PySpark学习笔记(6)——数据处理
在正式建模之前,需要非常了解建模所要用到的数据,本文主要介绍一些常见的数据观测和处理方法。
1.数据观测
(1)统计数据表中每一列数据的缺失率
%pyspark
#构造原始数据样例
df = spark.createDataFrame([
(1,175,72,28,'M',10000),
(2,171,70,45,'M',None),
(3,172,None,None,None,None),
(4,180,78,33,'M',None),
(5,None,48,54,'F',None),
(6,160,45,30,'F',5000),
(7,169,65,None,'M',5000),],
['id','height','weight','age','gender','income'])
res_df = df.rdd.map(lambda x:x).map(list).collect()
#统计每列的数据缺失率
for i in range(6):
#获取第i列数据
columns = [item[i] for item in res_df]
#统计第i列数据中非空的数据数
count = sum([1 for item in columns if item])
#计算第i列的数据缺失率
missing_rate = 1 - count/len(res_df)
print("第{}列的数据缺失率为:{:.4f}%".format(i+1,missing_rate*100))
输出结果如下所示:

(2)统计指定列数据的详细信息
%pyspark
from pyspark.sql import functions as F
#构造原始数据样例
df = spark.createDataFrame([
(1,175,72,28,'M',10000),
(2,171,70,45,'M',8000),
(3,172,None,27,'F',7000),
(4,180,78,30,'M',4000),
(5,None,48,54,'F',6000),
(6,160,45,30,'F',5000),
(7,169,65,36,'M',7500),],
['id','height','weight','age','gender','income'])
#先基于gender分组,然后用各种聚合函数(max,min,mean,stddev)统计age列的信息
df_summary = sorted(df.groupBy(df.gender).agg(F.max(df.age),F.min(df.age),F.mean(df.age),F.stddev(df.age)).collect())
print(df_summary )
输出结果如下所示:
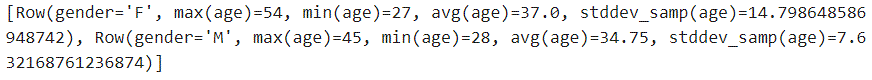
(3)获取DataFrame中Vector的数据信息
%pyspark
from pyspark.ml.linalg import Vectors
df = sc.parallelize([
("assert",Vectors.dense([1,2,3])),
("require",Vectors.sparse(3,{1:2})),
("announce",Vectors.sparse(3,{0:1,2:4}))
]).toDF(["word","vector"])
#提取DataFrame中的Vector中的数据信息
def extract(row):
return (row.word,) + tuple(row.vector.toArray().tolist())
res_df = df.rdd.map(extract).toDF(["word","v_1","v_2","v_3"])
res_df.show()
#获取指定列的数据
print(res_df.select("word","v_1").show())
输出结果如下所示:

2.数据处理
本部分主要记录一些数据处理的小技巧。
(1)为列表生成索引
%pyspark
#通过enumerate为col_list生成索引
col_list = ['username','id','gender','age']
mapping_list = list(enumerate(sorted(col_list)))
print(mapping_list)输出结果如下所示:
![]()
(2)将list转换成dict
%pyspark
#将mapping_list中的key和value互换位置,并转换为dict
revs_maplist = {value:idx for [idx,value] in mapping_list}
print(revs_maplist)输出结果如下所示:
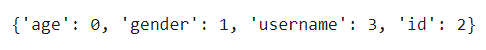
(3)嵌套for循环简写
%pyspark
test_list = [1,2,-3,10,None,-5,0,10.5]
#for循环简写1 (此处if在for循环后面)
result1 = [2*item for item in test_list if item != None]
print(result1)
#for循环简写2 (此处if-else必须同时存在且在for循环前面)
result2 = [1 if item > 0 else 0 for item in result1]
print(result2)输出结果如下所示:
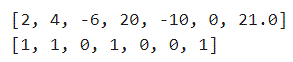
(4)以指定条件增加新列
%pyspark
from pyspark.sql import functions as F
#构造原始数据样例
df = spark.createDataFrame([
(1,175,72,28,'M',10000),
(2,171,70,45,'M',8000),
(3,172,None,None,'F',7000),
(4,180,78,33,'M',4000),
(5,None,48,54,'F',6000),
(6,160,45,30,'F',5000),
(7,169,65,None,'M',7500),],
['id','height','weight','age','gender','income'])
#1.给df增加一列数据'income2',income2 = income + 2000.
test1 = df.withColumn("income2",df.income + 2000)
#print(test1.show())
#2.给test1增加一列数据'label',当gender=='M'时,label=1,否则label=0.
test2 = test1.withColumn("label",F.when(test1.gender == 'M',1).otherwise(0))
#print(test2.show())
#3.给test2增加一列数据'thedate',其值固定为'2018-04-11'
test3 = test2.withColumn("thedate",F.lit('2018-04-11'))
print(test3.show())
输出结果如下所示:
