【STL】迭代器与Traits编程技法(四)
一、概念
【迭代器】
迭代器(iterators)是一种抽象的概念,设计模式中的迭代器模式定义如下:提供一种方法,使之能够依序巡访某个聚合物(容器)所含的各个元素,而又无需暴露该聚合物的内部表达方式。
STL的中心思想在于:将数据容器和算法分开,彼此独立设计,最后再以一贴胶着剂将它们撮合在一起。而迭代器就是这个胶着剂。
为了不暴露容器内部的表达方式,将迭代器的开发工作交给每个容器的设计者,如此一来,所有的实现细节反而得以封装起来,不被使用者看到。STL容器都提供有专属的迭代器缘故。
【Traits编程技法】
traits编程技法大量运用于STL中,它利用“内嵌型别”的编程技法与编译器的template参数推导功能,增强了C++未提供的关于型别认证方面的能力。
traits编程技法只是一种技巧,它的有效运作要依赖于迭代器。下文在介绍迭代器的用法时会同时介绍如果用traits编程技法会带来什么效果。
二、迭代器与Traits关系
2.1 迭代器型别定义变量类型(模板参数推导)
【问题】
如何以“迭代器所指对象的型别”(这里称为value type)为型别来定义一个变量呢?
由于C++只支持sizeof(),并未支持typeof(),即使动用RTTI性质中的typeid(),获得的也只是型别名称,不能拿来做变量声明之用。
【解决办法】
可以利用function template的参数推导机制。
例如:
template<class I, class T>
void func_impl(I iter, T t)
{
T tmp; //这里解决以迭代器所指型别来定义一个变量。
//...
}
template<class I>
inline void func(I iter)
{
func_impl(iter, *iter);
}
int main()
{
int i;
func(&i);
}
编译器会自动进行template参数推导,于是就导出了型别T。
2.2 迭代器型别定义函数返回值类型(内嵌型别)
【问题】
在2.1中我们利用“template参数推导”出了函数参数型别,但是无法推导函数的返回值类型。
【解决办法】
通过声明内嵌型别可以解决上述问题。
例如:
template <class T>
struct MyIter
{
typedef T value_type; //内嵌型别声明
T* ptr;
MyIter(T* p=0) : ptr(p){}
T& operator*() const{return *ptr;}
//...
};
template<class T>
typename I::value_type func(I ite)
{return *ite;}
MyIter<int> ite(new int(8));
cout << func(ite);
【注意】
func()的返回型别必须加上关键字typename,因为T是一个template参数,在它被编译器具现化之前,编译器对T一无所知,即编译器不知到MyIter代表的是一个型别或是一个member function或是一个data member,关键词typename的用意在于告诉编译器这是一个型别,这样才能顺利编过。
2.3 偏特化
【问题】
并不是所有的迭代器都是class type。原生指针就不是。如果不是class type,就无法为他定义内嵌型别了,但STL绝对必须接受原生指针作为一种迭代器。
【解决办法】
template partial specialization 可以解决上述问题。所谓partial specialization的意思是提供另一份template的定义式,而其本身仍为templatized。
如果class template拥有一个以上的template参数,我们可以针对其中某个(或数个,但非全部)template参数进行特化工作。
例如:
template
class C { ... }; //这个泛化版本允许(接受)T为任何类型。
特化版本:
template
class C {...}; //这个特化版本仅适用于“T为原生指针”的情况。
//“T为原生指针”便是“T为任何类型”的一个更近一步的条件限制。
这个偏特化就解决了“内嵌型别”针对原生指针并非class type而无法定义内嵌型别的问题。
2.4 Traits(萃取)
上述说道的参数推导及定义内嵌型别说道的都是迭代器的特性之一value type。我们看看如果用Traits技法会是什么样的一个结果。
value type萃取模板
template <class I>
struct iterator_traits
{
typedef typename I::value_type value_type;
}
所谓的traits是指如果I定义有自己的value type,那么通过这个traits的作用,萃取出来的value type就是I::value_type。
例如:
template<class T>
typename I::value_type func(I ite)
{return *ite;}
//可写成这样
template<class T>
typename iterator_traits<I>::value_type func(I ite)
{return *ite;}
iterator_traits::value_type
相对于
I::value_type
多了一层间接性,这有什么好处呢?好处是traits可以拥有偏特化版本。我们令iterator_traites拥有一个偏特化版本,如下:
template <class T>
struct iterator_traits<T*>
{
typedef T value_type;
}
于是,原生指针int* 虽然不是一种class type,则通过traits取其value type。
针对“指向参数对象的指针(pointer-to-const)”特化版本如下:
template <class T>
struct iterator_traits<const T*>
{
typedef T value_type;
}
现在不论面对的迭代器是class type还是原生指针int* 或const int*这种,都可以通过traits取出正确的value type。
图2-4说明了traits所扮演的“特性萃取机”的角色。
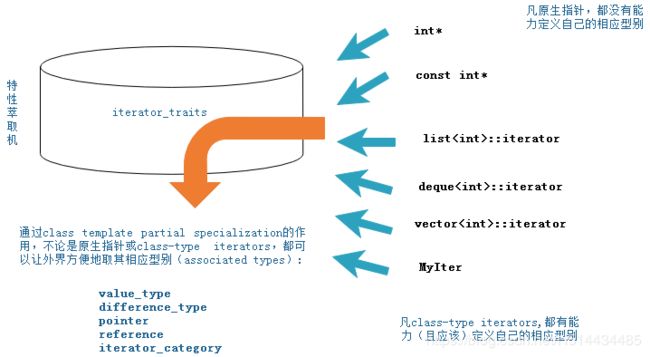
若要这个“特性萃取机”traits能够有效运作,每一个迭代器必须遵循约定,自行以内嵌型别定义的方式定义出相应的型别,这是一个约定。
三、迭代器的型别
迭代器的型别分为以下几种:
template<class I>
struct iterator_traits{
typedef typename I::iterator_category iterator_category;//迭代器分类
typedef typename I::value_type value_type;//相应型别
typedef typename I::difference_type difference_type;//两个迭代器之间的距离
typedef typename I::pointer pointer;//指针
typedef typename I::reference reference;//引用
};
- 如果你希望你所开发的容器能与STL水乳交融,那你一定要为你的容器的迭代器定义这五种相应型别。
- iterator_traits必须针对传入的型别为pointer及pointer-to-const设计特化版本。
3.1 value type
value type是指迭代器所指对象的型别。任何一个打算与STL算法有完美搭配的class,都应该定义自己的value type型别。
3.2 difference type
diffenence type用来表示两个迭代器之间的距离,因此它也可以用来表示一个容器的最大容量,因为对于连续空间的容器而言,头尾之间的距离就是其最大的容量。
例如:
template<class I, class T>
typename iterator_traits<I>::difference_type count(I first, I last, const T& value)
{
typename iterator_traits<I>::difference_type n = 0;
for( ; first != last; ++first)
if(*first == value)
++n;
return n;
}
针对相应型别的difference type,traits的如下两个针对原生制作的而写的特化版本,以C++内建的ptrdiff_t作为原生指针的difference type。
template <class I>
struct iterator_traits
{
...
type typename I::difference_type difference_type;
...
};
针对原生指针而设计的偏特化版本
template <class T>
struct iterator_traits<T*>
{
...
typedef ptrdiff_t difference_type;
...
};
针对原生的pointer-to-const而设计的偏特化版本。
template <class T>
struct iterator_traits<const T*>
{
...
typedef ptrdiff_t difference_type;
...
}
3.3 reference type
这个主要是指在C++中,函数如果要传回左值,都是以by reference(T&)的方式进行的。也就是说你可以修改函数传回的值。如果不想修改那就不要以reference type设置函数传回值。
3.4 pointer type
这个就是地址类型,即函数传回的左值是表示所指之物的地址。这个针对原生指针pointer和pointer-to-const也设计了偏特化版本。可参考4.2。
3.5 iterator_category
这个是指迭代器的分类,根据移动特性和施行操作,可分为五类:
- Input Iterator:表示迭代器所指对象不允许外界改变,只读。
- Output Iterator:只可写。
- Forward Iterator:允许“写入型”算法在此种迭代器所形成的区间上进行读写操作。
- Bidirectional Iterator:可双向移动。某些算法需要逆向走访某个迭代器区间(例如逆向拷贝某范围内的元素),可以使用此种迭代器。
- Random Access Iterator:前四种迭代器都只供应一部分指针算术能力(前三种支持operator++,第四种再加上operator–),第五种则涵盖所有指针算术能力,包括p+n, p-n,p[n],p1-p2,p1 < p2。
迭代器的分类与从属关系如下图4-5:
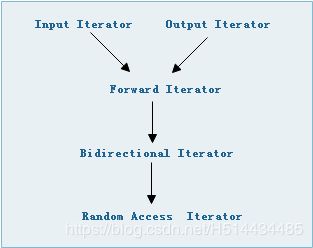
图3-5
这种从属关系不是继承关系,而是所谓的概念与强化关系。
在设计算法时,为提供最大效率我们需要为某种迭代器提供一个明确的定义,并针对更强化的某种迭代器提供另一份定义,这样才能在不同情况下提供最大效率。假设有个算法用Forward Iterator最合适,但你将Random Access Iterator传给它也行,因为根据图4-5的从属关系,这样是可以的,但这并不是表示最佳的,因为算法内部会根据不同的类型做特殊的性能优化。
四、_ _type_traits
iterator_traits负责萃取迭代器的特性,也就是我们前文所述内容。
_ _type_traits负责萃取型别的特性,这里所关注的型别特性是指:
- 是否具备non-trival defalt ctor。
- 是否具备non-trivial copy ctor。
- 是否具备non-trival assignment。
- 是否具备non-trival dtor。
如果答案是否定的,我们在对这个型别进行构造、析构、拷贝、赋值等操作时,就可以采用最有效率的措施。例如根本不调用身居高位,不谋实事的那些constuctor,destructor,而直接采用内存处理的操作如malloc(),memcpy()等等,获得最大效率。
SGI内部针对__type_traits定义的一些typedefs。
template <class type>
struct __type_traits {
typedef __true_type this_dummy_member_must_be_first;
/* Do not remove this member. It informs a compiler which
automatically specializes __type_traits that this
__type_traits template is special. It just makes sure that
things work if an implementation is using a template
called __type_traits for something unrelated. */
/* The following restrictions should be observed for the sake of
compilers which automatically produce type specific specializations
of this class:
- You may reorder the members below if you wish
- You may remove any of the members below if you wish
- You must not rename members without making the corresponding
name change in the compiler
- Members you add will be treated like regular members unless
you add the appropriate support in the compiler. */
typedef __false_type has_trivial_default_constructor;
typedef __false_type has_trivial_copy_constructor;
typedef __false_type has_trivial_assignment_operator;
typedef __false_type has_trivial_destructor;
typedef __false_type is_POD_type;
};
这些值不是__true_type就是__false_type。
struct __true_type
{
};
struct __false_type
{
};
由于编译器只会对class object形式的参数进行推导,所以定义两个空白classes。这两个classes无任何成员,不会带来额外负担,却又能标示真假。,我们编译器参数推导需求。