Python 打造基于百度翻译的命令行翻译工具
Python 打造基于百度翻译的命令行翻译工具
由于英文水平一般,所以还是非常依赖翻译工具的。fanyi.baidu.com 都成了我浏览器必开的网页之一了。昨天项目上线,等待过程中,无聊写了一个基于百度翻译 api 的命令行翻译工具。但是效果不是很令我满意,因为它给了一个翻译结果,而没有像网站上那样,给我更多的翻译结果作为参考。
最关键的是,这么个破接口,百度居然还是收费的。虽然免费200万次调用对于我来说是绰绰有余的了。
还是接口返回的结果不另我满意,于是,我在想,能不能爬取一下百度翻译的网站,然后以此来写一个翻译工具。
感谢简书网友 HONGQUAN 提供的《百度翻译最新接口破解》、《百度翻译接口实例解析》两篇文章给我的参考。
我下载了 HONGQUAN 提供的 python 源码,修改后保存为 baidu.py,作为我的代码的引用库
最近我写的这个百度翻译的工具不能用了。我又写了一个基于有道的。https://blog.csdn.net/FungLeo/article/details/82787744
python 百度翻译查询结果返回代码
#!/usr/bin/env python
# encoding: utf-8
"""
@file: BaiDu.py
@time: 2018/5/7 17:11
@desc: 百度翻译接口破解
@author: [email protected]
"""
import sys
import re
import requests
import execjs
import urllib
import json
def baidu (source, sLang, tLang):
# 获取 sign 和 token
gtk = ""
token = ""
# 获取网页源码
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36",
"Cookie": "'locale=zh; BAIDUID=FC2689968A662FA6104AA311FE89635B:FG=1; from_lang_often=%5B%7B%22value%22%3A%22en%22%2C%22text%22%3A%22%u82F1%u8BED%22%7D%2C%7B%22value%22%3A%22zh%22%2C%22text%22%3A%22%u4E2D%u6587%22%7D%5D; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; to_lang_often=%5B%7B%22value%22%3A%22zh%22%2C%22text%22%3A%22%u4E2D%u6587%22%7D%2C%7B%22value%22%3A%22en%22%2C%22text%22%3A%22%u82F1%u8BED%22%7D%5D'",
}
html = requests.get('http://fanyi.baidu.com', headers=header)
html.encoding = 'utf-8'
# 获取 gtk
matches = re.findall("window.gtk = '(.*?)';", html.text, re.S)
for match in matches:
gtk = match
# 正则匹配 token
matches = re.findall("token: '(.*?)'", html.text, re.S)
for match in matches:
token = match
if token == "":
print('Get token fail.')
exit()
# 计算 sign
signCode = 'function a(r,o){for(var t=0;t="a"?a.charCodeAt(0)-87:Number(a),a="+"===o.charAt(t+1)?r>>>a:r<30&&(r=""+r.substr(0,10)+r.substr(Math.floor(o/2)-5,10)+r.substr(-10,10));var t=void 0,t=null!==C?C:(C=_gtk||"")||"";for(var e=t.split("."),h=Number(e[0])||0,i=Number(e[1])||0,d=[],f=0,g=0;gm?d[f++]=m:(2048>m?d[f++]=m>>6|192:(55296===(64512&m)&&g+1>18|240,d[f++]=m>>12&63|128):d[f++]=m>>12|224,d[f++]=m>>6&63|128),d[f++]=63&m|128)}for(var S=h,u="+-a^+6",l="+-3^+b+-f",s=0;sS&&(S=(2147483647&S)+2147483648),S%=1e6,S.toString()+"."+(S^h)}'
sign = execjs.compile(signCode).call('hash', source, gtk)
# 请求接口
v2transapi = 'http://fanyi.baidu.com/v2transapi?from=%s&to=%s&query=%s' \
'&transtype=translang&simple_means_flag=3&sign=%s&token=%s' % (sLang, tLang, urllib.parse.quote(source), sign, token)
translate_result = requests.get(v2transapi, headers=header)
return json.loads(translate_result.text)
命令行翻译工具主文件
#!/usr/bin/env python3
# -*- coding: UTF-8 -*-
import os
import requests
import json
import argparse
from prettytable import PrettyTable
# 引用 baidu.py 文件
from baidu import baidu
# 通过百度的免费接口判断输入的词语是中文还是英文
def checkLang (word):
langForm = {'query': word}
r = requests.post('http://fanyi.baidu.com/langdetect', data=langForm)
if r.status_code == 200:
res = json.loads(r.text)
if res['lan'] == 'en':
sLang = 'en'
tLang = 'zh'
else:
sLang = 'zh'
tLang = 'en'
return [baidu(word, sLang, tLang), sLang]
else:
print('Api Error')
exit()
# 将翻译结果输出
def fanyi(word, goNext):
checkRes = checkLang(word)
res = checkRes[0]
sLang = checkRes[1]
if 'trans_result' in res:
tRes = res['trans_result']
tableHead = ['原词', word]
x = PrettyTable(tableHead)
x.padding_width = 1
x.align = 'l'
print('\n\033[1;36m简单结果\033[0m')
for k, i in enumerate(tRes['data']):
x.add_row(['结果', i['dst']])
print(x)
if 'dict_result' in res:
dRes = res['dict_result']
if 'simple_means' in dRes:
sdRes = dRes['simple_means']
if 'word_means' in sdRes:
print('\n\033[1;36m更多翻译\033[0m')
x = PrettyTable()
x.header = False
x.add_row(sdRes['word_means'])
print(x)
if goNext:
print('\n')
inputWord(False)
# 如果没有缀参数,则进入连续翻译模式
def inputWord (isFirst):
if isFirst:
print('\n\033[1;36m英汉互译词典\033[0m by FungLeo')
print('\033[35mTip:退出程序请输入 \033[1;31mexit\033[4;0m\n')
word = input('请输入要翻译的内容:')
if word == 'exit':
print('\033[0m很高兴为您服务')
exit()
else:
fanyi(word, True)
# 主函数
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.description='Python 编写的基于百度翻译的命令行翻译工具。支持缀参数直接翻译,如有空格,请用引号包含,或不带参数直接进入连续翻译模式。'
parser.add_argument("-v", "--version", action='version', version='%(prog)s 1.0')
parser.add_argument('word', type=str, help='需要翻译的单词', nargs='?')
args = parser.parse_args()
if args.word != None:
fanyi(args.word, False)
else:
inputWord(True)
最终效果展示
显示帮助以及版本号
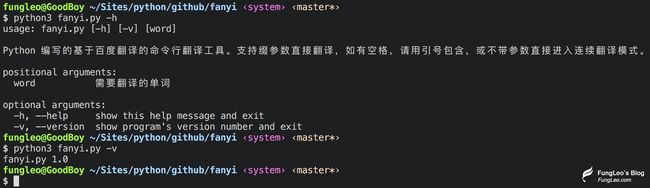
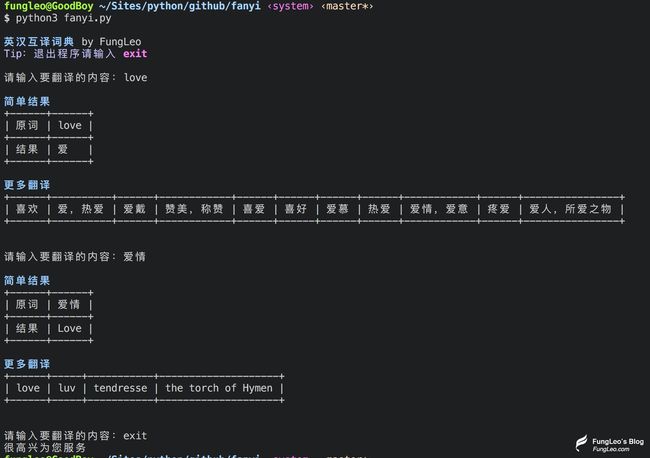
连续翻译模式
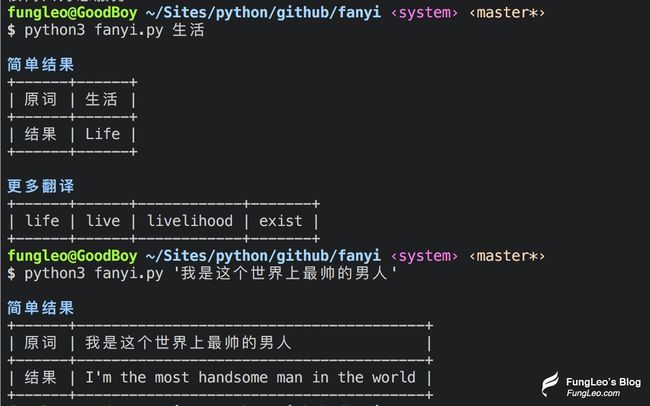
参数翻译模式
其他
github 源码地址:https://github.com/fengcms/python-learn-demo/blob/master/fanyi/fanyi.py
本文由 FungLeo 原创,允许转载,但转载必须保留首发链接。