决策树、随机森林、逻辑回归、SVM、XGBoost重要参数
决策树、随机森林、逻辑回归、SVM、XGBoost重要参数
- 一、决策树
- 二、随机森林
- 三、逻辑回归
- 四、SVM
- 五、XGBoost
一、决策树

分类树的8个重要参数:criterion、2个随机性相关的参数(random_state,splitter)、5个剪枝参数(max_depth、min_samples_split、min_samples_leaf、max_feature、min_impurity_decrease)。
1、criterion:不纯度计算方法,信息熵entropy和基尼系数gini,默认gini。
2、random_state:设置分枝中随机模式的参数,默认为None。
3、splitter:控制决策树中的随机选项。best和random,默认最佳分枝best(分枝虽随机,但会优先选择更重要的特征分枝)。
4、max_depth:树大最大深度,建议从3开始尝试。
5、min_samples_split:一个节点至少包含min_samples_split个训练样本,默认为2。
6、min_samples_leaf:一个节点在分枝后的每个子节点都必须包含min_samples_leaf个训练样本,建议从5开始尝试。
7、max_features:限制分枝时考虑的特征个数(和max_depth异曲同工)。
8、min_impurity_decrease:限制信息增溢的大小,信息增溢小于设定数值的分枝不会发生。
网格搜索调参
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
times = time()
parameters = {'splitter':('best','random')
,'criterion':("gini","entropy")
,"max_depth":[*range(1,10)]
,'min_samples_leaf':[*range(1,50,5)]
,'min_impurity_decrease':[*np.linspace(0,0.5,20)]
}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10)
GS.fit(Xtrain,Ytrain)
print("时间:{}".format(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f")))
GS.best_params_
GS.best_score_
二、随机森林

重要参数:
1、控制基评估器的参数:criterion、max_depth、min_samples_split、min_samples_leaf、max_feature、min_impurity_decrease。
2、n_estimators:森林中树木的数量,即基评估器的数量。n_estimators越大,模型的效果越好。n_estimators的默认值在现有版本的sklearn中是10,但是在即将更新的0.22版本中,这个默认值会被修正为100。一般来说,0-200选一个数会比较好。
3、random_state:控制生成森林的模式。而在分类树最后,一个random_state只控制生成一棵树。
4、bootstrap:控制抽样技术的参数,默认为True,代表有放回的抽样技术。
5、oob_score:查看在袋外数据上测试的结果。
网格搜索调参:
from sklearn.ensemble import RandomForestClassifier
times = time()
parameters = {'n_estimators':np.arange(0, 200, 10)
,'max_depth':np.arange(1, 20, 1)
,'max_leaf_nodes':np.arange(25,50,1)
,'criterion':['gini', 'entropy']
,'min_samples_split':np.arange(2, 12, 1)
,'min_samples_leaf':np.arange(1, 11, 1)
,'max_features':np.arange(5,30,1)}
rfc = RandomForestClassifier(random_state=25)
GS = GridSearchCV(rfc, parameters, cv=5)
GS.fit(Xtrain,Ytrain)
print("时间:{}".format(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f")))
GS.best_params_
GS.best_score_
三、逻辑回归

重要参数:
1、penalty: l1和l2,默认l2.若选择"l1"正则化,参数solver仅能够使用求解方式”liblinear"和"saga“,若使用“l2”正则化,参数solver中所有的求解方式都可以使用。
2、C正则化强度的倒数,默认为1。C越小,损失函数越小,小到我们认为找到了优秀的参数,从而不会去找更优秀的参数,因此在一定程度上减少过拟合的发生。
网格搜索调参:
from sklearn.linear_model import LogisticRegression as LR
times = time()
parameters = {'penalty':['l1','l2'],
'C':np.linspace(0.05,1,19)}
lr = LR().fit(Xtrain,Ytrain)
GS = GridSearchCV(lr, parameters, cv=10)
GS.fit(Xtrain,Ytrain)
print("时间:{}".format(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f")))
四、SVM
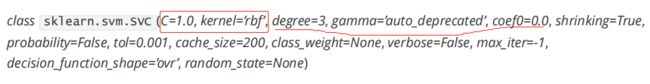
重要参数:
1、非线性SVM与核函数kernel

多项式核函数要消耗大量的时间,运算非常的缓慢。
2、硬间隔与软间隔:重要参数C
C:默认为1,必须大于等于0
学习曲线调参:
#调线性核函数
score = []
C_range = np.linspace(0.01,30,50)
for i in C_range:
clf = SVC(kernel="linear",C=i,cache_size=5000).fit(Xtrain,Ytrain)
score.append(clf.score(Xtest,Ytest))
print(max(score), C_range[score.index(max(score))])
plt.plot(C_range,score)
plt.show()
五、XGBoost
XGBoost的sklearn API
XGBoost回归树

- 梯度提升树
1、XGBoost的基础是梯度提升树,提升集成算法:重要参数n_estimators,默认100。
2、有放回随机抽样:重要参数subsample。随机抽样时抽取的样本比例,范围[0,1],默认为1。np.linspace(0.05,1,20)
3、迭代决策树:重要参数eta。集成中的学习率,又称步长,以控制迭代速率,常用于防止过拟合,默认0.1,取值范围[0,1]。[0.01,0.015,0.025,0.05,0.1] - XGBoost
1、选择弱评估器:booster:梯度提升树gbtree,抛弃提升树dart,线性模型gblinear。[“gbtree”,“gblinear”,“dart”]
2、参数化决策树fk(x):L1正则项参数reg_alpha,默认为0,取值范围[0,正无穷)np.arange(0,5,0.05);L2正则项参数reg_lambda,默认为1,取值范围[0,正无穷)np.arange(0,2,0.05)
3、让树停止生长,gamma默认为0,取值范围[0,正无穷),对梯度提升树影响最大的参数之一。np.arange(0,5,0.05)
4、过拟合:剪枝参数
max_depth:树的最大深度,默认为6,功能与gamma类似
colsample_bytree:每次生成树时随机抽样特征的比例,默认为1
colsample_bylevel:每次生成树的一层时随机抽样特征的比例,默认为1.
通常当我们获得了一个数据集后,我们先使用网格搜索找出比较合适的n_estimators和eta组合,然后使用gamma或者max_depth观察模型处于什么样的状态(过拟合还是欠拟合,处于方差-偏差图像的左边还是右边?),最后再决定是否要进行剪枝。
XGBoost分类
