《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》论文阅读之SPPNet
paper: SPPNet
前言
上篇介绍了将CNN引入目标检测的开山之作R-CNN,介绍了CNN用于目标检测的基本思想和流程。后续出现了SPPnet,Fast-RCNN ,Faster-RCNN等一些列改进。最终实现了端对端学习,同时带来速度与精度的提升。
在详细介绍之前,先来回顾一下在RCNN中CNN阶段的大致流程:

红色框是selective search 输出的可能包含物体的候选框(ROI)。
一张图图片会有~2k个候选框,每一个都要单独输入CNN做卷积等操作很费时。SPP-net提出:能否在feature map上提取ROI特征,这样就只需要在整幅图像上做一次卷积。
虽然总体流程还是 Selective Search得到候选区域->CNN提取ROI特征->类别判断->位置精修,但是由于所有ROI的特征直接在feature map上提取,大大减少了卷积操作,提高了效率。
有两个难点要解决:
1. 原始图像的ROI如何映射到特征图(一系列卷积层的最后输出)
2. ROI的在特征图上的对应的特征区域的维度不满足全连接层的输入要求怎么办(又不可能像在原始ROI图像上那样进行截取和缩放)?
SPPNet-引入空间金字塔池化改进RCNN
Introduction
SPPNet主要针对两点提出改进:
- CNN的固定输入大小,导致不必要的精度损失
- R-CNN模型候选区域在CNN内的重复计算,造成的计算冗余
为什么CNN需要固定大小的输入?
因为一个CNN一般分为两个部分,前面的部分是卷积层,后面的部分是FC层,卷积层不要求固定大小的输入;但是FC层在设计时就固定了神经元的个数,故需要固定长度的输入。这也就是CNN需要固定输入的问题所在。
| R-CNN模型 | SPPNet模型 |
|---|---|
| 将侯选区域送到CNN里面提取特征向量时,因为CNN的输入图像需要固定大小,而候选区域的长宽都是不固定的,故需要对候选区域做填充到固定大小,当我们对侯选区域做cropping或者warping操作,可能会让图片不完整包含物体,一些我们不想见到的几何失真,这都会造成识别精度损失。 | SPPNet的解决办法是使用“空间金字塔变换层”将接收任意大小的图像输入,输出固定长度的输出向量,这样就能让SPPNet可接受任意大小的输入图片,不需要对图像做crop/wrap操作。 |
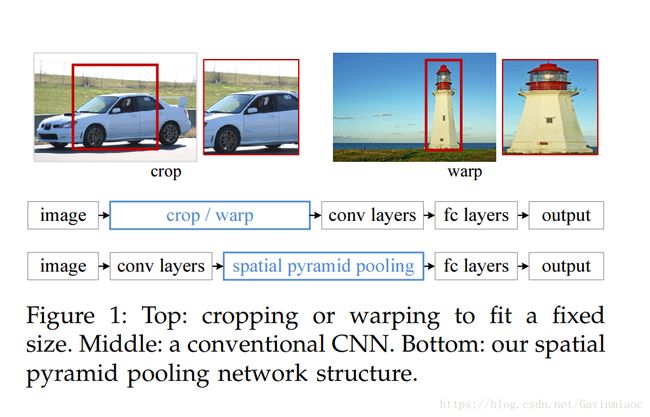
R-CNN模型候选区域在CNN内的重复计算
| R-CNN模型 | SPPNet模型 |
|---|---|
| 在R-CNN中,每个候选区域都要塞到CNN内提取特征向量,一张图片有2000个候选区域,也就是一张图片需要经过2000次CNN的前向传播,这2000重复计算过程会有大量的计算冗余,耗费大量的时间。 | SPPNet提出了一种从候选区域到全图的特征映射(feature map)之间的对应关系,通过此种映射关系可以直接获取到候选区域的特征向量,不需要重复使用CNN提取特征,从而大幅度缩短训练时间。 |
将conv5的pool层改为SPP之后就不必把每一个都ROI抠出来送给CNN做繁琐的卷积了,整张图像做卷积一次提取所有特征再交给SPP即可。
R-CNN重复使用深层卷积网络在~2k个窗口上提取特征,特征提取非常耗时。SPPNet将比较耗时的卷积计算对整幅图像只进行一次,之后使用SPP将窗口特征图池化为一个固定长度的特征表示。
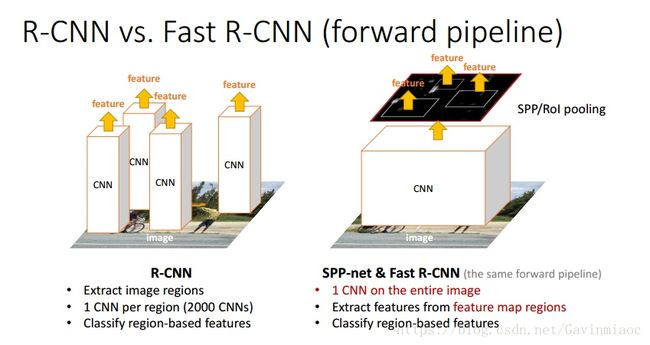
理解一下R-CNN和SPPNet的实现过程:
| R-CNN模型 | SPPNet模型 |
|---|---|
| R-CNN是让每个候选区域经过crop/wrap等操作变换成固定大小的图像 固定大小的图像塞给CNN CNN输出获得固定大小的feature map feature map传给后面的层做训练回归分类操作。 这里每个候选区域是需要单独过一下CNN,2000个候选区域过2000次CNN,耗费时间啊 |
SPPNet让一张图片完整的塞给CNN得到全图的feature map 让2000个候选区域与feature map直接映射,直接得到2000个候选区域的特征向量(这里不需要再过CNN了). 但是候选区域的特征向量大小不固定,所以把候选区域的特征向量塞给SPP层,SPP层输入接收任何大小,输出固定大小的特征向量 经过这样映射+SPP转换,简化了计算,不但速度上去了,精确度也上去了 |
看完上面的介绍,可以定位这篇论文的两个难点了。
- SPPNet怎么就能把候选区域从全图的feature map 直接整出来特征向量了?
- 空间金字塔变换层怎么可以接收任意大小的输入,输出固定的向量?
空间金字塔变换层
首先我们要连接一下Spatial Pyramid Pooling,关于Spatial Pyramid Pooling详细可参考论文
Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories[C]//CVPR 2006。
空间金字塔变换层(Spatial Pyramid Pooling,SPP)可以对图片提取特征,例如下图就是1*1,2*2,4*4大小的bin块,将一张图片以三种方式切割并提取特征,这样我们可以得到一共1+4+16=21种特征,这就是以不同的大小的bin块来提取特征的过程就是空间金字塔变换。所谓空间金字塔池化就是沿着 金字塔的低端向顶端 一层一层做池化。

SPP层的结构如下,将紧跟最后一个卷积层的池化层使用SPP代替,输出向量大小为kM,k=#filters,M=#bins,作为全连接层的输入。至此,网络不仅可对任意长宽比的图像进行处理,而且可对任意尺度的图像进行处理。尺度在深层网络学习中也很重要。
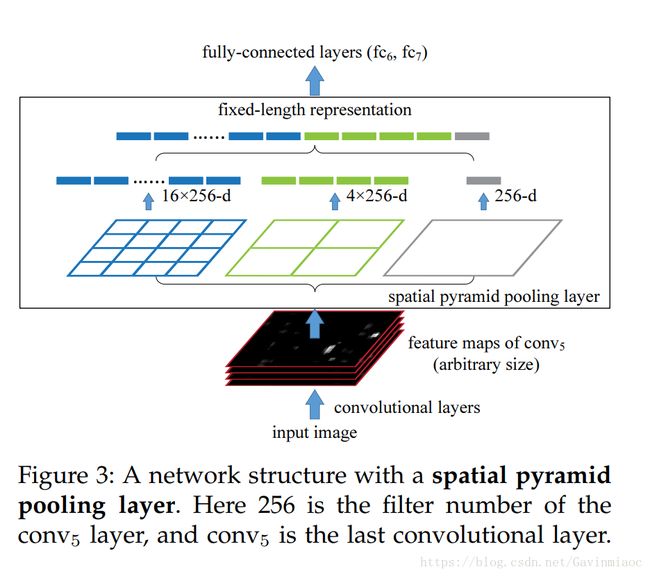
上图spp layer分成1x1(塔底),2x2(塔中),4x4(塔顶)三张子图,对每个子图的每个区域作max pooling(论文使用的),出来的特征再连接到一起,就是(16+4+1)x256的特征向量。
无论输入图像大小如何,出来的特征固定是(16+4+1)x256维度。这样就实现了不管图像尺寸如何,SPP层的输出永远是(16+4+1)x256特征向量。
通过对feature map进行相应尺度的pooling,使得能pooling出4×4, 2×2, 1×1的feature map,再将这些feature map concat成列向量与下一层全链接层相连。这样就消除了输入尺度不一致的影响。
SPP的优点:
1)任意尺寸输入,固定大小输出
2)层多
3)可对任意尺度提取的特征进行池化。
把候选区域从全图的feature map映射出特征向量
总体的映射思路为:In our implementation, we project the corner point of a window onto a pixel in the feature maps, such that this corner point (in the image domain) is closest to the center of the receptive field of that pixel.

网上查了一堆资料。这里引用知乎-晓雷机器学习笔记。machineLearning-blog.
并添加一些自己的理解。
大致思想是:
- 映射的是ROI的两个角点,左上角和右下角,这两个角点就可以唯一确定ROI的位置了。
- 将feature map的pixel映射回来图片空间
- 从映射回来的pixel中选择一个距离角点最近的pixel,作为映射。
感受野的计算
感受野我们在CNN里面讲过关于卷积参数计算。
在CNN中感受野(receptive fields)是指某一层输出结果中一个元素所对应的上一层的区域大小.
在卷积参数计算过程中,我们给出上一层/下一层/滤波器尺寸、步长和填充大小的关系:
| 类型 | 大小 |
|---|---|
| 输入尺寸 | W1×H1W1×H1 |
| 卷积核 | F×FF×F |
| 输出尺寸 | W2×H2W2×H2 |
| 步长 | stride:SS |
| 填充大小 | padding:PP |
关系式如下:
这是上一层到下一层的推导,如果现在反过来,给你下一层的大小,问你上一层的感受野多大,该怎么计算?
我们把上面公式变个形式:
直观的感受一下从后向前计算感受野的过程.

考虑一下如何计算多层之间的感受野?
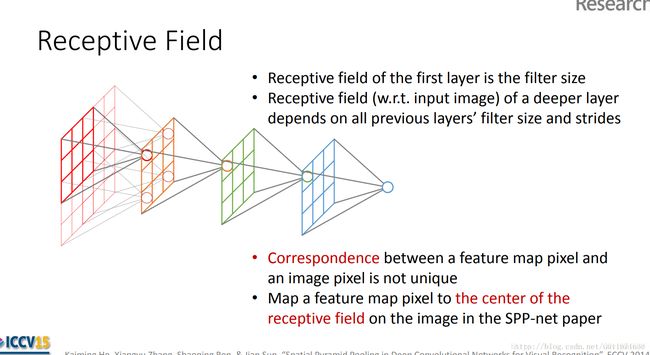
感受野计算时有下面的几个情况需要说明:
- 第一层卷积层的输出特征图像素的感受野的大小等于滤波器的大小
- 深层卷积层的感受野大小和它之前所有层的滤波器大小和步长有关系
- 计算感受野大小时,忽略了图像边缘的影响,即不考虑padding的大小
这里的每一个卷积层还有一个strides的概念,这个strides是之前所有层stride的乘积。
关于感受野大小的计算采用down to top的方式: 即先计算最深层在前一层上的感受野,然后逐渐传递到第一层,使用的公式可以表示如下:
RF = 1 #待计算的feature map上的感受野大小
for layer in (down layer To top layer):
RF = ((RF -1)* stride) + fsize
下面是一个程序计算了AlexNet、VGG16、ZF-5的输入输出尺寸的变化和感受野变化过程:
net_struct = {'alexnet': {'net':[[11,4,0],[3,2,0],[5,1,2],[3,2,0],[3,1,1],[3,1,1],[3,1,1],[3,2,0]],
'name':['conv1','pool1','conv2','pool2','conv3','conv4','conv5','pool5']},
'vgg16': {'net':[[3,1,1],[3,1,1],[2,2,0],[3,1,1],[3,1,1],[2,2,0],[3,1,1],[3,1,1],[3,1,1],
[2,2,0],[3,1,1],[3,1,1],[3,1,1],[2,2,0],[3,1,1],[3,1,1],[3,1,1],[2,2,0]],
'name':['conv1_1','conv1_2','pool1','conv2_1','conv2_2','pool2','conv3_1','conv3_2',
'conv3_3', 'pool3','conv4_1','conv4_2','conv4_3','pool4','conv5_1','conv5_2','conv5_3','pool5']},
'zf-5':{'net': [[7,2,3],[3,2,1],[5,2,2],[3,2,1],[3,1,1],[3,1,1],[3,1,1]],
'name': ['conv1','pool1','conv2','pool2','conv3','conv4','conv5']}}
imsize = 224
def outFromIn(isz, net, layernum):#从前向后算输出维度
totstride = 1
insize = isz
for layer in range(layernum):
fsize, stride, pad = net[layer]
outsize = (insize - fsize + 2*pad) / stride + 1
insize = outsize
totstride = totstride * stride
return outsize, totstride
def inFromOut(net, layernum):#从后向前算感受野 返回该层元素在原始图片中的感受野
RF = 1
for layer in reversed(range(layernum)):
fsize, stride, pad = net[layer]
RF = ((RF -1)* stride) + fsize
return RF
if __name__ == '__main__':
print("layer output sizes given image = %dx%d" % (imsize, imsize))
for net in net_struct.keys():
print( '************net structrue name is %s**************'% net)
for i in range(len(net_struct[net]['net'])):
p = outFromIn(imsize,net_struct[net]['net'], i+1)
rf = inFromOut(net_struct[net]['net'], i+1)
print( "Layer Name = %s, Output size = %3d, Stride = % 3d, RF size = %3d" % (net_struct[net]['name'][i], p[0], p[1], rf))大家随意感受一下就好。

基于感受野的特征映射
通常,我们需要知道网络里面任意两个feature map之间的坐标映射关系(一般是中心点之间的映射),如下图,我们想得到map3上的点p3映射回map2所在的位置p2(橙色框的中心点)
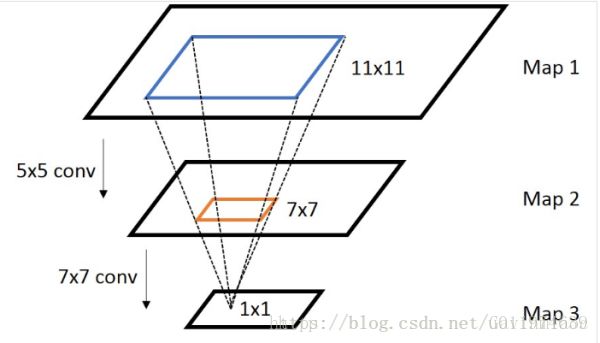
计算公式:
- 对于 Conv/Pool layer: pi=si⋅pi+1+((ki−1)/2−padding)pi=si⋅pi+1+((ki−1)/2−padding)
- 对于Neuronlayer(ReLU/Sigmoid/..) : pI=pi+1pI=pi+1
上面是计算任意一个layer输入输出的坐标映射关系,如果是计算任意feature map之间的关系,只需要用简单的组合就可以得到,下图是一个简单的例子:

下图是Kaiming He 在ICCV15上的汇报用的PPT,讲解如何求解Receptive Field:

A simple solution:
何凯明在SPP-net中采用的方法。巧妙的化简一下公式pi=si⋅pi+1+((ki−1)/2−padding)pi=si⋅pi+1+((ki−1)/2−padding)令每一层的paddingpadding都为padding=⌊ki/2⌋⇒pi=si⋅pi+1+((ki−1)/2−⌊ki/2⌋)padding=⌊ki/2⌋⇒pi=si⋅pi+1+((ki−1)/2−⌊ki/2⌋)- 当 kiki 为奇数
(ki−1)/2−⌊ki/2⌋)=0⇒pi=si⋅pi+1(ki−1)/2−⌊ki/2⌋)=0⇒pi=si⋅pi+1
- 当kiki 为偶数
((ki−1)/2−⌊ki/2⌋)=−0.5⇒pi=si⋅pi+1−0.5((ki−1)/2−⌊ki/2⌋)=−0.5⇒pi=si⋅pi+1−0.5
- 而 pipi 是坐标值,不取小数,基本上认为pi=si⋅pi+1pi=si⋅pi+1 。感受野中心点的坐标pipi只跟前一层 pi+1pi+1 有关。
- 当 kiki 为奇数
A general solution:
其实就是把公式 pi=si⋅pi+1+((ki−1)/2−padding)pi=si⋅pi+1+((ki−1)/2−padding)级联消去整合一下-

候选区域到feature map的映射做法详解
SPP-net 是把原始ROI的左上角和右下角 映射到 feature map上的两个对应点。 有了feature map上的两队角点就确定了 对应的 feature map 区域(下图中橙色)。
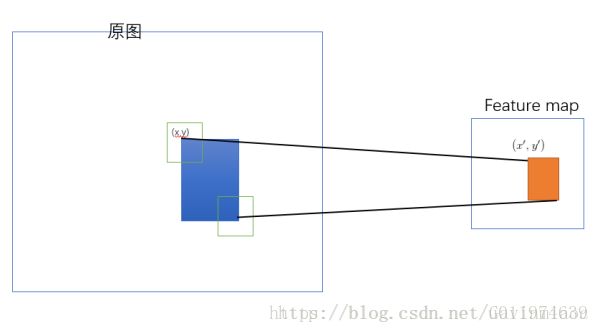
如何映射?
左上角的点(x,y)(x,y)映射到 feature map上的(x′,y′)(x′,y′) :使得(x′,y′)(x′,y′) 在原始图上感受野(上图绿色框)的中心点 与(x,y)(x,y)尽可能接近。
对应点之间的映射公式是啥?
- 就是前面每层都填充padding/2padding/2 得到的简化公式 : pi=si⋅pi+1pi=si⋅pi+1
- 需要把上面公式进行级联得到 p0=S⋅pi+1p0=S⋅pi+1其中(S=∏i0si)(S=∏0isi)
- 对于feature map 上的(x′,y′)(x′,y′) 它在原始图的对应点为(x,y)=(Sx′,Sy′)(x,y)=(Sx′,Sy′)
- 论文中的最后做法:把原始图片中的ROI映射为 feature map中的映射区域(上图橙色区域)
- 左上角取:x′=⌊x/S⌋+1 x′=⌊x/S⌋+1 ; y′=⌊y/S⌋+1y′=⌊y/S⌋+1;
- 右下角取: x′=⌈x/S⌉−1 x′=⌈x/S⌉−1 ;y′=⌈y/S⌉−1y′=⌈y/S⌉−1。
到这里就算是把SPPNet的核心思想讲完了,SPPNet网络后面和R-CNN类似,训练SVM分类器和位置回归等。 论文里还有很多实验细节和结果,有兴趣的可以再分析分析~
使用SPP进行检测,先用提候选proposals方法(selective search)选出候选框,不过不像RCNN把每个候选区域给深度网络提特征,而是整张图提一次特征,再把候选框映射到conv5上,因为候选框的大小尺度不同,映射到conv5后仍不同,所以需要再通过SPP层提取到相同维度的特征,再进行分类和回归,后面的思路和方法与RCNN一致。
实际上这样子做的话就比原先的快很多了,因为之前RCNN也提出了这个原因就是深度网络所需要的感受野是非常大的,这样子的话需要每次将感兴趣区域放大到网络的尺度才能卷积到conv5层。这样计算量就会很大,而SPP只需要计算一次特征,剩下的只需要在conv5层上操作就可以了。
参考文献:
1.https://zhuanlan.zhihu.com/p/24774302
2.https://blog.csdn.net/u011534057/article/details/51219959
3.https://blog.csdn.net/u011974639/article/details/78053203#r-cnn