Tensorflow实现策略网络(深度强化学习一)
1.深度强化学习简介
强化学习(Reinforcement Learing)是机器学习的一个重要分支,主要用来解决连续决策的问题。强化学习可以在复杂的,不确定的环境中学习如何实现我们设定的目标。
一个强化学习问题包含三个主要概念,即环境状态(Environment State),行动(Action),奖励(Reward)。强化学习的目标就算获得最多的累计奖励。
回顾下,AutoEncoder属于无监督学习,而MLP,CNN,RNN都属于监督学习,但强化学习跟这两种都不同。它不像无监督学习那样完全没有学习目标,也不像监督学习那样有非常明确的目标(即label),强化学习的目标一般是变化的,不明确的,甚至可能不存在绝对正确的标签 。
2.策略网络
所谓的策略网络,即建立一个神经网络模型,它可以通过观察环境状态,直接预测出目前最应该执行的策略(policy),执行这个策略可以获得最大的期望收益(包括现在的和未来的reward)。和之前的任务不同,在强化学习中可能没有绝对正确的学习目标,样本的feature和label也不在一一对应。我们的学习目标是期望价值,即当前获得的reward和未来潜在的可获取的reward。所以在策略网络中不只是使用当前的reward作为label,而是使用Discounted Future Reward,即把所有未来奖励一次乘以衰减系数γ。这里的衰减系数是一个略小于但接近1的数,防止没有损耗地积累导致Reward目标发散,同时也代表了对未来奖励的不确定性的估计。
3.Gym
Gym是OpenAI推出的开源的强化学习的环境生成工具。在Gym中有两个核心的概念,一个是Environment,指我们的任务或者问题,另一个就是Agent,即我们编写的策略或者算法。Agent会将执行的Action传给Environment,Environment接受某个Action后,再将结果Observation(即环境状态)和Reward返回给Agent。
安装:
sudo pip3 install gym4.代码实现
下面就使用Tensorflow创建一个基于策略网络的Agent来解决CartPole问题。本节代码主要来自DeepRL-Agents的开源实现。
# !/usr/bin/python3
# -*- coding:utf-8 -*-
# 使用Tensorflow创建一个基于策略网络的Agent来解决CartPole问题
import numpy as np
import tensorflow as tf
import gym
env = gym.make('CartPole-v0') # 创建cartpole问题的环境env
# 初始化环境
env.reset()
random_episodes = 0
reward_sum = 0
# 进行10次随机实验
while random_episodes < 10:
env.render() # 将cartpole问题的图像渲染出来
# np.random.randint(0,2)产生随机的action,env.step(action)执行随机action
observation,reward,done,_ = env.step(np.random.randint(0,2)) # done为True则本次试验结束
reward_sum += reward
if done:
random_episodes += 1
print("Reward for this episode was:",reward_sum)
reward_sum = 0
env.reset() # 重启环境运行结果如下:
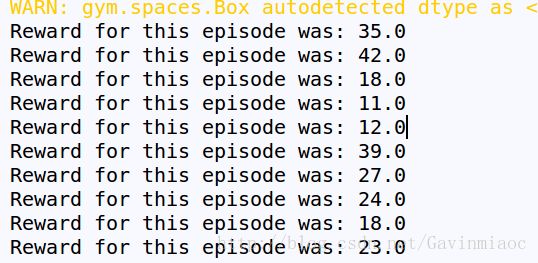
可以看到随机策略获得的奖励总值差不多在10~45之间,均值应该在20~35,这将作为接下来用来对比的基准。我们将任务完成的目标设定为拿到200的Reward,并希望通过尽量少次数的试验来完成这个目标。
我们的策略网络使用简单的带有一个隐含层的MLP。具体代码如下
# !/usr/bin/python3
# -*- coding:utf-8 -*-
# 使用Tensorflow创建一个基于策略网络的Agent来解决CartPole问题
import numpy as np
import tensorflow as tf
import gym
env = gym.make('CartPole-v0') # 创建cartpole问题的环境env
# 初始化环境
env.reset()
random_episodes = 0
reward_sum = 0
# 进行10次随机实验
while random_episodes < 10:
env.render() # 将cartpole问题的图像渲染出来
# np.random.randint(0,2)产生随机的action,env.step(action)执行随机action
observation,reward,done,_ = env.step(np.random.randint(0,2)) # done为True则本次试验结束
reward_sum += reward
if done:
random_episodes += 1
print("Reward for this episode was:",reward_sum)
reward_sum = 0
env.reset() # 重启环境
# hyperparameters超参数设置
H = 50 # number of hidden layer neurons 隐含节点数
batch_size = 25 # every how many episodes to do a param update?
learning_rate = 1e-1 # feel free to play with this to train faster or more stably.
gamma = 0.99 # discount factor for reward 奖励的衰减系数
D = 4 # input dimensionality 环境信息observation的维度为4
tf.reset_default_graph()
# This defines the network as it goes from taking an observation of the environment to
# giving a probability of chosing to the action of moving left or right.
# 神经网络的输入环境的状态,并且输出左/右的概率
observations = tf.placeholder(tf.float32, [None, D], name="input_x")
# 初始化算法,创建隐含权重w1,其维度为[D,H]
W1 = tf.get_variable("W1", shape=[D, H],
initializer=tf.contrib.layers.xavier_initializer())
# relu激活函数处理得到隐含层输出layer1,注意我们不需要加偏置
layer1 = tf.nn.relu(tf.matmul(observations, W1))
# 创建sigmoid输出层的权重W2
W2 = tf.get_variable("W2", shape=[H, 1],
initializer=tf.contrib.layers.xavier_initializer())
score = tf.matmul(layer1, W2)
# 使用sigmoid激活函数处理得到最后的输出概率
probability = tf.nn.sigmoid(score)
# From here we define the parts of the network needed for learning a good policy.
tvars = tf.trainable_variables() # 获取策略网络中全部可训练的参数tvars
input_y = tf.placeholder(tf.float32, [None, 1], name="input_y") # 人工设置的虚拟label
advantages = tf.placeholder(tf.float32, name="reward_signal") # 每个action的潜在价值
# The loss function. This sends the weights in the direction of making actions
# that gave good advantage (reward over time) more likely, and actions that didn't less likely.
# loglik其实就是当前Action对应的概率的对数
loglik = tf.log(input_y * (input_y - probability) + (1 - input_y) * (input_y + probability))
loss = -tf.reduce_mean(loglik * advantages) # 损失
newGrads = tf.gradients(loss, tvars) # 求解模型参数关于loss的梯度
# 为了减少奖励函数中的噪声,我们累积一系列的梯度之后才会更新神经网络的参数
# Once we have collected a series of gradients from multiple episodes, we apply them.
# We don't just apply gradeients after every episode in order to account for noise in the reward signal.
adam = tf.train.AdamOptimizer(learning_rate=learning_rate) # Our optimizer
W1Grad = tf.placeholder(tf.float32,
name="batch_grad1") # Placeholders to send the final gradients through when we update.
W2Grad = tf.placeholder(tf.float32, name="batch_grad2")
batchGrad = [W1Grad, W2Grad]
# 更新模型参数
updateGrads = adam.apply_gradients(zip(batchGrad, tvars))
# 定义函数,用来估算每一个Action对应的潜在价值discount_r
def discount_rewards(r):
""" take 1D float array of rewards and compute discounted reward """
discounted_r = np.zeros_like(r)
running_add = 0
for t in reversed(range(r.size)):
running_add = running_add * gamma + r[t]
discounted_r[t] = running_add
return discounted_r
# 定义一些参数:xs为环境信息observation的列表,ys为label的列表,drs为记录的每一个Action的Reward
xs, ys, drs = [], [], []
# running_reward = None
reward_sum = 0
episode_number = 1
total_episodes = 10000 # 总试验次数
init = tf.global_variables_initializer()
# Launch the graph
with tf.Session() as sess:
rendering = False
sess.run(init)
observation = env.reset() # Obtain an initial observation of the environment
# Reset the gradient placeholder. We will collect gradients in
# gradBuffer until we are ready to update our policy network.
gradBuffer = sess.run(tvars) # 创建存储参数梯度的缓冲器
# 将gradBuffer全部初始化为零
for ix, grad in enumerate(gradBuffer):
gradBuffer[ix] = grad * 0
# 进入循环
while episode_number <= total_episodes:
# Rendering the environment slows things down,
# so let's only look at it once our agent is doing a good job.
if reward_sum / batch_size > 100 or rendering == True:
env.render()
rendering = True
# Make sure the observation is in a shape the network can handle.
x = np.reshape(observation, [1, D])
# Run the policy network and get an action to take.
tfprob = sess.run(probability, feed_dict={observations: x})
action = 1 if np.random.uniform() < tfprob else 0
xs.append(x) # observation
# y = 1 if action == 0 else 0 # a "fake label"
y = 1 - action
ys.append(y)
# step the environment and get new measurements
observation, reward, done, info = env.step(action)
reward_sum += reward
drs.append(reward) # record reward (has to be done after we call step() to get reward for previous action)
if done:
episode_number += 1
# stack together all inputs, hidden states, action gradients, and rewards for this episode
epx = np.vstack(xs) # np.vstack将列表的元素纵向堆叠起来
epy = np.vstack(ys)
epr = np.vstack(drs)
xs, ys, drs = [], [], [] # reset array memory
# compute the discounted reward backwards through time
discounted_epr = discount_rewards(epr)
# size the rewards to be unit normal (helps control the gradient estimator variance)
# 标准化处理,减去均值除以标准差,得到一个零均值标准差为1的分布
discounted_epr -= np.mean(discounted_epr)
discounted_epr /= np.std(discounted_epr)
# Get the gradient for this episode, and save it in the gradBuffer
tGrad = sess.run(newGrads, feed_dict={observations: epx, input_y: epy, advantages: discounted_epr})
for ix, grad in enumerate(tGrad):
gradBuffer[ix] += grad
# If we have completed enough episodes, then update the policy network with our gradients.
if episode_number % batch_size == 0:
sess.run(updateGrads, feed_dict={W1Grad: gradBuffer[0], W2Grad: gradBuffer[1]})
for ix, grad in enumerate(gradBuffer):
gradBuffer[ix] = grad * 0
# Give a summary of how well our network is doing for each batch of episodes.
# running_reward = reward_sum if running_reward is None else running_reward * 0.99 + reward_sum * 0.01
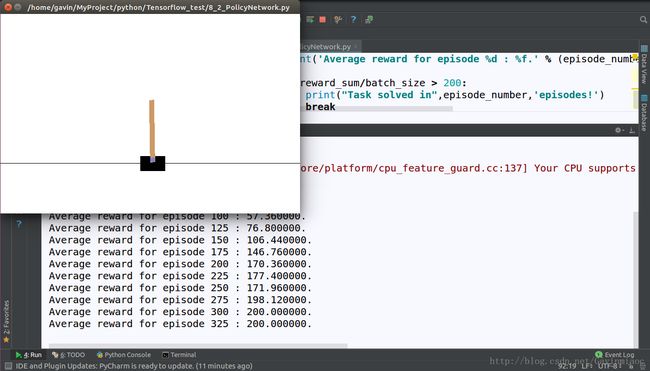
print('Average reward for episode %d : %f.' % (episode_number, reward_sum / batch_size))
if reward_sum / batch_size > 200:
print("Task solved in", episode_number, 'episodes!')
break
reward_sum = 0
observation = env.reset()