深度学习Deep Learning: dropout策略防止过拟合
本文参考 hogo在youtube上的视频 :https://www.youtube.com/watch?v=UcKPdAM8cnI
一、理论基础
dropout的提出是为了防止在训练过程中的过拟合现象,那就有人想了,能不能对每一个输入样本训练一个模型,然后在test阶段将每个模型取均值,这样通过所有模型共同作用,可以将样本最有用的信息提取出来,而把一些噪声过滤掉。
那如何来实现这种想法呢?在每一轮训练过程中,我们对隐含层的每个神经元以一定的概率p舍弃掉,这样相当于每一个样本都训练出一个模型。假设有H个神经元,那么就有2H种可能性,对应2H模型,训练起来时间复杂度太高。我们通过权重
共享(weights sharing)的方法来简化训练过程,每个样本所对应模型是部分权重共享的,只有被舍弃掉那部分权重不同。
使用dropout可以使用使一个隐含结点不能与其它隐含结点完全协同合作,因此其它的隐含结点可能被舍弃,这样就不能通过所有的隐含结点共同作用训练出复杂的模型(只针对某一个训练样本),我们不能确定其它隐含结点此时是否被激活,这样
就有效的防止了过拟合现象。
如下图所示,在训练过程中神经元以概率p出现,而在测试阶段它一直都存在。
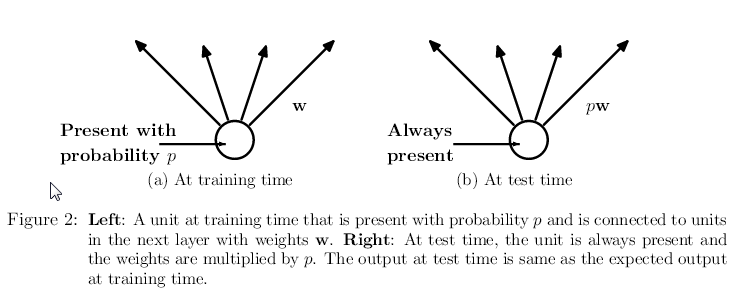
注:如果有多个隐含层,那么对每一个隐含层分别使用dropout策略
1.1 训练阶段
forward propagation
在前向传播过程中,使用掩模m(k)uq将部分隐含层结点舍弃。
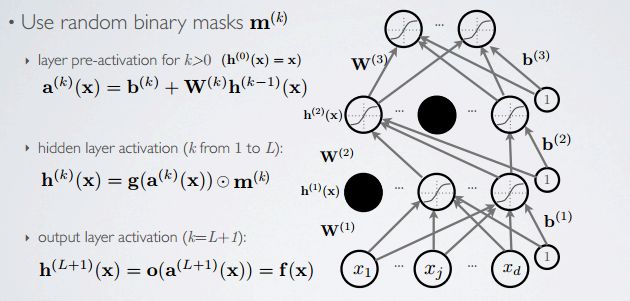
backpropagation
反向传播阶段,即权重调整阶段,通过掩模只调整那些未被舍弃的结点的权重。

1.2 测试阶段
在前面介绍过,我们可能训练出很多种模型,在测试阶段对其取平均,有两种取平均的方法:
假设有两个模型m1,m2,输出分别为O1,O2,最终输出为O
1、mixture
O = (O1+O2) / 2
2、product (geometric mean)
O = sqrt( O1*O2 )
以上这两种方法都是非常耗时的,我们使用一种挖的方法,即对模型的输出乘以0.5(假设dropout的概率是0.5),如果仅包含一个隐含结点,那么这种方法与geometric mean结果相同,反之,也可以很好的近似。
如果dropout的概率是0.5,那么就对所有输出乘以0.5,
dropout是在每一轮的权重调整时(backpropagation时)在隐含层以一定的概率舍弃某些神经元(一般取0.5),因此每个神经元只以上一层的一部分神经元相关,即隐含层每个神经元相当于单独训练,即每个神经元模型独立。
1.3 对输入层的dropout
以上讲的是如何在隐含层做dropout,其实也可以在输入层做dropout,这就是前面提到的denoising策略,只是我们以比较大的概率将输入保留下来 。
1.4 denoising and dropout
- denoising用于输入层,dropout用于隐含层
- denoising是用于无监督训练,dropout用于有监督训练,denoising可用于有监督训练的预训练过程。
- 两者都用来防止过拟合
二、实验部分
本实验使用deepLearnToolbox 工具包,将autoencoder模型使用dropout前后的结果进行比较。
dropout并没有明显的降低误差率,可能需要调参吧。。作者在论文中的效果非常之明显。
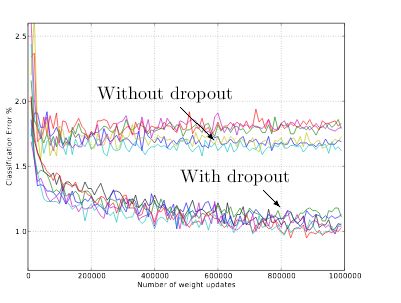
误差率:
without dropout 0.18300
with dropout : 0.144000
实验主要代码:
nn.dropoutFraction = 0.5; 用来设置dropout的百分比,一般0.5的效果最好。
load mnist_uint8;
train_x = double(train_x(1:2000,:)) / 255;
test_x = double(test_x(1:1000,:)) / 255;
train_y = double(train_y(1:2000,:));
test_y = double(test_y(1:1000,:));
%% //实验一without dropout
rand('state',0)
sae = saesetup([784 100]);
sae.ae{1}.activation_function = 'sigm';
sae.ae{1}.learningRate = 1
opts.numepochs = 10;
opts.batchsize = 100;
sae = saetrain(sae , train_x , opts );
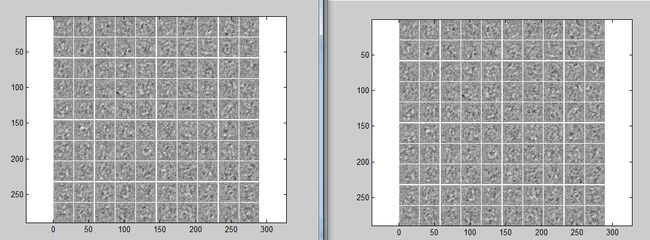
visualize(sae.ae{1}.W{1}(:,2:end)');
nn = nnsetup([784 100 10]);% //初步构造了一个输入-隐含-输出层网络,其中包括了
% //权值的初始化,学习率,momentum,激发函数类型,
% //惩罚系数,dropout等
nn.W{1} = sae.ae{1}.W{1};
opts.numepochs = 10; % //Number of full sweeps through data
opts.batchsize = 100; % //Take a mean gradient step over this many samples
[nn, L] = nntrain(nn, train_x, train_y, opts);
[er, bad] = nntest(nn, test_x, test_y);
str = sprintf('testing error rate is: %f',er);
disp(str)
%% //实验二:with dropout
rand('state',0)
sae = saesetup([784 100]);
sae.ae{1}.activation_function = 'sigm';
sae.ae{1}.learningRate = 1;
opts.numepochs = 10;
opts.bachsize = 100;
sae = saetrain(sae , train_x , opts );
figure;
visualize(sae.ae{1}.W{1}(:,2:end)');
nn = nnsetup([784 100 10]);% //初步构造了一个输入-隐含-输出层网络,其中包括了
% //权值的初始化,学习率,momentum,激发函数类型,
% //惩罚系数,dropout等
nn.dropoutFraction = 0.5;
nn.W{1} = sae.ae{1}.W{1};
opts.numepochs = 10; % //Number of full sweeps through data
opts.batchsize = 100; % //Take a mean gradient step over this many samples
[nn, L] = nntrain(nn, train_x, train_y, opts);
[er, bad] = nntest(nn, test_x, test_y);
str = sprintf('testing error rate is: %f',er);
disp(str)
参考文献:
hintin dropout youtube视频:https://www.youtube.com/watch?v=5t-mVtrFVyY
hogo dropout youtube视频:https://www.youtube.com/watch?v=UcKPdAM8cnI
deepLearn Toolbox使用: http://www.cnblogs.com/dupuleng/articles/4340293.html
hinton原文 Dropout: A simple Way to prevent Neural Networks from Overfitting
from: http://www.cnblogs.com/dupuleng/articles/4341265.html