卷积神经网络CNN(5)—— Dilated Convolution
introduction
参考:Multi-Scale Context Aggregation by Dilated Convolutions
在CNN中,Convolution与Pooling可谓最佳搭档,密不可分,在LeNet作者提出基本的CNN框架的时候,普通计算机计算能力并不优秀,所以Pooling作为提取重要特征以及减少计算量的一个重要手段。但是,在图像计算能力发展迅速的时代,Dilated Convolution作者文中一开始就反问” Is it necessary?”。现在像素级别的网络成为热门研究对象,Pooling对于像素的操作可谓简单粗暴,直接减少3/4的像素,不过很多pixel-wise的网络(如SegNet卷积神经网络CNN(4)),需要通过卷积重新学习来填补像素的缺失,因此这对效率与精度都有很大影响。Dilated Convolution就由此而生,不仅有助于增加精度,而且可以减少一部分由于相乘得到的权值,从而减少计算量。
Dilated Convolution in 1D
博主不从图像(二维)开始讲解Dilated Convolution,因为不利于公式推导与理解,所以博主根据Dilated Convolution的定义,从一维卷积作为例子开始说明。回顾卷积神经网络CNN(1),博主采用了matlab的定义将二维卷积分为三类(caffe中卷积分类非常多,matlab中的分类理解相对容易),下面主要围绕full卷积,full卷积正好是一维卷积在二维完整对应。下面是一维离散卷积的计算公式,
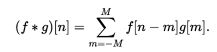
用一个例子来计算一维离散卷积,假设
卷积核(g[n]):0 1 2
g(0)=0, g(1)=1, g(2)=2, 其他 g(n)=0
原函数(f[n]): 0 1 2
f(0)=0, g(1)=1, g(2)=2, 其他 f(n)=0
反转卷积核,滑动卷积核到原函数各个位置可计算出(f*g)[n]:
(f*g)[0]:
2 1 0
0 1 2
(f*g)[0] = f[0-0]g[0] = 0
...
(f*g)[2]:
2 1 0
0 1 2
(f*g)[2] = f[2-0]g[0] + f[2-1]g[1] + f[2-2]g[2] = 1
...
(f*g)[4]:
2 1 0
0 1 2
(f*g)[4] = f[4-2]g[2] = 4 通过上述计算,得到(f*g)[n]=0 0 1 4 4,同时可以知道卷积后大小是卷积核长度+原函数长度-1,即是3+3-1=5。
根据Dilated Convolution作者对Dilated Convolution的定义,在一维的情况,博主转化为如下,

接下来就按上面一模一样的卷积核与原函数,取l=2,计算一下一维的Dilated Convolution。
f = 0 1 2
g = 0 1 2
l = 2
由于l=2,使g = 0 _ 1 _ 2, _表示空,实际并不会参与计算
(f*lg)[0]:
2 _ 1 _ 0
0 1 2
(f*lg)[0] = f[0-2*0]g[0] = 0
(f*lg)[1]:
2 _ 1 _ 0
0 1 2
(f*lg)[1] = f[1-2*0]g[0] = 0
(f*lg)[2]:
2 _ 1 _ 0
0 1 2
(f*lg)[2] = f[2-2*0]g[0] + f[2-2*1]g[1] = 0
(f*lg)[3]:
2 _ 1 _ 0
0 1 2
(f*lg)[3] = f[3-2*1]g[1] = 1
(f*lg)[4]:
2 _ 1 _ 0
0 1 2
(f*lg)[4] = f[4-2*1]g[1] + f[4-2*2]g[2] = 2
(f*lg)[5]:
2 _ 1 _ 0
0 1 2
(f*lg)[5] = f[5-2*2]g[2] = 2
(f*lg)[6]:
2 _ 1 _ 0
0 1 2
(f*lg)[6] = f[6-2*2]g[2] = 4 最后得到(f*lg)[n] = 0 0 0 1 2 2 4 ,下面根据Dilated Convolution特性以及与一维离散卷积比较来解释一维Dilated Convolution。
1.Dilated Convolution长度大于一维卷积长度。
这是最为直接的观测结果,意味着增加了感知范围,有着与扩大卷积核大小或upsample的作用。
给出Dilated Convolution长度计算公式:原函数长度 + l x (核函数长度 - 1)
计算上面Dilated Convolution例子,原函数与核函数长度都为3, l = 2, 所以卷积后长度 = 3+2*(3-1) = 7
所以当 l 取不同的值,就可以得到不同大小的卷积结果,当 l = 1时,Dilated Convolution与一维卷积是一样的。这可是一个非常重要的结论。
2.Dilated Convolution卷积核感知(计算)区域变大
从例子中可以看到,当我计算Dilated Convolution时,把卷积核从 0 1 2 变为 0 _ 1 _ 2,计算过程中也发现不会存在需要对 _ 的卷积计算,因为变的不是卷积核,只是卷积的计算方式。可以看到,实际计算时,通过取不同的 l ,卷积核的计算区域可以增大,说明使用小的卷积核,可以计算更大的区域,这可以减少卷积核的大小,从而减少权重数量。
3.Dilated Convolution计算结果总和 与 一维卷积计算结果总和相等
从上面两个例子可以知道,卷积结果的和都是9, 说明总的计算量是一样,只是Dilated Convolution计算分在了更多的区域,直观地看,Dilated Convolution将普通卷积的计算结果重新分布在更多的区域,但是总的结果不变。这一点也是Dilated Convolution局限性所在。
Dilated Convolution in 2D
详细对道一维的Dilated Convolution后,对于二维Dilated Convolution的理解就不难了。Dilated Convolution作者对Dilated Convolution在二维的定义,

F为二维序列(图像),s是其定义域;k是核函数,t是其定义域;l是Dilated倍数;p = s + lt,p是Dilated Convolution定义域。上述公式的理解与一维的情况并没有区别。
下面讨论作者提出的另外一个重要的理论,指数增长的感知区域,公式如下。
![]()
Fi是Dilated Convolution计算得到的感知区域,ki是卷积核(规定ki都是3x3的核),l=2^i(l变成了以2为底的指数)。二维Dilated Convolution大小与一维的计算一致,原图维度 + l x (卷积核维度 - 1)。假设F0=1,我们可以推到Fi的大小,
F1 = 1 + 2^0*(3-1) = 3
F2 = 3 + 2^1*(3-1) = 7
F3 = 7 + 2^2*(3-1) = 15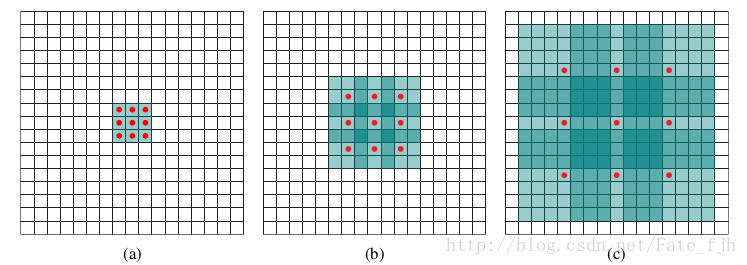
绿色区域为感知区域,(a)为F1, (b)为F2, (c)为F3。
感知区域大小公式:![]()
简要地说明Dilated Convolution应用到MULTI -SCALE CONTEXT AGGREGATION中。
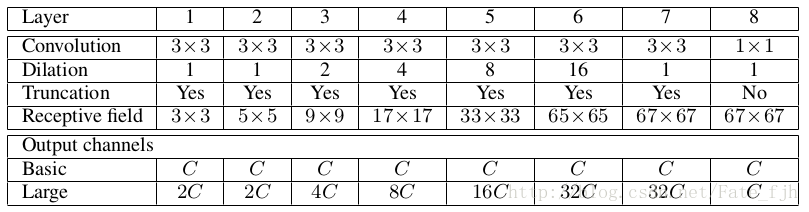
Layer为层数,Convolution为卷积核大小,Dilation为l大小,Truncation为图像是否要裁剪边缘(Dilated Convolution卷积后图像会变大),Receptive field为感知区域大小,Output channels为输出特征图数量,Basic为简单网络情况,Large为复杂网络情况。
表格中可以发现,
1.网络中并没有Pooling层,这就是作者提出不丢失像素的计算方法。
2.第一层对图像进行卷积,第二层对第一层输出的特征图进行卷积,如此循环到最后一层。
3.Dilation倍数从小到大,说明先使用小感知区域的卷积核获取局部特征,再用大感知区域的卷积核把特征分到更多区域中。