples_per_gpu,取整再乘上去,再共同相加。得到的是总体数目(可被sample_per_gpu整除)。
GroupSampler的作用是给出一个index,这个index是总体dataset成员的index,能够随机取出dataset中的元素。在dataloader的初始化过程中,sampler就被转化为了iter,固定了下来。
class GroupSampler(Sampler):
def __init__(self, dataset, samples_per_gpu=1):
assert hasattr(dataset, 'flag')
self.dataset = dataset
self.samples_per_gpu = samples_per_gpu
self.flag = dataset.flag.astype(np.int64)
self.group_sizes = np.bincount(self.flag)
self.num_samples = 0
for i, size in enumerate(self.group_sizes):
self.num_samples += int(np.ceil(
size / self.samples_per_gpu)) * self.samples_per_gpu
def __iter__(self):
indices = []
for i, size in enumerate(self.group_sizes):
if size == 0:
continue
# 获得下标indice
indice = np.where(self.flag == i)[0]
assert len(indice) == size
# 随机打乱
np.random.shuffle(indice)
num_extra = int(np.ceil(size / self.samples_per_gpu)
) * self.samples_per_gpu - len(indice)
# 拼接上一些元素(从indice尾部往后数),使得indice的个数被samples_per_gpu整除
indice = np.concatenate([indice, indice[:num_extra]])
indices.append(indice)
# indices里头两个group的数量都能被samples_per_gpu整除
indices = np.concatenate(indices)
# 重新打乱indices(将另个group混合在一起),相邻两个为一组打乱(之所以两个为一组猜测是为了减少计算时间)
indices = [
indices[i * self.samples_per_gpu:(i + 1) * self.samples_per_gpu]
for i in np.random.permutation(
range(len(indices) // self.samples_per_gpu))
]
indices = np.concatenate(indices)
indices = indices.astype(np.int64).tolist()
assert len(indices) == self.num_samples
return iter(indices)
def __len__(self):
return self.num_samples
3. DataSets
基础类CustomDataset,继承自pytorch的DataSets类。
data的数据结构为:
Annotation format:
[
{
'filename': 'a.jpg',
'width': 1280,
'height': 720,
'ann': {
'bboxes': (n, 4),
'labels': (n, ),
'bboxes_ignore': (k, 4),
'labels_ignore': (k, 4) (optional field)
}
},
...
]
__init__部分出现的属性:

img_infos: 图片的信息,通过cocoapi读入
proposals:None
ImageTransform:用来对图像、mask进行尺度变化、翻转、正规化。
BboxTransform:根据图像尺寸rescale bbox,翻转。
img_ids:出现在CocoDataset类中,为self.coco.getImgIds()
4. 数据流
4.1. ruuer.train从data_loader中读出data_batch
data_batch是一个dict,

其中
img_meta的data为包含两个元素的list,元素是包含另个元素的list,每个元素是一个dict,包含了如下信息: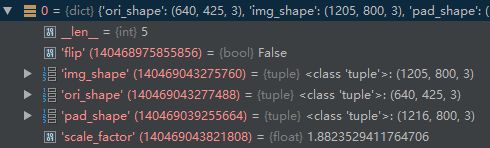
img的data为包含两个元素的list,元素是231216*800的Tensor
gt_bboxes的data为包含两个元素的list,每个元素是一个list,其中有两个Tensor,大小为n * 4
gt_labels的data为包含两个元素的list,每个元素是一个list,其中有两个Tensor,大小为n
4.2.data_batch经由batch_processor进入model
def batch_processor(model, data, train_mode):
losses = model(**data)
loss, log_vars = parse_losses(losses)
outputs = dict(
loss=loss, log_vars=log_vars, num_samples=len(data['img'].data))
return outputs
pytorch并行的参考资料:
https://blog.csdn.net/zzlyw/article/details/78769012
https://blog.csdn.net/weixin_40087578/article/details/87186613,以下过程参考这张图:

4.3. data进入DataParallel(Pytorch的)
由于model外层套着DataParallel类,因此先使用DataParallel类的forward。
4.3. data进入MMDataParallel(继承自DataParallel(Pytorch的))
由于model外层套着MMDataParallel类,因此先使用MMDataParallel类的forward。以下为MMDataParallel的forward,与DataParallel的forward相同。
def forward(self, *inputs, **kwargs):
if not self.device_ids:
return self.module(*inputs, **kwargs)
for t in chain(self.module.parameters(), self.module.buffers()):
if t.device != self.src_device_obj:
raise RuntimeError("module must have its parameters and buffers "
"on device {} (device_ids[0]) but found one of "
"them on device: {}".format(self.src_device_obj, t.device))
inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
if len(self.device_ids) == 1:
return self.module(*inputs[0], **kwargs[0])
replicas = self.replicate(self.module, self.device_ids[:len(inputs)])
outputs = self.parallel_apply(replicas, inputs, kwargs)
return self.gather(outputs, self.output_device)
data转换为inputs,kwargs,交由scatter来分散到不同的GPU上。
4.4. inputs, kwargs传入scatter(mmcv重写了该函数)
scatter(MMDataParallel的成员函数)->scatter_kwargs(依然是mmcv重写)->scatter函数(mmcv中,在scatter_gather.py中)-> Scatter静态类的forward函数(mmcv中)->scatter函数(mmcv中,在_functions,py中)
第一个scatter函数,其中定义了一个函数scatter_map,对于dict,它通过map将scatter_map递归的作用于其中的元素,并进行了一些操作,最终得到了一个列表,列表中有len(target_gpus)个数个元素,每个元素对应于一个GPU。
总的来说,作用是获得不同设备上的data。
def scatter(inputs, target_gpus, dim=0):
"""Scatter inputs to target gpus.
The only difference from original :func:`scatter` is to add support for
:type:`~mmcv.parallel.DataContainer`.
"""
def scatter_map(obj):
if isinstance(obj, torch.Tensor):
return OrigScatter.apply(target_gpus, None, dim, obj)
if isinstance(obj, DataContainer):
if obj.cpu_only:
return obj.data
else:
return Scatter.forward(target_gpus, obj.data)
if isinstance(obj, tuple) and len(obj) > 0:
return list(zip(*map(scatter_map, obj)))
if isinstance(obj, list) and len(obj) > 0:
out = list(map(list, zip(*map(scatter_map, obj))))
return out
if isinstance(obj, dict) and len(obj) > 0:
out = list(map(type(obj), zip(*map(scatter_map, obj.items()))))
return out
return [obj for targets in target_gpus]
# After scatter_map is called, a scatter_map cell will exist. This cell
# has a reference to the actual function scatter_map, which has references
# to a closure that has a reference to the scatter_map cell (because the
# fn is recursive). To avoid this reference cycle, we set the function to
# None, clearing the cell
try:
return scatter_map(inputs)
finally:
scatter_map = None
4.5. 上面流程中最后的scatter函数(分配gpu,返回整体)
上面流程中最后的scatter函数如下:
def scatter(input, devices, streams=None):
"""Scatters tensor across multiple GPUs.
"""
if streams is None:
streams = [None] * len(devices)
if isinstance(input, list):
chunk_size = (len(input) - 1) // len(devices) + 1
outputs = [
scatter(input[i], [devices[i // chunk_size]],
[streams[i // chunk_size]]) for i in range(len(input))
]
return outputs
elif isinstance(input, torch.Tensor):
output = input.contiguous()
# TODO: copy to a pinned buffer first (if copying from CPU)
stream = streams[0] if output.numel() > 0 else None
with torch.cuda.device(devices[0]), torch.cuda.stream(stream):
output = output.cuda(devices[0], non_blocking=True)
return output
else:
raise Exception('Unknown type {}.'.format(type(input)))
其作用是通过递归的方式来将数据分散到各个设备上。
例子:
input = [tensor([[1, 2], [3, 4]]), tensor([[5, 6], [7, 8]])]
devices = [0, 1]
scatter检测到是列表,递归调用:
第一次input[0] = tensor([[1, 2], [3, 4]]), devices=[0],检测到是Tensor,通过 output = output.cuda(devices[0], non_blocking=True)来分配到cuda:0上,并返回对象
第二次同理,分配到cuda:1上,返回对象
scatter返回列表,元素与之前相同,但是设备已经不一样了,一个在0上,一个在1上。
4.6前. self.module传入replicate(pytorch中)中,获得各个gpu上的模型
对应于DataParallel类的forward中的
replicas = self.replicate(self.module, self.device_ids[:len(inputs)])
得到的replicas 是一个列表,包含多个gpu上的模型
4.6. inputs, kwargs(列表)传入parallel_apply函数
大致思路就是上面那张图,将kwargs_tup的各个元素分配到modules的各个元素上,运行。最后还存在一个汇总的步骤,就不写了。
def parallel_apply(modules, inputs, kwargs_tup=None, devices=None):
r"""Applies each `module` in :attr:`modules` in parallel on arguments
contained in :attr:`inputs` (positional) and :attr:`kwargs_tup` (keyword)
on each of :attr:`devices`.
Args:
modules (Module): modules to be parallelized
inputs (tensor): inputs to the modules
devices (list of int or torch.device): CUDA devices
:attr:`modules`, :attr:`inputs`, :attr:`kwargs_tup` (if given), and
:attr:`devices` (if given) should all have same length. Moreover, each
element of :attr:`inputs` can either be a single object as the only argument
to a module, or a collection of positional arguments.
"""
assert len(modules) == len(inputs)
if kwargs_tup is not None:
assert len(modules) == len(kwargs_tup)
else:
kwargs_tup = ({},) * len(modules)
if devices is not None:
assert len(modules) == len(devices)
else:
devices = [None] * len(modules)
devices = list(map(lambda x: _get_device_index(x, True), devices))
lock = threading.Lock()
results = {}
grad_enabled = torch.is_grad_enabled()
def _worker(i, module, input, kwargs, device=None):
torch.set_grad_enabled(grad_enabled)
if device is None:
device = get_a_var(input).get_device()
try:
with torch.cuda.device(device):
# this also avoids accidental slicing of `input` if it is a Tensor
if not isinstance(input, (list, tuple)):
input = (input,)
output = module(*input, **kwargs)
with lock:
results[i] = output
except Exception:
with lock:
results[i] = ExceptionWrapper(
where="in replica {} on device {}".format(i, device))
if len(modules) > 1:
threads = [threading.Thread(target=_worker,
args=(i, module, input, kwargs, device))
for i, (module, input, kwargs, device) in
enumerate(zip(modules, inputs, kwargs_tup, devices))]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
else:
_worker(0, modules[0], inputs[0], kwargs_tup[0], devices[0])
outputs = []
for i in range(len(inputs)):
output = results[i]
if isinstance(output, ExceptionWrapper):
output.reraise()
outputs.append(output)
return outputs