pandas快速入门
pandas
Pandas的名称来自于面板数据(panel data)和Python数据分析(data analysis)。
Pandas是一个强大的分析结构化数据的工具集,基于NumPy构建,提供了 高级数据结构 和 数据操作工具,它是使Python成为强大而高效的数据分析环境的重要因素之一。
pandas的常用数据类型
1、Series 一维,带标签数组(相对于numpy的数组,多了一列标签)
2、DataFrame 二维,Series容器,(单独的一列拿出来就是一个series,因此是容器),类似普通的数据库形式
Series
ndarray是可以使用for循环遍历的
series同样可以,遍历的时候,标签会被去掉
Series创建
series中的index对应的是字典中的key,而非列表的下标
可以通过ndarray、列表、字典进行创建,具体代码如下:
# 未指定index时,默认从0开始自增,类似mysql数据库自增主键
a = pd.Series(np.arange(10))
# 指定index,需要index的长度与数组的长度保持一致
b = pd.Series(np.arange(10), index=list(string.ascii_uppercase[:10]))
# 字典数据无需指定index,字典的key是index,value是具体的值
data = {string.ascii_uppercase[i]: i for i in range(10)}
c = pd.Series(data)
# 字典数据人为指定index,如果与字典的key相同,则转换字典数据,与key不对应的index,默认以NaN填充
d = pd.Series(data, index=list(string.ascii_uppercase[5:15]))
# 可迭代对象创建
e = pd.Series(range(10))
# 列表创建
f = pd.Series([1, 2, 3, 4])
Series修改数据类型和numpy雷同
f = f.astype(np.float64) # f就是上边代码的f
name属性
可以通过赋值进行设置,也可以通过属性直接获取名字
对象名:series.name
对象索引名:series.index.name
c.name = 'number'
c.index.name = 'index'
print(c.name)
print(c.index.name)
Series的索引
取一个值的时候,类似列表或字典取值,直接传入一个下标或者index即可,取多个值的时候,需要传入下标或index的列表
例子:
f = pd.Series([1, 2, 3, 4], index=list(string.ascii_lowercase[:4]))
# 索引取单值
print(f[0]) # 位置索引,和列表下表雷同
print(f['d']) # index索引,和字典通过key获取value雷同
# 索引取多值,得到series
print(f[[0, 1]])
print(f[['a', 'b']])
print(f[['a', 'e']]) # e不存在,以NaN填充
# print(f[[0, 5]]) 报错,因为5这个下标不存在
# print(f[['f']]) 报错 f不存在
# print(f['f']) 报错 f不存在
综上,索引方式较列表更为丰富,可取单值,多值,下标索引,index索引(类字典)
单值索引取出单值,多值索引取出Series
Series 切片
data = {string.ascii_uppercase[i]: i for i in range(10)}
c = pd.Series(data)
print(c[0:2])
print(c['A':'C']) # 相较于下标切片,他包含有C对应的value,能取到末尾
print(c['a':'c']) # 不存在此index,取出空series
print(c[0:5:2])
print(c[c > 4]) # 布尔索引,和numpy类似
综上,切片可与列表用相同的方式切出,同时还支持使用index进行切片的方式切出
Series的索引和值
通过Series的两个属性来获取索引(index属性)和值(values属性)
print(c.index) # 得到Index类型
print(c.values) # 得到ndarray类型
总结
Series本质上由两个数组构成,一个数组构成对象的键(index,类字典的key),一个数组构成对象的值(values,类字典的value),同样是一个个键值对存在
ndarray的很多方法都可以运用在series类型,如argmax,clip等
很多方法中都有inplace参数,用来指定是更改原数组或Series的值,还是返回一个新对象
series的where方法和ndarray不同??????????TODO 需要详细对比了解下
read_csv的文件名不要带中文,会报错 还需要多测试几次
读取文件数据
csv、网站等数据
# 返回的是dataframe类型
pd.read_csv('filepath or url')
读取mysql
pd.read_sql() 具体使用需要研究一下
读取mongodb,还不知道是哪个命令
DateFrame
二位数组,结构上类似传统数据库,有行索引和列索引
numpy中的二位数组传递进来就变为DateFrame类型:pd.DateFrame(np.arange(12).reshape((3,4)))
创建DateFrame类型
通过二维数组创建
# 通过index和column参数指定行索引和列索引
a = pd.DataFrame(np.arange(12).reshape((3, 4)), index=list(string.ascii_lowercase[:3]), columns=list(string.ascii_uppercase[:4]))
通过字典创建
# key变为列索引,不存在的key以NaN填充
b = [{'a': 1, 'b': 2}, {'a': 2, 'b': 3, 'c': 7}, {'a': 4, 'b': 5}]
c = pd.DataFrame(b)
print(c)
# key变为列索引,对应列表变为具体的值
d = {'a': [1, 3, 4], 'b': [2, 4, 5]} # a b必须拥有相等的长度,否则报错
e = pd.DataFrame(d)
print(e)
# 以下为结果
a b c
0 1 2 NaN
1 2 3 7.0
2 4 5 NaN
a b
0 1 2
1 3 4
2 4 5
DateFrame基础属性和方法
# 和numpy类似,有很多表明df基本信息的属性
df.shape # 行数,列数
df.dtypes # 列数据类型,结果为Series类型
df.ndim # 数据维度
df.index # 行索引,和series中的index一个意思
df.columns # 列索引
df.values # 对象值,二维数组
注意:行索引和列索引都是Index类型
DataFrame整体情况查询
df.head(3) # 显示头三行,默认五行
df.tail(3) # 显示末三行,默认5行
df.info() # 相关信息:行数,烈属,列索引,列非空值个数,列类型,内存占用
df.describe() # 快速综合统计结果:每一列的计数,均值,标准差,最大值,最小值,四分位数
DataFrame排序
df.sort_values(by='a', ascending=False) # ascentding默认升序
df.sort_values(by=['a','b'], ascending=False) # 先以a排序,当a相等时,以b进行排序
pandas取行或列
注意:不需要掌握中括号的方式,不推荐
单独取一列:print(f['A'])取出A列的数据,得到series
loc方式
此方式通过标签取值,通俗讲通过行索引或列索引进行操作,即index和column的名称取
f = pd.DataFrame(np.arange(12).reshape((3, 4)), index=list(string.ascii_lowercase[:3]),columns=list(string.ascii_uppercase[:4]))
# 取出一列,取出的结果是series
print(f.loc[:, 'A'])
print(type(f.loc[:, 'A']))
# 取出多列,如A-C列,取出的结果是dataframe
print(f.loc[:, 'A':'C'])
# 取出某行某列,即对应的某一个位置的值,单独的值被取出
print(f.loc['a', 'A'])
# 取出两行两列,取出dataframe
print(f.loc['a':'b', 'A':'B'])
# 取出指定的某几列的数据,如A,C,取出dataframe
print(f.loc[:, ['A', 'C']])
# 取出指定的某几列某几行的数据,取出dataframe
print(f.loc[['a', 'c'], ['A', 'C']])
# 取出指定某一行的所有数据,结果是series
print(f.loc['a', :])
print(f.loc[['a'], :])
# 取出指定某一行的某几列数据,结果是series
print(f.loc['a', ['A', 'C']])
# 需要取出的结果是dataframe
print(f.loc[['a'], ['A', 'C']])
iloc方式
此方式通过位置索引取值,通俗讲就是下标,如取第几行第几列的数据
代码同样以loc方式生成的数据为例进行
整体方式和loc没什么区别,可以使用切片方式,也可以使用逗号的方式,仅仅是将行索引和列索引变更为对应的行下标和列下标,如第2行第5列,第2-5行第5-6列等等。
布尔索引
和numpy的布尔索引类似
print(f[f > 5]) # 小于5的被nan替换
print(f['C'] > 5)
print(f[f['C'] > 5]) # 只要C列数据大于5,那么这一行数据均返回
print(f[(f['C'] > 5) & (f['A'] > 4)]) # 注意条件需要带上括号,否则报错
print(f[(f['C'] > 5) | (f['A'] < 4)]) # 注意条件需要带上括号,否则报错
注意点:不同的条件之间需要用括号括起来
pandas的字符串方法
str方法属于series独有,dataframe没有此方法,也就是说从dataframe中取出来的必须是个series
使用方式为:sh['date'].str 如此即可得到str对象
print(sh['date'].str.len()) # 得到series,每一行的字符串长度全部获取
print(sh.loc[:, 'date'].str.len()) # 和上边的一个性质
print(sh['date'].str.contains('2')) # 返回布尔类型,是否包含2

缺失值处理
主要使用fillna方法进行处理
注意在pandas中计算均值等运算时,nan不参与运算,numpy中是会参与运算的
g = pd.DataFrame(np.arange(24).reshape((4, 6)), index=list(string.ascii_uppercase[:4]),
columns=list(string.ascii_uppercase[4:10]))
print(g)
# 将数据里的部分数据替换为nan和0
g.loc['A', 'G'] = 0
g.loc['C', 'H'] = np.nan
g.loc['B', 'H'] = np.nan
g.loc['D', 'F'] = np.nan
print(g)
# 判断数据是否为nan,得到布尔类型的数据
# print(pd.isnull(g))
# print(pd.notnull(g))
# 使用fillna方法进行填充,此方式有返回值,可通过参数设置没有返回值
g.fillna(g.mean(), inplace=True) # 替换为每列的均值
g.fillna(g.median(), inplace=True) # 替换为每列的中值
g.fillna(0, inplace=True) # 替换为0
print(g)
# 计算某一列的平均值
print(g['F'].mean())
# 只填充有NaN的某一列
print(g['F'].fillna(g['F'].mean(), inplace=True))
一般情况下,数据存储方式是以列来存储同一类型的数据,因此填充缺失值时往往是以列均值填充,一般没有使用行均值进行填充的,即使需要用行均值进行填充,依然可以通过转置,将数据转换后,依旧按列进行填充即可。无需深究如何以行均值填充缺失值,没有意义。
关于0值,看情况是否需要将其转换为nan,如果需要使用 g[g==0]=np.nan 布尔索引的方式赋值
删除缺失值
g.dropna(axis,how)
axis指定按行还是列删除,how指定any或all,any表示只要有一个nan,就删除,all表示全部为nan时才删除
pandas常用统计方法
基本上和numpy的统计方法雷同
max,argmax,min,argmin,median,mean等等,如果有具体需求,搜索查看是否有相关方法
tolist()和to_dict()
tolist()可以讲series中存储的列表数据,转存到一个大列表中,形成列表嵌套列表,可以直接转换为二位数组的列表
to_dict()可以将dataframe转为字典格式,当在做特征抽取时,会用到此方法,因为需要字典数据进行one-hot编码处理
one-hot编码的手动实现思路
需求:统计每个电影都属于哪些类别,最后能够汇总统计每个类别有多少电影?
解决:构造一个列数等于类别数,行数等于电影数的全为0的数组,然后以电影类别为列名,电影名作为行名,将其构造为dataframe类型,然后遍历每个电影有什么类别,将0改为1即可。
具体代码如下:
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
file_path = "./IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
print(df["Genre"].head(3))
#统计分类的列表
temp_list = df["Genre"].str.split(",").tolist() #[[],[],[]]
genre_list = list(set([i for j in temp_list for i in j]))
#构造全为0的数组
zeros_df = pd.DataFrame(np.zeros((df.shape[0],len(genre_list))),columns=genre_list)
# print(zeros_df)
#给每个电影出现分类的位置赋值1
for i in range(df.shape[0]):
#zeros_df.loc[0,["Sci-fi","Mucical"]] = 1
zeros_df.loc[i,temp_list[i]] = 1
# print(zeros_df.head(3))
#统计每个分类的电影的数量和
genre_count = zeros_df.sum(axis=0)
print(genre_count)
#排序
genre_count = genre_count.sort_values()
_x = genre_count.index
_y = genre_count.values
#画图
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(len(_x)),_y,width=0.4,color="orange")
plt.xticks(range(len(_x)),_x)
plt.show()
数据合并
类似sql的join,目的是通过某些相同的条件,来得到另一个表更多的信息,如学生表和班级表,每个学生都有一个班级的id,通过这个id进行join,就可以得到联合表结果,从这个结果中可以得到每个学生班级的名称等一系列信息。
join和merge对应的均是标准sql中的join用法,区别在于join默认是以行索引对齐进行连接,on参数是用来指定以哪列来对齐,但是这一列需要变为行索引才可以进行连接,这是他的限制,个人感觉如果就需要以默认的行索引进行拼接,就是用join,否则使用merge即可。
merge是完全符合标准sql的join用法,how用来指定连接方式,on用来指定连接的条件
join
join提供了方便的以行索引进行连接查询的方式。
理解为sql中的join的用法即可,包括left,right,inner,outer,这几项通过how参数进行设置
on的设置没看明白,需要单独研究TODO
当两表(两个数据集)有相同的列名时,需要添加后缀,通过lsuffix和rsuffix进行设置
默认是left join的用法,右表不存在的数据以NaN填充
df1 = pd.DataFrame(np.arange(12).reshape((3, 4)), index=['a', 'b', 'c'], columns=['A', 'B', 'C', 'D'])
print(df1)
df2 = pd.DataFrame(np.arange(15).reshape((5, 3)), index=['a', 'c', 'd', 'e', 'f'], columns=['D', 'F', 'G'])
print(df2)
df = df1.join(df2, lsuffix='l',rsuffix='r') # suffix后缀的意思
print(df)
df = df1.join(df2, how='right', lsuffix='l',rsuffix='r')
print(df)
df = df1.join(df2, how='inner', lsuffix='l',rsuffix='r')
print(df)
可以发现是通过index进行连接的
因此,df1和df2的左右顺序对结果是有影响的
merge
np.random.seed(1)
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': np.random.randn(4)})
df2 = pd.DataFrame({'key': ['B', 'D', 'D', 'E'], 'value': np.random.randn(4)})
print(df1)
print(df2)
# join
df = df1.join(df2, lsuffix='_l', rsuffix='_r')
print(df)
# 通过merge实现join的效果应该如何实现
# 连接后会比join多一列key_0,原因是这一列是指定的条件列,join因为是index是条件,结果中的index已经体现了条件
df = df1.merge(df2, how='left', left_on=df1.index, right_on=df2.index, suffixes=('_l', '_r'))
print(df)
# left_on和right_on用来指定两个表分别以什么列来进行条件的判断
# merge
df = df1.merge(df2, on='key') # 默认内连接
print(df)
df = df1.merge(df2, on='key', how='left') # 左连接
print(df)
df = df1.merge(df2, on='key', how='right')
print(df)
参数on还可以传入列表,以多列进行条件筛选,具体见https://blog.csdn.net/weixin_37226516/article/details/64137043
分组和聚合
通过 df.groupby(by='') 实现
by的值可以是列表内嵌套多个列名,也可以是单独的一个列名,同时还可以是列表内嵌套取出的一列数据
对某几列数据进行分组:
df["Country"].groupby(by=[df["Country"],df["State/Province"]]).count() 参数是两组数据,因为源数据只有country这列,不能直接指定不存在的列名了,所以只能如此取出,感觉没什用处。
结果是迭代器,每个数据都是元组,包含两个数据,第一个是分组依据的结果值,如上述df,分组后的B,D,E,就是这里指的值,第二个是dataframe,是分到某一组的具体数据
实现的的结果,和sql中的类似,也有聚合函数可以使用如:

df = pd.read_csv('./directory.csv')
# 需求,美国和中国哪里的星巴克数量多
# 解决:以Country进行分组,而后统计数量得到结果
# 中国是cn,美国是us,得到结果迭代器对象,遍历得到的是元组
country = df.groupby('Country')
count = country.count() # 统计所有国家的数量,dataframe类型,结果中包含所有的列,任意一列都可作为统计的结果
# 从count中取出index是US和CN的两行一列数据,列可取任意一列,因为数据都相等
us = count.loc['US', 'Brand']
cn = count.loc['CN', 'Brand']
print('us:%s,cn:%s' % (us, cn))
# 需求:中国每个省份星巴克的数量
# 解决:先以国家和省份进行分组,然后使用count,得到复合索引的dataframe,再从中取出CN
# 如果先以国家分组,再以省份分组,需要进行for循环遍历找出CN的那组dataframe
country = df.groupby(by=['Country', 'State/Province'])
count = country.count()
print(count) # ountry和State/Province 共同作为index存在
print(count.loc['CN', 'Brand']) # 先分组再取出特定的列和行
country = df.groupby(by=['Country', 'State/Province'])['Country']
print(country.count().loc['CN']) # series 和上边的执行结果一致,先取出某一列,在此列的基础上进行统计
# 两种方式均可,个人习惯第一种,更加清晰,第二种从分组结果的迭代器中再取出某一列数据,无法直观看到结果
索引和复合索引
普通索引
df = pd.DataFrame(np.arange(12).reshape((3, 4)), columns=['a', 'b', 'c', 'd'])
print(df)
# 获取索引
print(list(df.index))
# 重新设置index
df.index = ['x', 'y', 'z']
print(df)
# 创建一个新索引的新对象,不是表面的reindex的意思
# 相当于从df中取出xzf行的数据组成新df,如果索引不存在,以nan填充
df = df.reindex(list('xzf'))
print(df)
指定某一列成为索引
# 指定某一列成为index,原索引会被删掉
df = df.set_index('a', drop=False) # drop指的是是否在数据中删除a这一列
print(df)
# df = df.set_index('a', drop=False)
df.loc[4, 'b'] = 1
print(df['b'])
# 需求,对某一列的数据进行去重时,可以取出此列,然后使用unique方法实现
print(df['b'].unique()) # 是series的方法,实现去重,得到一维数组
复合索引
可以通过set_index传入列表来指定复合索引,groupby时,如果以多个条件进行分组,也会得到复合索引
df = df.set_index(['a', 'b'])['c']
print(df)
a b
0 1 2
4 5 6
8 9 10
print(df[4])
print(df[4, 5])
可以通过df.swaplevel()进行复合索引里外层位置的交换
更多内容可查阅资料
时间序列
利用date_range(start,end,periods,freq)生成时间序列
start和end以及freq配合能够生成start和end范围内以频率freq的一组时间索引
start和periods以及freq配合能够生成从start开始的频率为freq的periods个时间索引
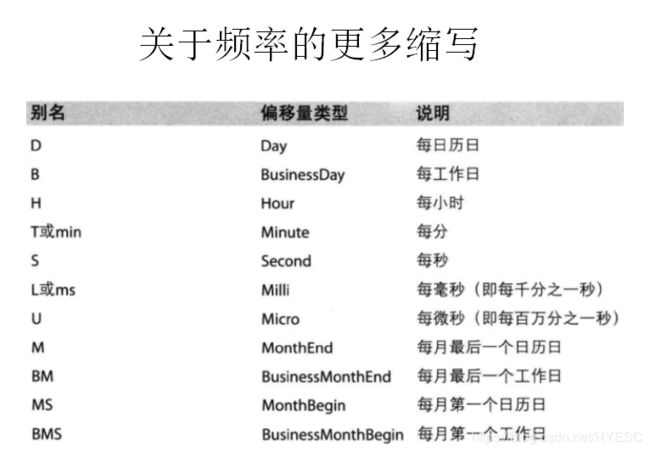
时间的格式支持很多,常见的均支持,更多的可以进入源码内看样例
d = pd.date_range(start='20181101', end='20191101')
d = pd.date_range(start='2018-11-01', end='2018-12-01')
d = pd.date_range(start='2018/11/01', end='2018/12/01')
d = pd.date_range(start='11/01/2018', end='12/01/2018')
时间序列存在的意义:数据中有很多时间格式的数据,当想以时间进行统计时,如按月或季度进行统计,但是数据中的时间是字符串形式存在的,此时就需要将其转换为datetime类型,然后可以按需要的时间进行设置。这个重新设置时间的过程称为重采样。
to_datetime能够将series中的时间转换成datetimeindex
df["timeStamp"] = pd.to_datetime(df["timeStamp"],format="")
format参数大部分情况下可以不用写,但是对于pandas无法格式化的时间字符串,我们可以使用该参数,比如包含中文
python的datetime类型中格式化时间的写法写道format中,就可以识别了
resample重采样
重采样:指的是将时间序列从一个频率转化为另一个频率进行处理的过程,将高频率数据转化为低频率数据为降采样,低频率转化为高频率为升采样
t = pd.DataFrame(np.random.uniform(10, 50, (100, 1)), index=pd.date_range('20180101', periods=100, freq='D'))
# print(t)
# 按月重采样
t= t.resample('M')
print(t) # 返回DatetimeIndexResampler对象
print(t.mean()) # 可以根据结果进行统计
print(t.count())
PeriodIndex
如果原始数据中的时间,如年月日是分开存储的,需要将其合并为一个时间,就用到这个了
# 可以将其转为pandas的时间类型PeriodIndex
periods = pd.PeriodIndex(year=data["year"],month=data["month"],day=data["day"],hour=data["hour"],freq="H")
给原dataframe添加一列数据
df["dtime"] = periods
d = pd.DataFrame(np.arange(12).reshape((3, 4)), index=['a', 'b', 'c'], columns=['A', 'B', 'C', 'D'])
print(d)
d.loc[:, 'E'] = [1, 2, 3] # 直接传递列表,不是series,没有index
print(d)
s = pd.Series(list(range(3)))
print(s)
d['G'] = s # 因为s默认是有索引的,因此和d中的索引不符合,赋值后会导致G这列数据全部是NaN
print(d)
# 解决上边的问题,将series变为列表后再进行赋值,即可快速添加
# 复杂的方式,在获取series时,将其index指定为原df的index
d['F'] = list(s)
print(d)
同时添加多列数据,不清楚怎么添加多列,还是将多列拆分为单列后,添加