Dataframe的使用方法
现在我们已经学会如何将数据导入 DataFrame 中,我们可以利用它来解决工作上遇到的问题。Pandas提供了大量的函数,本文无法全部覆盖,有兴趣的读者可以详细阅读官方说明文档或者利用 google 搜索更多相关的信息——网上有许多 StackOverflow 的问题和一些介绍该软件库的技术博客。
接下来我们将利用MovieLens数据集来介绍 DataFrame 的使用方法。
检查数据
Pandas 中有许多用于获取 DataFrame 基本信息的函数,其中最常用的是 info 方法。

上述输出结果中告诉我们 DataFrame 的一些信息:
1.该数据集是一个 DataFrame 实例。
2.数据的行索引是从 0 到 N-1 的一组数字,其中 N 为 DataFrame 的行数。
3.数据集中总共有 1682 行观测值。
4.数据集中有五列变量,其中变量 video_release_date 中没有数据,变量 release_date 和 imdb_url 中存在个别缺失值。
5.最后一行给出了变量数据类型汇总情况,你可以利用 dtypes 方法获取每个变量的数据类型。
6.保存该数据集所耗费的内存,你可以利用 .memory_usage 获取更多信息。
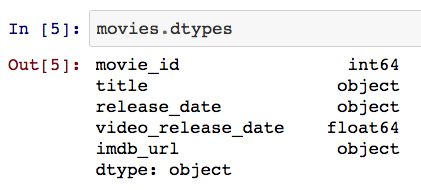
DataFrames 中还有一个 describe 方法,它用于获取数据集的常用统计量信息。需要注意的是,该方法仅会返回数值型变量的信息,所以我们会得到 user_id 和 age 两个变量的统计量信息。
你可能已经注意到我的文章中经常使用head方法,默认情况下,head方法会返回数据集的前五条记录,tail方法会返回最后五条记录。

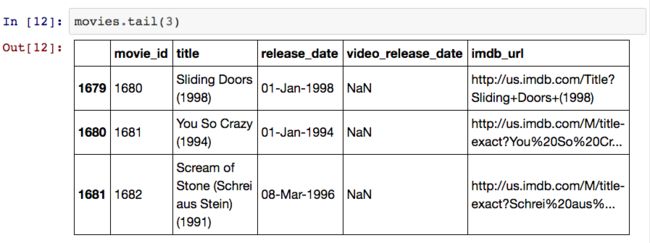
此外,我们还可以利用 Python 的常用切片语法来提取数据。
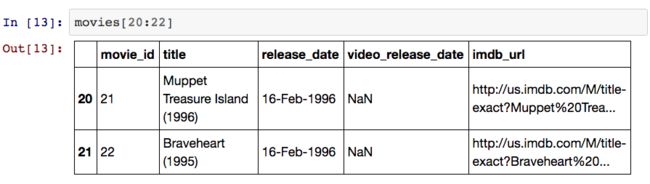
Selecting
我们可以将 DataFrames 看出由一组共享索引的 Series 组成,因此从DataFrame 中选取某个变量将返回一个 Series 对象。

将多个变量的名字传递给 DataFrame,即可获得一个包含多列变量的 DataFrame。

从 DataFrame 中提取行数据有多种方法,常用的方法有行索引法和布尔索引法。

由于通常情况下行索引值都是一组无实际意义的数值,我们可以利用set_index方法将user_id设定为索引变量。默认情况下,set_index方法将返回一个新的 DataFrame。


你还可以设定参数inplace的数值来修改现有的 DataFrame 数据集。
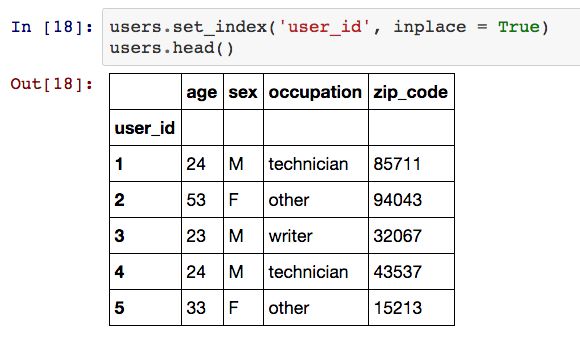
从上表中可以看出,user_id替代了原先的索引变量,我们可以利用iloc方法根据位置来选择相应的行数据。
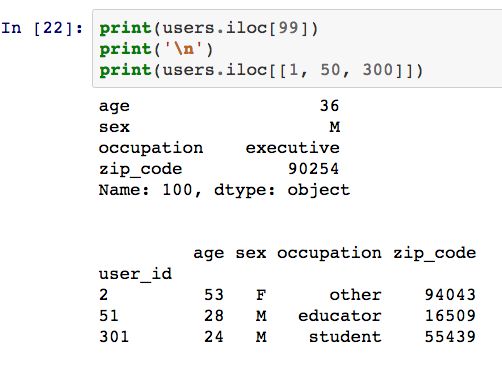
我们也可以利用loc方法根据label来选取行数据。

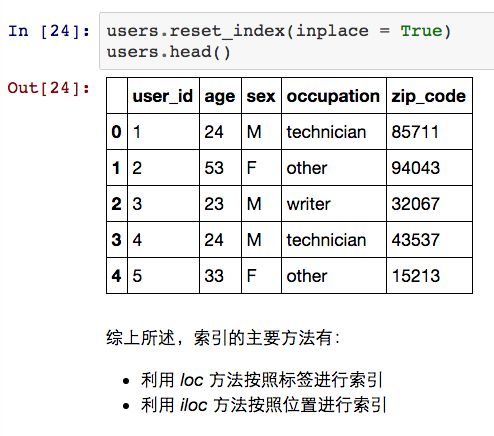
此外,我们还可以利用reset_index方法来恢复默认索引变量。
Joining
在数据分析过程中,我们经常需要根据一定的规则合并多个数据集。
比如上文提到的 MovieLens 数据集就是一个很好的例子——每个电影评价都涉及到用户和电影信息,我们可以通过user_id和movie_id将其连接起来。类似于 SQL 中的 JOIN 语法,pandas.merge可以根据某几个键值合并两个 DataFrames。该函数提供了一系列的参数(on,left_on,right_on,left_index,right_index),这些参数用于指定合并的规则。
默认情况下,pandas.merge采用内连接方式合并数据集,我们可以修改参数how来控制合并的方式。

以下是几个案例说明:


inner join(默认设定)

从上表中可以看出,两个表中键值不匹配的数据被剔除掉了。SQL等价语句为:
SELECT left_frame.key, left_frame.left_value, right_frame.value FROM left_frame INNER JOIN right_frame ON left_frame.key = right_frame.key;
如果两个 DataFrame 的键值命名不一致,我们可以left_on和right_on参数来指定合并的键值——pd.merge(left_frame, right_frame, left_on = ‘left_key’, right_on = ‘right_key’)。此外,如果键值是 DataFrame 的索引值,我们还可以利用left_index和right_index参数来指定合并的键值——pd.merge(left_frame, right_frame, left_on = ‘key’, right_index = True)。
left_outer join

从上表可得,左表中的数据全被保留下来,右表中键值不匹配的样本由 NULL 所替代。SQL 等价语句为:
SELECT left_frame.key, left_frame.left_value, right_frame.right_value FROM left_frame LEFT JOIN right_frame ON left_frame.key = right_frame.key;
right outer join

此时,我们保留右表的所有数据,左表中键值不匹配的样本由 NULL 替代。SQL 等价语句为:
SELECT right_frame.key, left_frame.left_value, right_frame.right_value FROM left_frame RIGHT JOIN right_frame ON left_frame.key = right_frame.key;
full outer join

此时,我们保留两个表中所有的观测值,其中键值不匹配的样本均由 NULL 所替代。SQL 等价语句为(部分数据库不支持 FULL JOIN 语句,比如 MYSQL):
SELECT IFNULL(left_frame.key, right_frame.key) key, left_frame.left_value, right_frame.right_value FROM left_frame FULL OUTER JOIN right_frame ON left_frame.key = right_frame.key;
Combining
Pandas 还提供了另一种沿着轴向合并 DataFrames 的方法——pandas.concat,该函数等价于 SQL 中的 UNION 语法。
pandas.concat传入 Series 或者 DataFrame 的列表对象,并返回合并后的对象。需要注意的是由于该函数处理的是列表对象,所以可以同时合并多个对象。

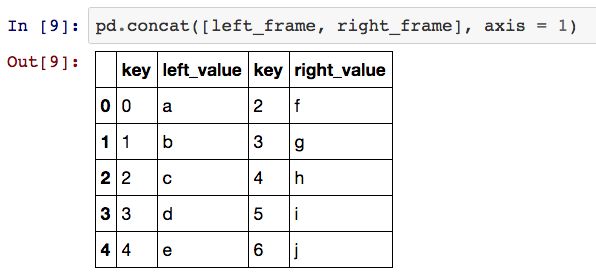
默认情况下,该函数会沿垂直方向合并不同的对象,其中不匹配的样本由 NULL 所替代。
此外,我们还可以利用axis参数来控制合并的方向。
pandas.concat的用途非常广,但是我仅仅利用它来合并 Series/DataFrame 对象。
Grouping
我花了好久才掌握了 pandas 中的分组功能,但该功能确实非常实用。
pandas 中的groupby方法主要用于执行数据分析过程中的split-apply-combine策略。如果你不熟悉这个方法的话,我建议你阅读上述说明文档。它很好地阐述了如何思考一个数据分析问题,我觉得对于数据分析师来说这是一个非常重要的技能。
处理一个数据分析问题时,你通常会将数据集切分成一系列小块数据,然后对每部分的数据执行相应的处理,最后再汇总各部分的运算结果(这就是split-apply-combine策略的主体思想)。pandas 中的groupby主要用于解决该问题,R 语言中的 plyr 和 dplyr 包中也有相应的分组函数。
如果你曾经接触过 SQL 的 GROUP BY 功能或者 Excel 中的数据透视表功能,那么你的脑海中已经有了这种观念,只是你没有意识到罢了。
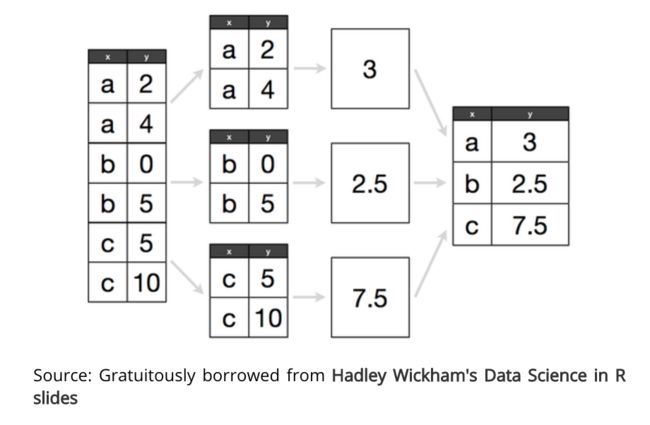
假设我们拥有一个 DataFrame,我们想要计算每个组的平均值,如下图所示:
芝加哥政府将整个城市的员工工资数据挂在其数据开放平台上,我们接下来利用这些数据来举例说明groupby方法。
由于该数据集的工资变量中包含美元符号,所以 Python 会识别成字符型变量。我们可以利用concerters参数来改变读取规则。


pandas的groupby方法将返回一个 DataFrameGroupBy 对象,该对象拥有许多常用的汇总方法。

count方法将返回每一列变量中所有非缺失数据的个数,size方法将返回每组变量的个数。

此外,我们还可以利用sum和mean来计算变量的总数和平均数。

我们还可以对单独的分组序列对象进行计算:比如我们想要了解数据集中最常见的五个部门名称:
SELECT department, COUNT(DISTINCT title) FROM chicago GROUP BY department ORDER BY 2 DESC LIMIT 5;
pandas 中的语法为:

split-apply-combine
groupby方法最强大的地方在于它的split-apply-combine能力。
如果我们想要了解每个部门中最高工资的员工,我们要怎么做呢?首先,我们可以利用 SQL 语句来查询:
SELECT * FROM chicago c INNER JOIN ( SELECT department, max(salary) max_salary FROM chicago GROUP BY department ) m ON c.department = m.department AND c.salary = m.max_salary;
上述代码会返回每个部门中最高收入的所有员工信息,或者你可以更改表格中的数据,增加一列变量然后执行更新语句。
备注:该方法适用于 PostgreSQL, T-SQL 和 Oracle 数据库,但考虑到使用的便捷性,本文中选取 MySQL 作为默认数据库形式。不幸的是,MySQL 中没有相似的函数。
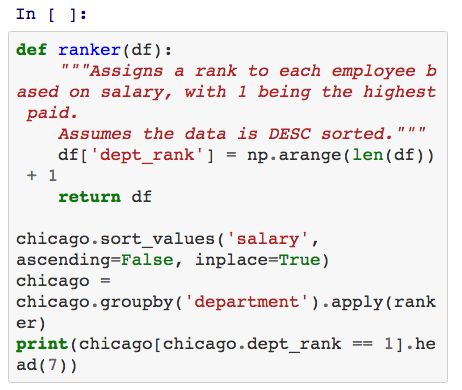
利用groupby方法我们可以定义一个函数用于将所有的观测值从1标记到N。我们还可以利用apply函数来实现这个功能: