0469-如何使用DBeaver访问Kerberos环境下的Impala
Fayson的github: https://github.com/fayson/cdhproject
推荐关注微信公众号:“Hadoop实操”,ID:gh_c4c535955d0f,或者扫描文末二维码。
1.文章编写目的
在前面Fayson的文章《0467-Hadoop客户端工具之Dbeaver安装及使用》和《0468-如何使用DBeaver访问Kerberos环境下的Hive》。本篇文章Fayson主要介绍如何使用DBeaver访问Kerberos环境下的Impala。
测试环境
1.RedHat7.2
2.CM和CDH版本为5.15.0
3.Window Server 2012R2
4.DBeaver版本5.2.5
2.安装Kerberos客户端
1.在Kerberos官网下载,地址如下
https://web.mit.edu/kerberos/dist/index.html
安装过程这里就不在详细说明了。
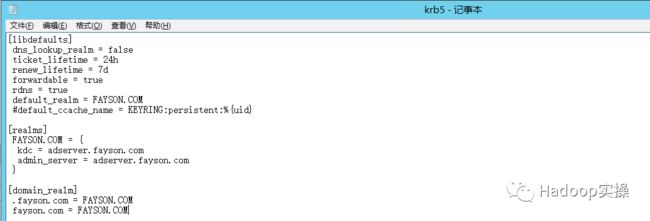
2.将CDH集群的/etc/krb5.conf文件,在Window客户端如下目录创建krb5.ini文件,内容如下:
C:\ProgramData\MIT\Kerberos5\krb5.ini
[libdefaults]
dns_lookup_realm = false
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
rdns = true
default_realm = FAYSON.COM
#default_ccache_name = KEYRING:persistent:%{uid}
[realms]
FAYSON.COM = {
kdc = adserver.fayson.com
admin_server = adserver.fayson.com
}
[domain_realm]
.fayson.com = FAYSON.COM
fayson.com = FAYSON.COM
3.配置环境变量,krb5.ini文件以及Kerberos CredentialCache File的路径
变量名:KRB5_CONFIG,变量值:C:\ProgramData\MIT\Kerberos5\krb5.ini
变量名:KRB5CCNAME,变量值:C:\temp\krb5cache
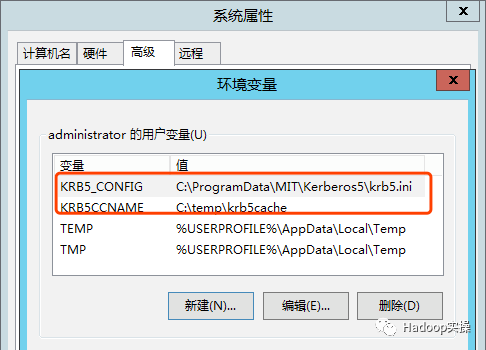
注意:KRB5CCNAME的路径默认是不存在的,因此需要在C盘下创建temp文件夹,krb5cache文件则不需要创建。配置完环境变量后,重启计算机使其生效。
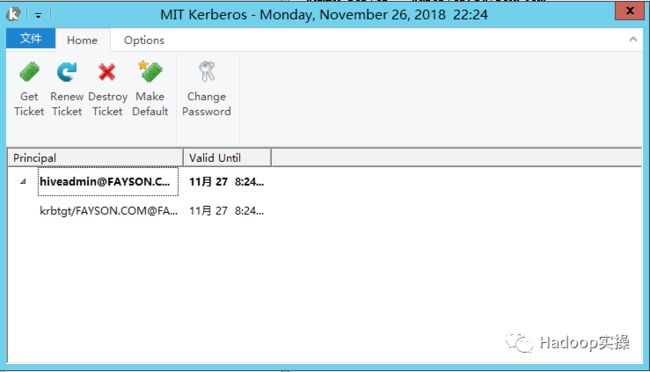
4.完成以上配置后,在Window客户端测试是否能够正常kinit
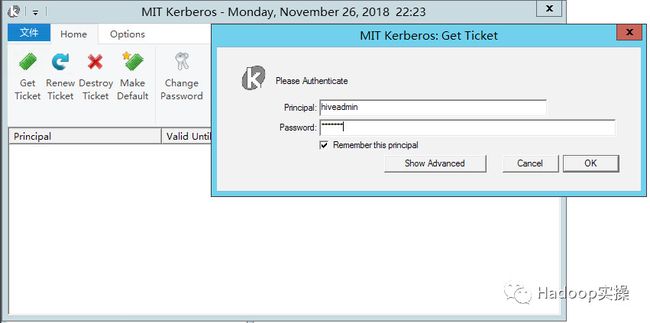
Kinit成功后
3.修改DBeaver配置
因为DBeaver通过JDBC的方式访问Hive,底层也是基于Java环境,所以这里需要在DBeaver的配置中增加JVM的参数,主要添加关于Kerberos相关的配置。
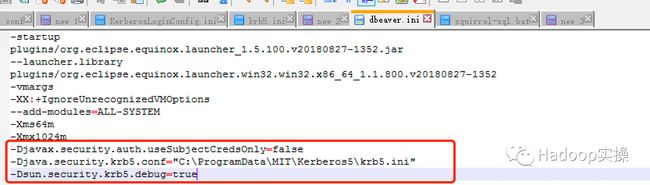
1.进入DBeaver的安装目录,找到dbeaver.ini配置文件,在配置文件末尾增加如下配置:
-Djavax.security.auth.useSubjectCredsOnly=false
-Djava.security.krb5.conf="C:\ProgramData\MIT\Kerberos5\krb5.ini"
-Dsun.security.krb5.debug=true
2.重新启动DBeaver客户端
4.获取Impala JDBC驱动
1.在Cloudera官网下载Impala的JDBC驱动包
https://www.cloudera.com/downloads/connectors/impala/jdbc/2-6-4.html
2.将下载下来的JDBC驱动包解压得到ImpalaJDBC41.jar

5.创建Impala连接
1.点击创建连接,选择“Cloudera Impala”
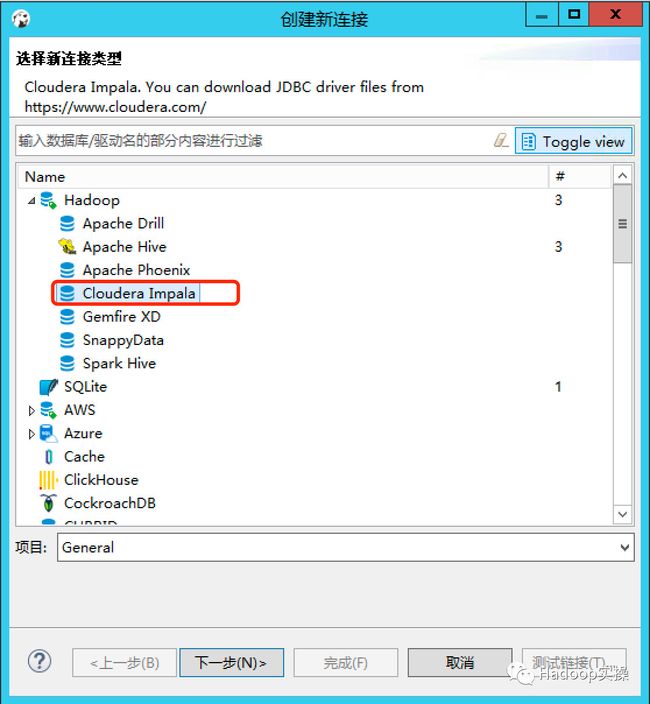
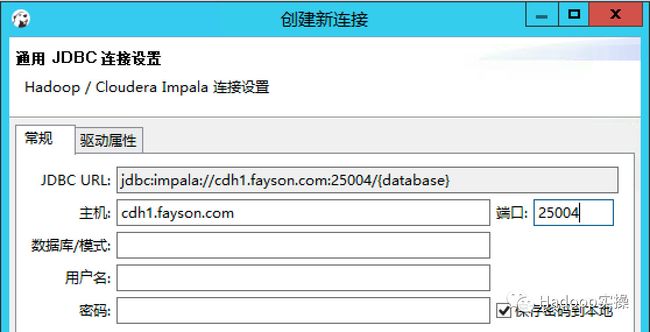
2.点击“下一步”配置JDBC连接信息
这里Fayson的Impala使用HAProxy做了负载均衡,所以访问的端口有所变化
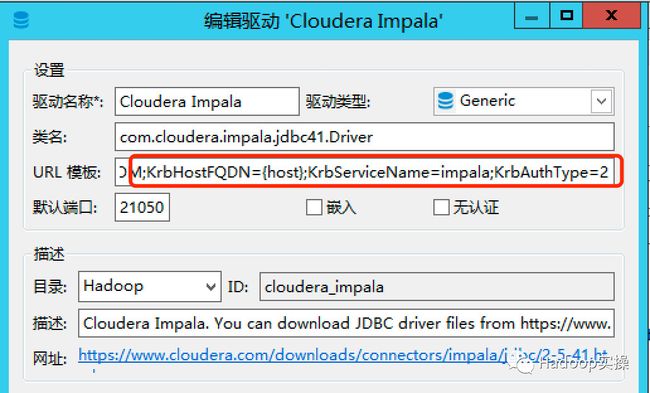
3.编辑驱动设置,修改URL模板为如下地址
jdbc:impala://{host}:{port}/{database};AuthMech=1;KrbRealm=FAYSON.COM;KrbHostFQDN={host};KrbServiceName=impala;KrbAuthType=2
4.添加Impala JDBC驱动包
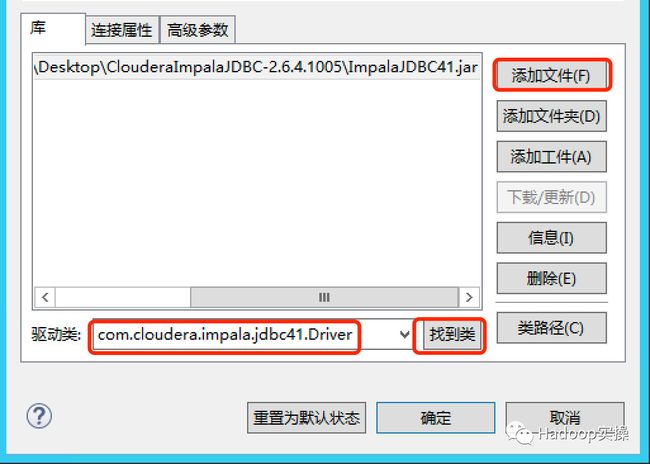
5.完成驱动设置后,选择输入数据库default
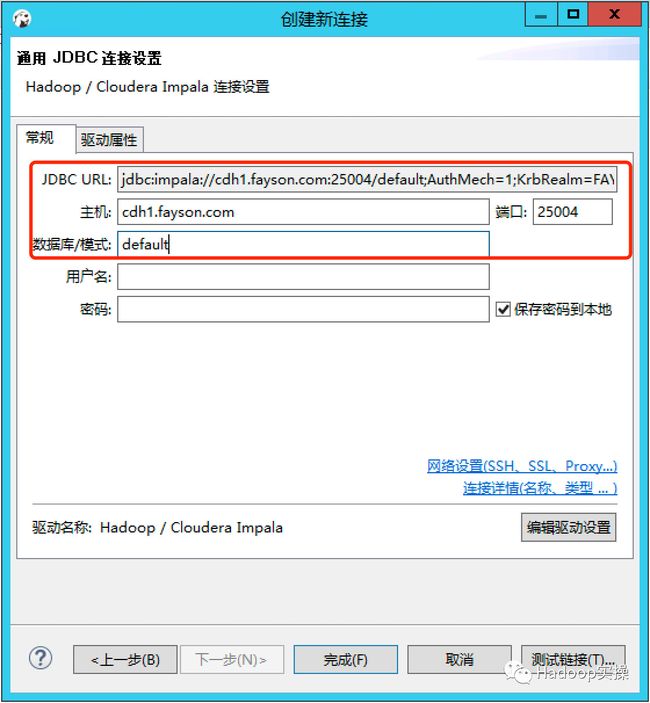
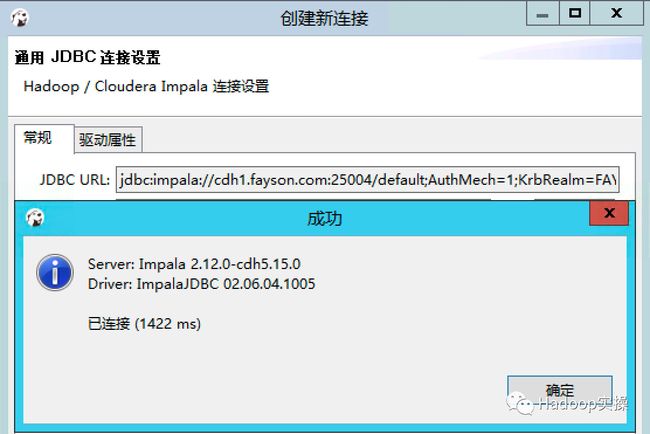
6.点击“测试链接”
6.总结
1.Cloudera提供了Impala JDBC驱动包,在访问Kerberos环境下的Impala时注意JDBC URL地址配置方式。
2.DBeaver客户需要配置Java Kerberos环境的相应参数
3.特别强调在Window机器上配置Kerberos客户端时,需要配置KRB5_CONF和KRB5CCNAME两个环境变量,否则在使用访问时会报“Unable to obtainPrincipal Name for authentication”
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。
原创文章,欢迎转载,转载请注明:转载自微信公众号Hadoop实操

