7.测试hadoop安装成功与否,并跑mapreduce实例
hadoop2.6.5集群安装及mapreduce测试运行
http://blog.csdn.net/fanfanrenrenmi/article/details/54232184
【准备工作】在每一次测试之前,必须把前一次测试完的文件删除掉,具体命令见下:
################################
#在master机器上:
su hadoop #切换用户
################################
rm -r /home/hadoop/hadoop/* #删除
mkdir /home/hadoop/hadoop/datanode /home/hadoop/hadoop/namenode /home/hadoop/hadoop/tmp #创建
chmod -R 777 /home/hadoop/hadoop/datanode /home/hadoop/hadoop/namenode /home/hadoop/hadoop/tmp #修改权限
################################
ssh slave1
rm -r /home/hadoop/hadoop/* #删除
mkdir /home/hadoop/hadoop/datanode /home/hadoop/hadoop/namenode /home/hadoop/hadoop/tmp #创建
chmod -R 777 /home/hadoop/hadoop/datanode /home/hadoop/hadoop/namenode /home/hadoop/hadoop/tmp #修改权限
#################################
ssh slave2
rm -r /home/hadoop/hadoop/* #删除
mkdir /home/hadoop/hadoop/datanode /home/hadoop/hadoop/namenode /home/hadoop/hadoop/tmp #创建
chmod -R 777 /home/hadoop/hadoop/datanode /home/hadoop/hadoop/namenode /home/hadoop/hadoop/tmp #修改权限
ssh master
################################
=============================================
开 始 测 试
=============================================
(一)
1)格式化 hdfs (在 master 机器上)
hdfs namenode -format
显示下面内容:
17/08/12 22:13:49 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/192.168.222.134
************************************************************/
2)启动 hdfs (在 master 机器上)
start-dfs.sh
显示下面内容:
hadoop@master:~$ start-dfs.sh
Starting namenodes on [master]
master: starting namenode, logging to /data/hadoop-2.6.5/logs/hadoop-hadoop-namenode-master.out
slave1: starting datanode, logging to /data/hadoop-2.6.5/logs/hadoop-hadoop-datanode-slave1.out
slave2: starting datanode, logging to /data/hadoop-2.6.5/logs/hadoop-hadoop-datanode-slave2.out
Starting secondary namenodes [master]
master: starting secondarynamenode, logging to /data/hadoop-2.6.5/logs/hadoop-hadoop-secondarynamenode-master.out
3)在master机器上jps
hadoop@master:~$ jps # 3 个
10260 NameNode
10581 Jps
10469 SecondaryNameNode4)在 slave1 和slave2 上使用jps
hadoop@slave1:~/hadoop$ jps # 2 个
6688 Jps
6603 DataNode
==================================
hadoop@slave2:~$ jps # 2 个
6600 DataNode
6682 Jps
解释:jps命令是查看当前启动的节点
上面说明了在 master 节点上成功启动了NameNode 和 SecondaryNameNode,
在 slave 节点上成功启动了DataNode,也就说明 HDFS 启动成功。===========
(二)
1)在 master上
start-yarn.sh #启动 yarn
显示下面内容:
hadoop@master:~$ start-yarn.sh #启动 yarn
starting yarn daemons
starting resourcemanager, logging to /data/hadoop-2.6.5/logs/yarn-hadoop-resourcemanager-master.out
slave2: nodemanager running as process 6856. Stop it first.
slave1: starting nodemanager, logging to /data/hadoop-2.6.5/logs/yarn-hadoop-nodemanager-slave1.out2)在master上jps
hadoop@master:~$ jps # 4 个
10260 NameNode
10469 SecondaryNameNode
10649 ResourceManager
10921 Jps3)在 slave1 和slave2 上jps
hadoop@slave1:~/hadoop$ jps # 3 个
6771 NodeManager
6887 Jps
6603 DataNode
=========================================
hadoop@slave2:~$ jps # 3 个
7057 Jps
6600 DataNode
6856 NodeManager 上面说明成功启动了 ResourceManager 和 NodeManager,也就
是说 yarn 启动成功。(三)访问 WebUI
在 master、slave1 和 slave2 任意一台机器上打开 firefox,然后
输入 http://master:8088/,如果看到如下的图片,就说明我们的 hadoop 集群搭建成功了。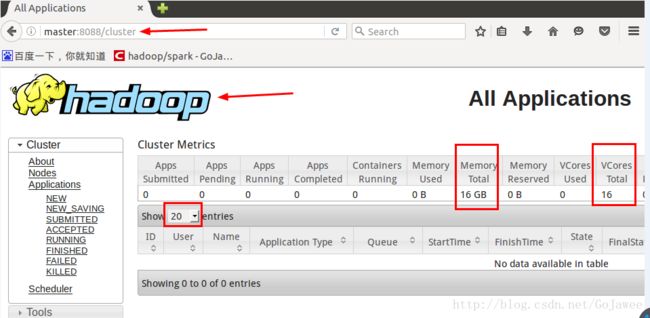
(四)测试完成后,用下面命令进行关闭:
stop-all.sh
显示见下:
hadoop@master:~$ stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [master]
master: stopping namenode
slave1: stopping datanode
slave2: stopping datanode
Stopping secondary namenodes [master]
master: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
slave1: stopping nodemanager
slave2: stopping nodemanager
no proxyserver to stop
再用jps分别查看master、slaver1、slave2机器的状态,发现已经关闭。
(五)清理产生的文件
【记得执行下面代码清空上次生成的文件,以免对下次测试造成影响】
################################
#在master机器上:
su hadoop #切换用户
################################
rm -r /home/hadoop/hadoop/* #删除
mkdir /home/hadoop/hadoop/datanode /home/hadoop/hadoop/namenode /home/hadoop/hadoop/tmp #创建
chmod -R 777 /home/hadoop/hadoop/datanode /home/hadoop/hadoop/namenode /home/hadoop/hadoop/tmp #修改权限
################################
ssh slave1
rm -r /home/hadoop/hadoop/* #删除
mkdir /home/hadoop/hadoop/datanode /home/hadoop/hadoop/namenode /home/hadoop/hadoop/tmp #创建
chmod -R 777 /home/hadoop/hadoop/datanode /home/hadoop/hadoop/namenode /home/hadoop/hadoop/tmp #修改权限
#################################
ssh slave2
rm -r /home/hadoop/hadoop/* #删除
mkdir /home/hadoop/hadoop/datanode /home/hadoop/hadoop/namenode /home/hadoop/hadoop/tmp #创建
chmod -R 777 /home/hadoop/hadoop/datanode /home/hadoop/hadoop/namenode /home/hadoop/hadoop/tmp #修改权限
ssh master
################################=============================================
应用mapreduce
=============================================
hadoop fs 查看hdfs操作系统命令集合1.启动hadoop集群
start-all.sh
2.创建hdfs目录
hadoop fs -mkdir /input
3.上传文件
hadoop fs -put /data/hadoop-2.6.5/README.txt /input/
4.修改文件名称
hadoop fs -mv /input/README.txt /input/readme.txt
5.查看文件 hadoop fs -ls /input
运行输出情况见下:
hadoop@master:~$ hadoop fs -ls /input
Found 1 items
-rw-r--r-- 3 hadoop supergroup 1366 2017-08-13 19:58 /input/readme.txt
【注解】输出文件夹为output,无需新建,若已存在需删除
6.运行hadoop自带例子
hadoop jar /data/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount /input /output
运行输出情况见下:
hadoop@master:~$ hadoop jar /data/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount /input /output
17/08/13 20:11:18 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.222.139:8032
17/08/13 20:11:21 INFO input.FileInputFormat: Total input paths to process : 1
17/08/13 20:11:21 INFO mapreduce.JobSubmitter: number of splits:1
17/08/13 20:11:22 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1502625091562_0001
17/08/13 20:11:23 INFO impl.YarnClientImpl: Submitted application application_1502625091562_0001
17/08/13 20:11:23 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1502625091562_0001/
17/08/13 20:11:23 INFO mapreduce.Job: Running job: job_1502625091562_0001
17/08/13 20:11:45 INFO mapreduce.Job: Job job_1502625091562_0001 running in uber mode : false
17/08/13 20:11:45 INFO mapreduce.Job: map 0% reduce 0%
17/08/13 20:11:59 INFO mapreduce.Job: map 100% reduce 0%
17/08/13 20:12:29 INFO mapreduce.Job: map 100% reduce 100%
17/08/13 20:12:30 INFO mapreduce.Job: Job job_1502625091562_0001 completed successfully
17/08/13 20:12:30 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=1836
FILE: Number of bytes written=218883
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1466
HDFS: Number of bytes written=1306
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=11022
Total time spent by all reduces in occupied slots (ms)=26723
Total time spent by all map tasks (ms)=11022
Total time spent by all reduce tasks (ms)=26723
Total vcore-milliseconds taken by all map tasks=11022
Total vcore-milliseconds taken by all reduce tasks=26723
Total megabyte-milliseconds taken by all map tasks=11286528
Total megabyte-milliseconds taken by all reduce tasks=27364352
Map-Reduce Framework
Map input records=31
Map output records=179
Map output bytes=2055
Map output materialized bytes=1836
Input split bytes=100
Combine input records=179
Combine output records=131
Reduce input groups=131
Reduce shuffle bytes=1836
Reduce input records=131
Reduce output records=131
Spilled Records=262
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=245
CPU time spent (ms)=2700
Physical memory (bytes) snapshot=291491840
Virtual memory (bytes) snapshot=3782098944
Total committed heap usage (bytes)=138350592
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1366
File Output Format Counters
Bytes Written=1306
7.查看文件输出结果 hadoop fs -ls /output
运行输出情况见下:
hadoop@master:~$ hadoop fs -ls /output
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2017-08-13 20:12 /output/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 1306 2017-08-13 20:12 /output/part-r-00000
8.查看词频统计结果
hadoop fs -cat /output/part-r-00000
运行输出情况见下:
hadoop@master:~$ hadoop fs -cat /output/part-r-00000
(BIS), 1
(ECCN) 1
(TSU) 1
(see 1
5D002.C.1, 1
740.13) 1