JS动态加载以及JavaScript void(0)的爬虫解决方案

Intro
对于使用JS动态加载, 或者将下一页地址隐藏为JavaScript void(0)的网站, 如何爬取我们要的信息呢?
本文以Chrome浏览器为工具, 36Kr为示例网站, 使用 Json Handle 作为辅助信息解析工具, 演示如何抓取此类网站.
Detail
Step 1. 按下 F12 或右键检查进入开发者工具
Step 2. 选中Network一栏, 筛选XHR请求
XHR 即 XMLHttpRequest, 可以异步或同步返回服务器响应的请求, 并且能够以文本或者一个 DOM 文档的形式返回内容.
JSON是一种与XML在格式上很像, 但是占用空间更小的数据交换格式, 全程是 JavaScript Object Notation, 本文中的36Kr动态加载时获取到的信息就是JSON类型的数据.
网站为了节省空间, 加快响应, 常常没有对 JSON 进行格式化, 导致 JSON 的可读性差, 难以寻找我们要的信息.
我们通过右键打开获取到的 XHR 请求, 然后看看数据是怎样的
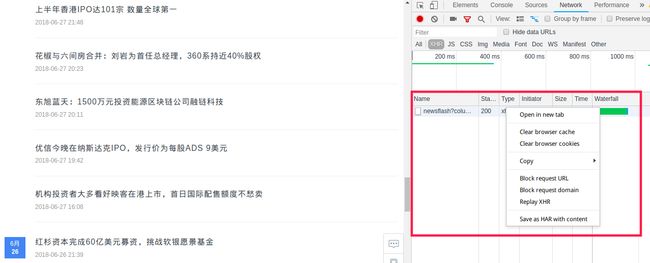

未使用JSON Handle前
使用后
使用 Json Handle 后的数据可读性就很高了
Step 3. 分析 URL
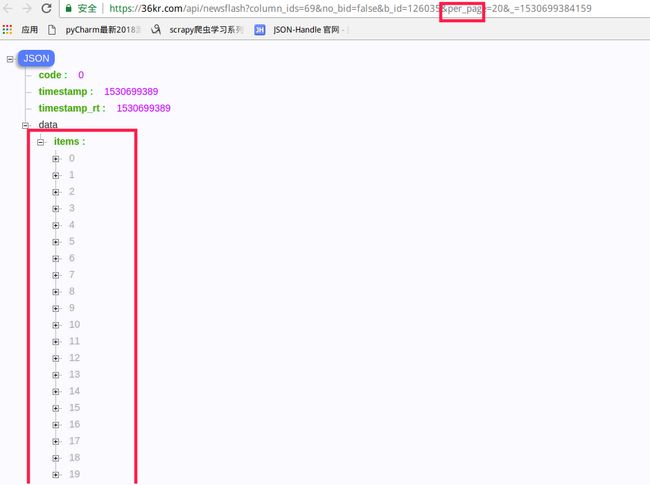
结合上面的截图, 分析这条 URLhttps://36kr.com/api/newsflash?column_ids=69&no_bid=false&b_id=126035&per_page=20&_=1530699384159
这中间有两个参数很容易可以知道它的用途, 第一个是per_page=20, 第二个是_=1530699384159
第一个参数是我们每次滚动后可以获取到的信息条数, 第二个是时间戳
试着改第一个参数改为10, 可以看到条数就变为10了.
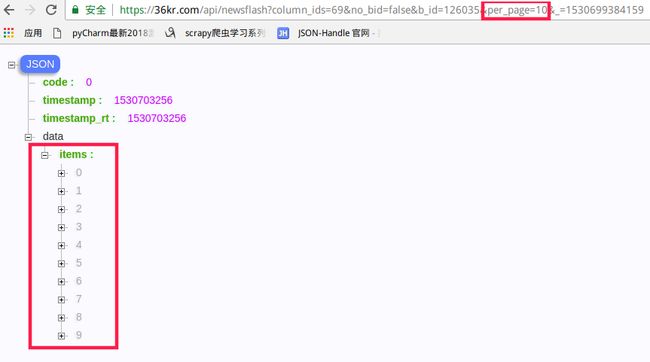
修改per_page
改为1000呢? 很遗憾, 最大值只有300. 换算下来, 就是最多允许爬 15 页
滑动了超过15页发现仍然有信息显示, 经过转换, 发现它的时间戳只是浏览网页生成的时间戳, 与内容无关
按了几个数字, 修改了b_id的值, 发现内容确实发生了改变, 但b_id又是网站设定的规则, 无从入手
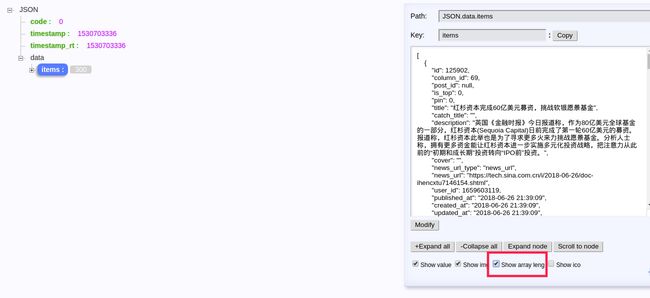
每次获取的最大值
改了no_bid为true似乎没有变化, 接着修改了column_id为70, 发现新闻的内容发生改变, 合理猜测这个应该是新闻标签的id.
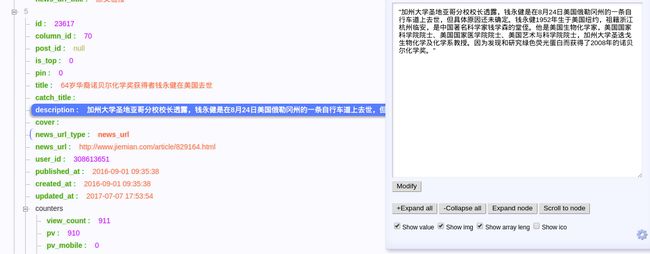
修改column_id
至此, 我们已大致了解整个 URL 的含义
per_page每次滑动可以获得的数据条目, 最大值为300column_ids新闻内容标签, 69为资本, 68为B轮后等b_id新闻集合的某种id时间戳记录当前的浏览时间
最后把原本的 URL 缩减为https://36kr.com/api/newsflash?column_ids=69&no_bid=true&b_id=&per_page=300
舍弃了b_id, 同时删去时间戳, 防止服务器发现每次接收到的请求时间都是一样的
经过测试, 上述的 URL 是可以获取信息的
Step 4. 开始爬虫
接下来的步骤与平时爬虫类似.
不同的是获取信息不再通过Xpath这些工具, 而是直接通过 JSON 取值
取值方式简单粗暴, 点击对应的内容就可以看路径了
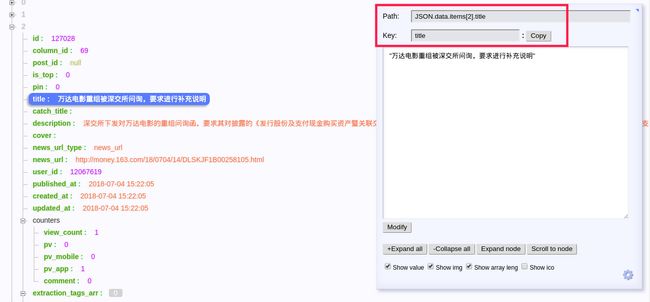
JSON Handle查看路径
接着用scrapy shell工具测试下正确性, 然后就可以写代码了.
由于新闻来源隐藏在description, 经过观察, 不难发现它的规律, 写一条正则获取即可, 如果结果为空, 则说明来源是36Krsrc_pattern = re.compile('。((.*))')
Source Code
Spider
# -*- coding: utf-8 -*-
import scrapy
import json
import re
from scrapy import Request
from ..items import FinvestItem
class A36krSpider(scrapy.Spider):
name = '36kr'
allowed_domains = ['36kr.com']
start_urls = ['https://36kr.com/api/newsflash?column_ids=69&no_bid=true&b_id=&per_page=300']
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
def start_request(self):
yield Request(self.start_urls, headers=self.headers)
def parse(self, response):
item = FinvestItem()
# 转化为 unicode 编码的数据
sites = json.loads(response.body_as_unicode())
src_pattern = re.compile('。((.*))')
for i in sites['data']['items']:
item['link'] = i['news_url']
item['title'] = i['title']
if src_pattern.search(i['description']) == None:
item['source'] = "36Kr"
else:
item['source'] = src_pattern.search(i['description']).group(1)
item['create_time'] = i['published_at']
item['content'] = i['description']
yield item
Pipeline
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
import re
from scrapy.conf import settings
class FinvestPipeline(object):
def __init__(self):
"""
use for connecting to mongodb
"""
# connect to db
self.client = pymongo.MongoClient(host=settings['MONGO_HOST'], port=settings['MONGO_PORT'])
# ADD if NEED account and password
# self.client.admin.authenticate(host=settings['MONGO_USER'], settings['MONGO_PSW'])
self.db = self.client[settings['MONGO_DB']]
self.coll = self.db[settings['MONGO_COLL']]
def process_item(self, item, spider):
content = item['content']
title = item['title']
fin = re.compile(r'(?:p|P)re-?(?:A|B)轮|(?:A|B|C|D|E)+?1?2?3?轮|(?:天使轮|种子|首)轮|IPO|轮|(?:p|Pre)IPO')
result = fin.findall(title)
if(len(result) == 0):
result = "未透露"
else:
result = ''.join(result)
content = content.replace(u'', u' ').replace(u'
', u' ').replace(u'\n\t', ' ').strip()
# delete html label in content
rule = re.compile(r'<[^>]+>', re.S)
content = rule.sub('', content)
item['content'] = content
item['funding_round'] = result
self.coll.insert(dict(item))
return item
GitHub项目地址 finvest-spider
正在建设和维护中, 欢迎 star 和 issue.