svm简单使用之数字识别
svm的使用还是很简单的,不用重复造轮子。svm可直接引用的库还是挺丰富的,比如下面两个:
LIBSVM是台湾大学林智仁,支持C、Java、Matlab、C#、Ruby、Python、R、Perl、Common LISP、Labview、php等数十种语言
Scikit-Learn是用Python开发的机器学习库. (svc, linersvc, nusvc, svr, nusvr, linersvr)
本文就以0-9数字识别为例,使用sk-learn库,介绍下svm的使用。数字识别方式很多,本文以图片每个像素点的灰度值作为特征,来识别数字的。如果28*28的图片,则特征有784维。
1.首先还是准备样本,样本还是最主要的。
训练数据5000张,测试数据2000张。将图像转为灰度图,将每个像素点的值保存到csv文件中。第一列为该图片的数字,后面的N列表示每个像素点的值。文件格式如下:

2. 导入包
import pandas as pd #读取csv文件 from sklearn import svm #svm包 from sklearn.externals import joblib #保存模型 from sklearn.decomposition import PCA #降维 import time #计算训练时间
3.读取模型,开始训练
if __name__ =="__main__": train_num = 5000 test_num = 7000 data = pd.read_csv('train.csv') train_data = data.values[0:train_num,1:] train_label = data.values[0:train_num,0] #第一列为样本值 test_data = data.values[train_num:test_num,1:] test_label = data.values[train_num:test_num,0] #第一列为样本值 t = time.time() # svm训练 print('start svc...') svc = svm.SVC(kernel = 'rbf', C = 10) #svm是二分类,svc支持多分类 svc.fit(train_data,train_label) pre = svc.predict(test_data) #保存模型 joblib.dump(svc, 'model.m') # 计算准确率 score = svc.score(test_data, test_label) print(u'准确率:%f,花费时间:%.2fs' % (score, time.time() - t))
svc参数kernel表示使用的核函数,rbf为高斯核函数,C为惩罚系数。其他参数详解(下一贴)
上面的训练因为图片是28*28的,有784维还是要点时间的。而且维度越高,svm训练出来的模型越大,如果模型是放到移动端来使用是希望越小越好的。所以为了使模型变小、训练速度快,可以PCA进行降维。
4.加上PCA
if __name__ =="__main__": train_num = 5000 test_num = 7000 data = pd.read_csv('train.csv') train_data = data.values[0:train_num,1:] train_label = data.values[0:train_num,0] test_data = data.values[train_num:test_num,1:] test_label = data.values[train_num:test_num,0] t = time.time() #PCA降维 pca = PCA(n_components=0.8, whiten=True) print('start pca...') train_x = pca.fit_transform(train_data) test_x = pca.transform(test_data) print(train_x.shape) # svm训练 print('start svc...') svc = svm.SVC(kernel = 'rbf', C = 10) svc.fit(train_x,train_label) pre = svc.predict(test_x) #保存模型 joblib.dump(svc, 'model.m') joblib.dump(pca, 'pca.m') # 计算准确率 score = svc.score(test_x, test_label) print(u'准确率:%f,花费时间:%.2fs' % (score, time.time() - t))
n_components=0.8表示保留80%的信息,如果直接用数值n_components=50则表示降到50维。True表示做白化处理, 白化处理主要是为了使处理后的数据方差都一致。
5.训练结果
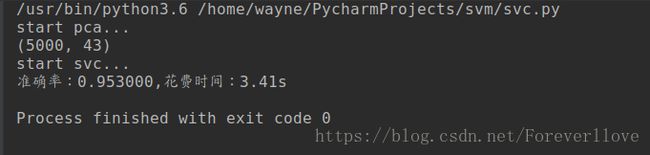
6.使用训练出来的模型进行数字识别
from sklearn.externals import joblib import cv2 as cv if __name__ =="__main__": img = cv.imread("/home/wayne/temp/mnist/6.1932.jpg", 0) test = img.reshape(1,784) #加载模型 svc = joblib.load("model.m") pca = joblib.load("pca.m") # svm print('start pca...') test_x = pca.transform(test) pre = svc.predict(test_x) print(pre)
项目地址