Kaggle——Titanic: Machine Learning from Disaster (XGBoost +神经网络)
今天没什么动力写代码,正确率也一直停在80%上不去,整理下之前写的代码吧。
代码整体的逻辑是使用XGBoost 和神经网络训练两个结果,然后和之前表现最好的结果放在一起投票,然后得出最终的结果。
代码结构:

对于特征选择,我首先去掉了
Name', 'Ticket', 'PassengerId'然后对sex、Pclass、SibSp、Embarked 进行了特征因子化。
按照Cabin是否为空进行了分类。
数据中Fare和Age都有缺失,对于Fare我直接填充了均值。
对于Age来说,我们发现Age对最终结果影响很大(见下图)
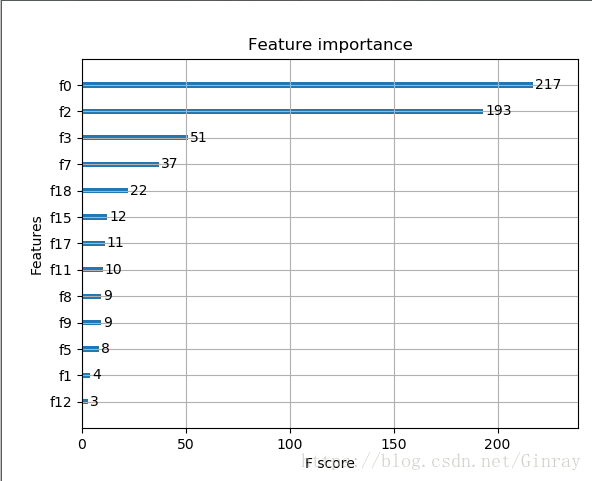
所以我尝试训使用RandomForestRegressor,利用Fare、Parch、SibSp、Pclass对缺失的Age进行拟合。
然而发现效果一般,就直接丢弃了缺失Age的数据进行训练。
神经网络刚开始用了CNN,也是一种思维惯性吧,之前都是对图像进行操作的。后来改成了全连接层,因为看到一个博客说CNN是用来提取特征的,现在是已经有了提取好的特征,再用CNN应该会造成损失,我觉得有一定的道理。
训练中的正确率变化:
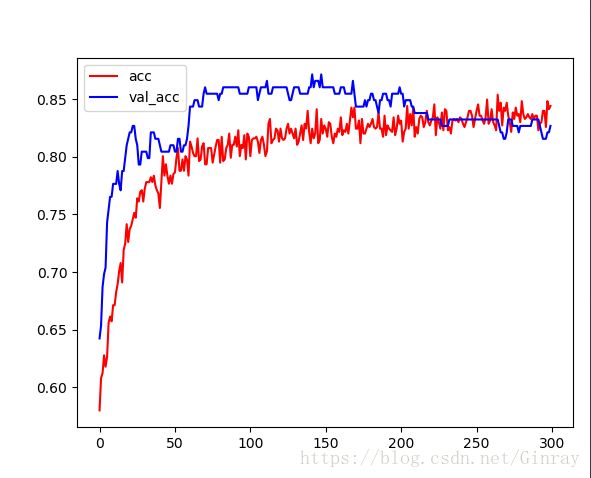
在epochs为170左右发生了过拟合。
最后的结果大概是80%左右。

代码:
# -*-coding:utf-8 -*-
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import sklearn.preprocessing as preprocessing
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBClassifier
from xgboost import plot_importance
from keras.layers import Dropout, Dense, Conv2D, Flatten, MaxPool2D
from keras.models import Sequential, load_model
from keras.callbacks import EarlyStopping, Callback
def show_training_data(input_data):
plt.subplot2grid((2, 3), (0, 0))
input_data['Age'].hist()
plt.subplot2grid((2, 3), (0, 1))
plt.scatter(input_data['Age'], input_data['Survived'])
plt.subplot2grid((2, 3), (1, 0), colspan=2)
# 链接多个条件可以使用 &
input_data['Age'][input_data['Pclass'] == 1].plot(kind='kde')
input_data.Age[input_data['Pclass'] == 2].plot(kind='kde')
input_data.Age[input_data['Pclass'] == 3].plot(kind='kde')
plt.xlabel(u'年龄')
plt.legend((u'头等舱', u'二等舱', u'三等舱'))
survived0 = input_data.Survived[input_data['Sex'] == 'male'].value_counts()
survived1 = input_data.Survived[input_data['Sex'] == 'female'].value_counts()
df = pd.DataFrame({'male': survived0, 'female': survived1})
df.plot(kind='bar')
plt.show()
def format_training_data(input_data):
# 丢弃掉暂时不需要的
input_data.drop(['Name', 'Ticket', 'PassengerId'], axis=1, inplace=True)
# 用于特征因子化
sex_data = pd.get_dummies(input_data['Sex'], prefix='Sex')
pclass_data = pd.get_dummies(input_data['Pclass'], prefix='Pclass')
sibsp_data = pd.get_dummies(input_data['SibSp'], prefix='SibSp')
embarked_data = pd.get_dummies(input_data['Embarked'], prefix='Embarked')
# 处理cabin ,注意这两句别写反了,不然原来的的null就有值了
input_data.loc[input_data.Cabin.notnull(), 'Cabin'] = 'yes'
input_data.loc[input_data.Cabin.isnull(), 'Cabin'] = 'no'
cabin_data = pd.get_dummies(input_data['Cabin'], prefix='Cabin')
input_data = pd.concat([input_data, sex_data, pclass_data, sibsp_data, embarked_data, cabin_data], axis=1)
input_data.drop(['Sex', 'Pclass', 'SibSp', 'Embarked', 'Cabin'], axis=1, inplace=True)
return input_data
def scaler_data(input_data):
# 处理age中的NaN值
# 暂时先填充为平均值,之后可以再优化 (Done)
# input_data.loc[input_data['Age'].isnull(), 'Age'] = input_data['Age'].mean()
input_data.loc[input_data['Fare'].isnull(), 'Fare'] = input_data['Fare'].mean()
scaler = preprocessing.StandardScaler()
age_scaler_param = scaler.fit(input_data['Age'].values.reshape(-1, 1))
input_data['Age'] = scaler.fit_transform(input_data['Age'].values.reshape(-1, 1), age_scaler_param)
fare_scaler_param = scaler.fit(input_data['Fare'].values.reshape(-1, 1))
input_data['Fare'] = scaler.fit_transform(input_data['Fare'].values.reshape(-1, 1), fare_scaler_param)
return input_data
def fix_missing_age(input_data):
# age在最后的结果中影响还是很大的,尝试下使用逻辑回归拟合一个age
# 来代替之前直接使用平均数来代替
age_df = input_data[['Age', 'Fare', 'Parch', 'SibSp', 'Pclass']]
known_age = age_df[age_df['Age'].notnull()].values
unknown_age = age_df[age_df.Age.isnull()].values
y = known_age[:, 0]
X = known_age[:, 1:]
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
# print(y)
rfr.fit(X, y)
fix_age = rfr.predict(unknown_age[:, 1:])
input_data.loc[(input_data.Age.isnull()), 'Age'] = fix_age
return input_data, rfr
def start_train(input_data):
# 首先划分测试集和训练集,对数据的格式进行调整
_x = input_data.values[:, 1:]
_y = input_data.values[:, 0]
x_train, x_test, y_train, y_test = train_test_split(_x, _y, test_size=0.2)
model = XGBClassifier(learning_rate=0.1)
model.fit(x_train, y_train, early_stopping_rounds=300, eval_metric='logloss', eval_set=[(x_test, y_test)],
verbose=True)
y_pred = model.predict(x_test)
prediction = [round(_) for _ in y_pred]
acc = accuracy_score(y_test, prediction)
print('Accuracy = {0}'.format(acc))
# 展示特征的重要性
plot_importance(model)
plt.show()
return model, prediction
def pred_result(rfr):
pred_input_data = pd.read_csv('data/test.csv')
# 预测的丢失的Age
age_df = pred_input_data[['Age', 'Fare', 'Parch', 'SibSp', 'Pclass']]
unknown_age = age_df[age_df.Age.isnull()].values
fix_pred_age = rfr.predict(unknown_age[:, 1:])
pred_input_data.loc[pred_input_data.Age.isnull(), 'Age'] = fix_pred_age
pred_input_data = format_training_data(pred_input_data)
pred_input_data = scaler_data(pred_input_data)
return pred_input_data
def save_result(result, filename):
result_np = np.array(result).astype(int)
save = pd.DataFrame({'PassengerId': range(892, result_np.shape[0] + 892), 'Survived': result_np})
save.to_csv(filename, index=False, sep=',')
print('Finish')
class LossHistory(Callback):
def on_train_begin(self, logs={}):
self.loss = []
self.val_loss = []
def on_epoch_end(self, batch, logs={}):
self.loss.append(logs.get('acc'))
self.val_loss.append(logs.get('val_acc'))
def train_with_cnn(train_data):
model = Sequential()
model.add(Dense(32, input_dim=20))
model.add(Dropout(0.25))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(128, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(16, activation='relu'))
model.add(Dense(2, activation='softmax'))
# model.add(Conv2D(input_shape=(4, 5, 1), kernel_size=(3, 3), filters=128, padding='same', activation='relu'))
# model.add(Conv2D(kernel_size=(3, 3), filters=128, padding='same', activation='relu'))
# model.add(Conv2D(kernel_size=(3, 3), filters=256, padding='same', activation='relu'))
# model.add(Conv2D(kernel_size=(3, 3), filters=512, padding='same', activation='relu'))
# model.add(Dropout(0.25))
# model.add(Flatten())
# model.add(Dense(256, activation='relu'))
# model.add(Dropout(0.25))
# model.add(Dense(2, activation='softmax'))
model.compile(loss="categorical_crossentropy", optimizer='adam', metrics=['accuracy'])
early_stopping = EarlyStopping(monitor='val_acc', patience=10)
history = LossHistory()
x_train_data = train_data.values[:, 1:]
y_train_data = train_data.values[:, 0]
# x_train_data = np.array(x_train_data).reshape(x_train_data.shape[0], 4, 5, 1)
# y_train_data = np.array(y_train_data).reshape(y_train_data.shape[0], 1)
x_train_data = np.array(x_train_data).reshape(x_train_data.shape[0], 20)
y_train_data = np.array(y_train_data).reshape(y_train_data.shape[0], 1)
y_fix = np.zeros((y_train_data.shape[0], 2))
for i in range(y_train_data.shape[0]):
y_fix[i][int(y_train_data[i][0])] = 1
model.fit(x_train_data, y_fix, epochs=300, batch_size=712, validation_split=0.2, callbacks=[history])
model.save('model/my_model.h5')
return history
def pred_with_cnn(pred_input_data):
pred_model = load_model('model/my_model.h5')
pred_input_data = pred_input_data.values
# pred_input_data = np.array(pred_input_data).reshape(pred_input_data.shape[0], 4, 5, 1)
pred_input_data = np.array(pred_input_data).reshape(pred_input_data.shape[0], 20)
result = pred_model.predict(pred_input_data, batch_size=712)
result = np.array(result)
fix_result = np.zeros(result.shape[0])
for i in range(result.shape[0]):
fix_result[i] = round(result[i][1])
# print(fix_result)
return fix_result
def model_ensemble(filename1, filename2, filename3):
file1 = pd.read_csv(filename1).values[:, 1:]
file2 = pd.read_csv(filename2).values[:, 1:]
file3 = pd.read_csv(filename3).values[:, 1:]
final_score = []
index = 0
for i, j, k in zip(file1, file2, file3):
if i == j:
final_score.append(i[0])
elif i == k:
final_score.append(i[0])
else:
final_score.append(j[0])
index += 1
save_result(final_score, 'final_result.csv')
input_data = pd.read_csv('data/train.csv')
# show_training_data(input_data)
_, rfr = fix_missing_age(input_data)
input_data = input_data.loc[input_data.Age.notnull()]
input_data = format_training_data(input_data)
input_data = scaler_data(input_data)
save_history = train_with_cnn(input_data)
model, prediction = start_train(input_data) # XGBoost
# 进行预测
pred_input_data = pred_result(rfr)
result = pred_with_cnn(pred_input_data)
result = result.astype(int)
XGBoost_result = model.predict(pred_input_data.values)
XGBoost_result = [round(_) for _ in XGBoost_result]
# print(XGBoost_result)
save_result(XGBoost_result, 'xgb_result.csv')
save_result(result, 'fc_result.csv')
plt.plot(save_history.loss, label='1', color='r')
plt.plot(save_history.val_loss, label='2', color='b')
plt.legend(['acc', 'val_acc'])
plt.show()
model_ensemble('result.csv', 'fc_result.csv', 'xgb_result.csv')