R语言
1.数据准备:
manager <- c(1, 2, 3, 4, 5)
date <- c("10/24/08", "10/28/08", "10/1/08", "10/12/08", "5/1/09")
country <- c("US", "US", "UK", "UK", "UK")
gender <- c("M", "F", "F", "M", "F")
age <- c(32, 45, 25, 39, 99) #99代表年龄缺失
q1 <- c(5, 3, 3, 3, 2)
q2 <- c(4, 5, 5, 3, 2)
q3 <- c(5, 2, 5, 4, 1)
q4 <- c(5, 5, 5, NA, 2)
q5 <- c(5, 5, 2, NA, 1)
leadership <- data.frame(manager, date, country, gender, age, q1, q2, q3, q4, q5, stringsAsFactors=FALSE)

2.选取指定的列
选取除“q3、q4”以外的数据:
myvars <- names(leadership) %in% c("q3", "q4")这行代码的意思是从names(leadership)中的每一个检查其中的每一个元素是否被包含于c(“q3”, “q4”),所以myvars一个由真假值组成的vector:
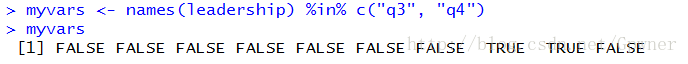
newdata<-leadership[!myvars]
那么这就可以选出leadership中不是q3、q4的列:
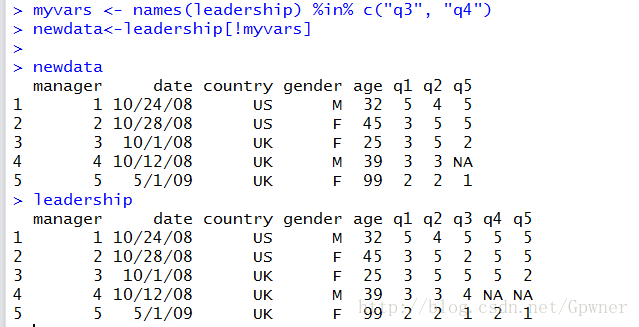
3.每次间隔N行选取
以三行为组(最后一组可能不满三行),只选取第一行
leadership[c(TRUE, FALSE, FALSE),]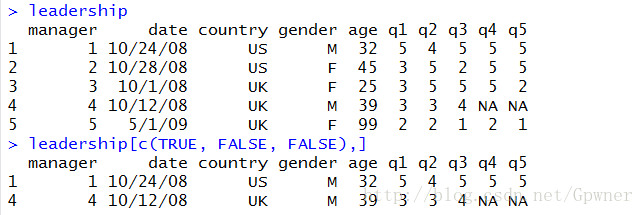
从执行结果上可以看到选出了第一行、第四行
4.每隔N列选取
以三列为组(最后一组可能不满三列),只选取第一列
leadership[c(TRUE, FALSE, FALSE)]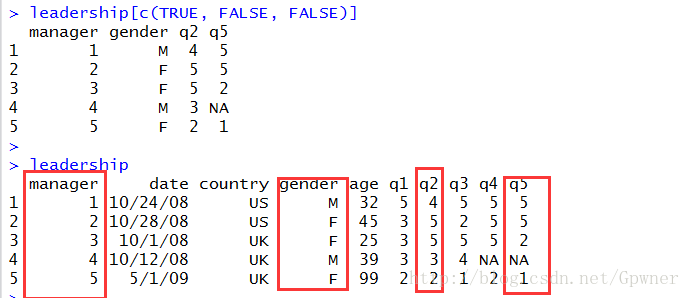
从执行结果看,只保留了第一列、第四列、第七列、第十列
当然,可以随意根据需求更改代码中的TRUE、FALSE
需要注意的是每隔N行选取和每隔N列选取的代码只是相差了一个逗号