用一个小游戏入门深度强化学习
今天我们来用深度强化学习算法 deep Q-learning 玩 CartPole 游戏。
强化学习是机器学习的一个重要分支,通过强化学习我们可以创建一个 agent,让它与环境不断地互动,不断试错,自主地从中学习到知识,进而做出决策。
如图所示,agent 收到环境的状态 state,做出行动 action,行动后会得到一个反馈,反馈包括奖励 reward 和环境的下一个状态 next_state。
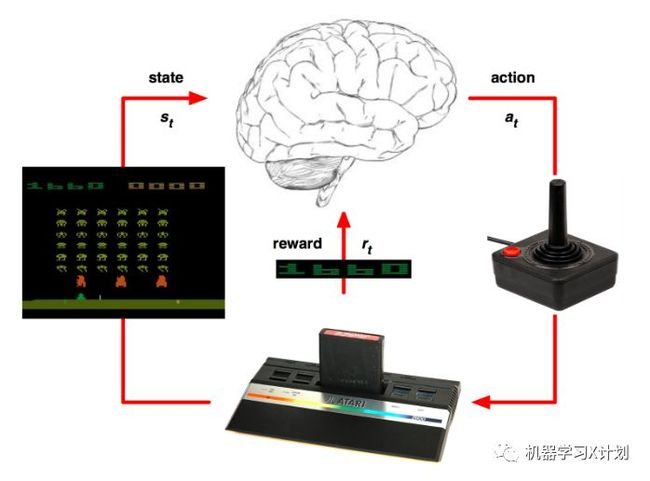
推荐阅读:一文了解强化学习
在强化学习中有一个著名算法 Q-learning:

推荐阅读:什么是 Q-learning
2013 年,Google DeepMind 发表了论文 Playing Atari with Deep Reinforcement Learning,开辟了一个新的领域,深度学习和强化学习的结合,即深度强化学习。 其中介绍了 Deep Q Network,这个深度强化学习网络可以让 agent 仅仅通过观察屏幕就能学会玩游戏,不需要知道关于这个游戏的任何信息。
在 Q-Learning 算法中,是通过一个 Q 函数,来估计对一个状态采取一个行动后所能得到的奖励 Q(s,a),
接下来我们用一个很简单的游戏来看 Deep Q Network 是如何应用的。
CartPole 这个游戏的目标是要使小车上面的杆保持平衡,
state 包含四个信息:小车的位置,车速,杆的角度,杆尖端的速度
在每轮游戏开始时,环境有一个初始的状态,
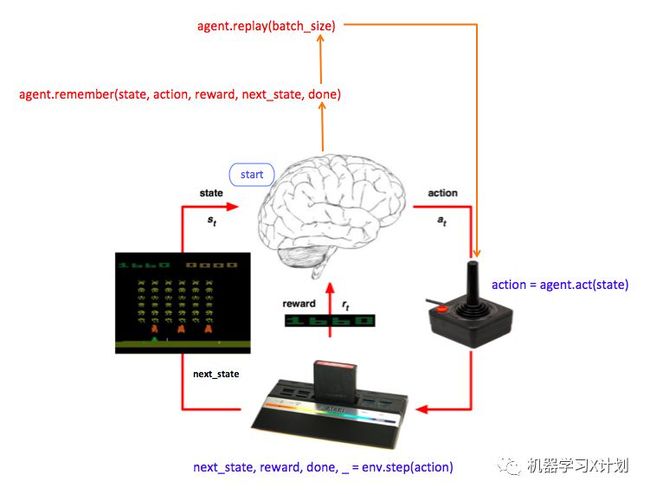
agent 根据状态采取一个行动
action = agent.act(state),这个 action 使得游戏进入下一个状态
next_state,并且拿到了奖励reward,next_state, reward, done, _ = env.step(action),然后 agent 会将之前的经验记录下来
agent.remember(state, action, reward, next_state, done),当经验积累到一定程度后,agent 就从经验中学习改进
agent.replay(batch_size),如果游戏结束了就打印一下所得分数,
state = next_state
if __name__ == "__main__":
# 初始化 gym 环境和 agent
env = gym.make('CartPole-v1')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
agent = DQNAgent(state_size, action_size)
done = False
batch_size = 32
# 开始迭代游戏
for e in range(EPISODES):
# 每次游戏开始时都重新设置一下状态
state = env.reset()
state = np.reshape(state, [1, state_size])
# time 代表游戏的每一帧,
# 每成功保持杆平衡一次得分就加 1,最高到 500 分,
# 目标是希望分数越高越好
for time in range(500):
# 每一帧时,agent 根据 state 选择 action
action = agent.act(state)
# 这个 action 使得游戏进入下一个状态 next_state,并且拿到了奖励 reward
# 如果杆依旧平衡则 reward 为 1,游戏结束则为 -10
next_state, reward, done, _ = env.step(action)
reward = reward if not done else -10
next_state = np.reshape(next_state, [1, state_size])
# 记忆之前的信息:state, action, reward, and done
agent.remember(state, action, reward, next_state, done)
# 更新下一帧的所在状态
state = next_state
# 如果杆倒了,则游戏结束,打印分数
if done:
print("episode: {}/{}, score: {}, e: {:.2}"
.format(e, EPISODES, time, agent.epsilon))
break
# 用之前的经验训练 agent
if len(agent.memory) > batch_size:
agent.replay(batch_size)接下来具体看每个部分:
1. agent 的网络用一个很简单的结构为例:

在输入层有 4 个节点,用来接收 state 的 4 个信息:小车的位置,车速,杆的角度,杆尖端的速度,
def _build_model(self):
model = Sequential()
model.add(Dense(24, input_dim=self.state_size, activation='relu'))
model.add(Dense(24, activation='relu'))
model.add(Dense(self.action_size, activation='linear'))
model.compile(loss='mse',
optimizer=Adam(lr=self.learning_rate))
return model2. 需要定义一个损失函数来表示预测的 reward 和实际得到的奖励值的差距,这里用 mse,
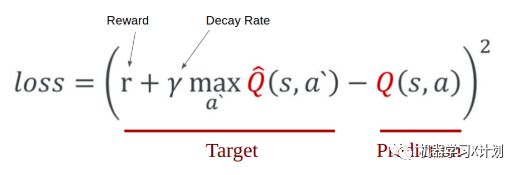
例如,杆现在向右倾斜,这时如果向右推小车,那么杆就可能继续保持平衡,游戏的分数就可以更高一些,也就是说向右推车比向左推车拿到的奖励要大,不过模型却预测成了向左推奖励大,这样就造成了差距,我们需要让差距尽量最小。
3. Agent 如何决定采取什么 action
游戏开始时为了让 agent 尽量多尝试各种情况,会以一定的几率 epsilon 随机地选择 action,np.argmax() 选择能最大化奖励的 action,act_values[0] = [0.67, 0.2] 表示 aciton 为 0 和 1 时的 reward,这个的最大值的索引为 0.
def act(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
act_values = self.model.predict(state)
return np.argmax(act_values[0]) # returns action4. 通过 Gym,agent 可以很轻松地就能与环境互动:
next_state, reward, done, info = env.step(action)
env 代表游戏环境,action 为 0 或 1,将 action 传递给环境后,返回: done 表示游戏是否结束,next_state 和 reward 用来训练 agent。
DQN 的特别之处在于 remember 和 replay 方法,
5. remember()
DQN 的一个挑战是,上面搭建的这个神经网络结构是会遗忘之前的经验的,因为它会不断用新的经验来覆盖掉之前的。
memory = [(state, action, reward, next_state, done)...]
存储的动作由 remember() 函数来完成,即将 state, action, reward, next state 附加到 memory 中。
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))6. replay()
replay() 是用 memory 来训练神经网络的方法。
首先从 memory 中取样,从中随机选取
batch_size个数据:
minibatch = random.sample(self.memory, batch_size)
为了让 agent 能有长期的良好表现,我们不仅仅要考虑即时奖励,还要考虑未来奖励,即需要折扣率 gamma,
具体讲就是我们先采取了行动 a,然后得到了奖励 r,并且到达了一个新的状态 next s,np.amax(),
target = reward + gamma * np.amax(model.predict(next_state))
target_f为前面建立的神经网络的输出,也就是损失函数里的Q(s,a),然后模型通过 fit() 方法学习输入输出数据对,
model.fit(state, reward_value, epochs=1, verbose=0)
def replay(self, batch_size):
minibatch = random.sample(self.memory, batch_size)
for state, action, reward, next_state, done in minibatch:
target = reward
if not done:
target = (reward + self.gamma *
np.amax(self.model.predict(next_state)[0]))
target_f = self.model.predict(state)
target_f[0][action] = target
self.model.fit(state, target_f, epochs=1, verbose=0)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay完整代码如下:
# -*- coding: utf-8 -*-
import random
import gym
import numpy as np
from collections import deque
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
EPISODES = 1000 # 让 agent 玩游戏的次数
class DQNAgent:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
self.memory = deque(maxlen=2000)
self.gamma = 0.95 # 计算未来奖励时的折算率
self.epsilon = 1.0 # agent 最初探索环境时选择 action 的探索率
self.epsilon_min = 0.01 # agent 控制随机探索的阈值
self.epsilon_decay = 0.995 # 随着 agent 玩游戏越来越好,降低探索率
self.learning_rate = 0.001
self.model = self._build_model()
def _build_model(self):
model = Sequential()
model.add(Dense(24, input_dim=self.state_size, activation='relu'))
model.add(Dense(24, activation='relu'))
model.add(Dense(self.action_size, activation='linear'))
model.compile(loss='mse',
optimizer=Adam(lr=self.learning_rate))
return model
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def act(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
act_values = self.model.predict(state)
return np.argmax(act_values[0])
def replay(self, batch_size):
minibatch = random.sample(self.memory, batch_size)
for state, action, reward, next_state, done in minibatch:
target = reward
if not done:
target = (reward + self.gamma *
np.amax(self.model.predict(next_state)[0]))
target_f = self.model.predict(state)
target_f[0][action] = target
self.model.fit(state, target_f, epochs=1, verbose=0)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
if __name__ == "__main__":
# 初始化 gym 环境和 agent
env = gym.make('CartPole-v1')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
agent = DQNAgent(state_size, action_size)
done = False
batch_size = 32
# 开始迭代游戏
for e in range(EPISODES):
# 每次游戏开始时都重新设置一下状态
state = env.reset()
state = np.reshape(state, [1, state_size])
# time 代表游戏的每一帧,
# 每成功保持杆平衡一次得分就加 1,最高到 500 分,
# 目标是希望分数越高越好
for time in range(500):
# 每一帧时,agent 根据 state 选择 action
action = agent.act(state)
# 这个 action 使得游戏进入下一个状态 next_state,并且拿到了奖励 reward
# 如果杆依旧平衡则 reward 为 1,游戏结束则为 -10
next_state, reward, done, _ = env.step(action)
reward = reward if not done else -10
next_state = np.reshape(next_state, [1, state_size])
# 记忆之前的信息:state, action, reward, and done
agent.remember(state, action, reward, next_state, done)
# 更新下一帧的所在状态
state = next_state
# 如果杆倒了,则游戏结束,打印分数
if done:
print("episode: {}/{}, score: {}, e: {:.2}"
.format(e, EPISODES, time, agent.epsilon))
break
# 用之前的经验训练 agent
if len(agent.memory) > batch_size:
agent.replay(batch_size)学习资料:
推荐 阅读原文
也许可以找到你想要的:
[入门问题][TensorFlow][深度学习][强化学习][神经网络][机器学习][自然语言处理][聊天机器人]