spark学习笔记--RDD基础
文章目录
- 创建RDD
- RDD操作
- 转化操作
- map(func)
- flatMap(func)
- filter (func)
- sample
- 集合操作union、intersection、subtract、cartesian
- 去重distinct()
- 行动操作
- reduce、fold、aggregate
- count()
- take(n)、top(n)
- collect()
- foreach(func)
- 持久化
- persist
- cache
RDD是一个不可变的分布式集合,每个RDD有 多个分区,它们分布在 集群不同的节点上。
转化操作不会立刻计算,只有当第一个
行动操作发生时spark才会进行计算,如果需要对同一个RDD进行反复
行动操作,最好先将其持久化一下 RDD.persist()
RDD 之所以成为“弹性”是因为在任何适合时候如果哪个分区挂掉了,它都能根据之前的操作步骤重算一下得到那个分区的数据,这个操作对用户是透明的
创建RDD
spark 提供了两种创建RDD的方式
- 从文件读取
python
lines = sc.textFile("README.md")
scala
val lines = sc.textFile("README.md")
- 对内存中的集合并行化
lines = sc.parallelize(["pandas", "i like pandas"]) #python
val lines = sc.parallelize(List("pandas", "i like pandas")) //scala
RDD操作
转化操作
惰性计算,碰到第一个行动操作才真正开始计算,返回RDD
map(func)
传入一个函数,并对RDD中每个元素执行这个函数,由函数运行结果组成新的RDD返回,返回的RDD与原来RDD的元素是一一对应的关系
python
nums = sc.parallelize([1, 2, 3, 4])
squared = nums.map(lambda x: x * x).collect()
for num in squared:
print "%i " % (num)
scala
val input = sc.parallelize(List(1, 2, 3, 4))
val result = input.map(x => x * x)
println(result.collect().mkString(","))
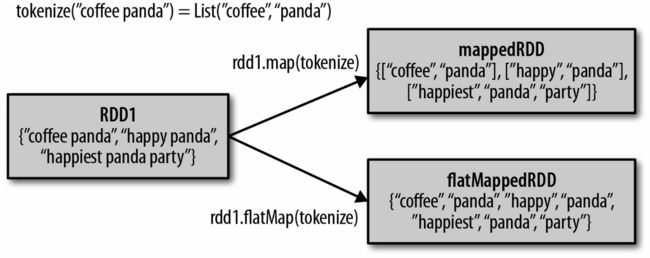
flatMap(func)
传入一个函数,并对RDD中每个元素执行这个函数,由函数运行的结果组成新的RDD,与map的区别是,如果函数返回多个结果,不会组成list,而是成为RDD中的多个元素
filter (func)
传入一个函数,返回布尔值,RDD中元素带入这个函数后运行结果为True的元素组成新的RDD返回
python
inputRDD = sc.textFile("log.txt")
errorsRDD = inputRDD.filter(lambda x: "error" in x)
scala
val inputRDD = sc.textFile("log.txt")
val errorsRDD = inputRDD.filter(line => line.contains("error"))
在python 中向spark传递函数时,如果传递的是某个对象的的函数或者函数内部引用了对象,python会把整个对象序列化一起传过去,最好换个方式,将所需的字段放入一个局部变量中。scala也差不多
class SearchFunctions(object):
def __init__(self, query):
self.query = query
def isMatch(self, s):
return self.query in s
def getMatchesFunctionReference(self, rdd):
# 问题:在"self.isMatch"中引用了整个self
return rdd.filter(self.isMatch)
def getMatchesMemberReference(self, rdd):
# 问题:在"self.query"中引用了整个self
return rdd.filter(lambda x: self.query in x)
def getMatchesNoReference(self, rdd):
# 安全:只把需要的字段提取到局部变量中
query = self.query
return rdd.filter(lambda x: query in x)
sample
rdd.sample(withReplacement=False, fraction=0.x, [seed])
withReplacement 表示是否又放回的抽样
fraction 表示抽样的比例,实际返回的数量不一定完全按这个比例,可能有点偏差,比如10个元素比例0.5 返回可能3、4、5、6个数据
集合操作union、intersection、subtract、cartesian
并集、交集、差集、笛卡尔积
用法相同 rdd3 = rdd1.union(rdd2)
笛卡尔积开销很大
errorsRDD = inputRDD.filter(lambda x: "error" in x)
warningsRDD = inputRDD.filter(lambda x: "warning" in x)
badLinesRDD = errorsRDD.union(warningsRDD)
spark 会用谱系图(lineage graph) 记录各个RDD之间的依赖关系,用来计算每个RDD,还可以用来恢复数据

去重distinct()
用法rdd.distinct() 开销很大
行动操作
行动操作会使spark计算需要依赖的转化操作,并且它的返回结果一般不是RDD。
reduce、fold、aggregate
reduce把一个函数作用在一个序列[x1, x2, x3, …]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算。
python 求累加和
sum = rdd.reduce(lambda x, y: x + y)
scala
val sum = rdd.reduce((x, y) => x + y)
fold 接受和reduce一样形式的函数,但是fold需要你提供一个第一次调用你所提供函数的初始值,可以理解为比reduce多调用了一次你的函数(实际没有调用,直接用了你给的初始值,一般加法0乘法1)
sum = rdd.fold(0,lambda x, y: x + y)
aggregate 和fold类似,但是你提供的第一个函数仅仅在每个分区被使用,最后每个分区都有一个最终的结果,还要提供一个函数将这些结果再合并起来
sum = rdd.aggregate(0,lambda x,y:x+y,lambda x,y:x+y)
count()
统计RDD 的元素个数
num = rdd.count()
take(n)、top(n)
获取一定量的元素,take无序,top采前n个
res = rdd.take(10)
collect()
获取所有元素,需要内存够大,数据集小可以用,慎用
res = rdd.collect()
foreach(func)
对rdd每个元素都执行操作,不需要返回值
持久化
当rdd或者dataframe 要被多次行动操作时,先持久化下
persist
persist(storageLevel=StorageLevel(True, True, False, False, 1))
persist可以传入的级别很多,默认MEMORY_AND_DISK,具体级别可以参考这里
cache
cache只有一个默认级别 MEMORY_AND_DISK