实时机器学习系统调研
文章目录
- 前言
- 难点
- 实时机器学习的分类[^1]
- 对应部分开源技术
- Mahout
- Spark mllib
- Storm
- FlinkML
- SAMOA
- 其他,是否实时未知
- Beam
- Apache SystemML
- MADlib
- PredictionIO
- 实时推荐系统
- 参考
前言
我把实时机器学习理解为两种情况:
1、 实时出结果:
这时使用的依然是离线训练好的模型,静态的模型,只是该模型需要对实时流入的“测试”集做出响应,给出模型的计算结果。
机器学习本质上是参数的集合,很多时候,静态的机器学习模型无法满足我们的需求,每天海量的数据进入系统,如果能够对新的数据及时加以应用,我们的模型会更加的鲁棒,产生更多的价值。下面个是我理解的第二种情况。
2、 实时自我更新,并出结果:
- 并不是指可以对自身进行反馈的强化学习,而是希望数据能够近实时的feed到模型中,让模型自我更新,并在更新模型后对最新的数据做计算。
- feed到模型的数据也许不只是已有变量的增量,还有可能是新的变量,也就是说模型的可实时扩展性。

参考一些资料以及咨询一些前辈后,发现这种更新,往往都是以几天为一个单位,然后发布新的模型,真实时可能不太现实。
两篇相关论文:
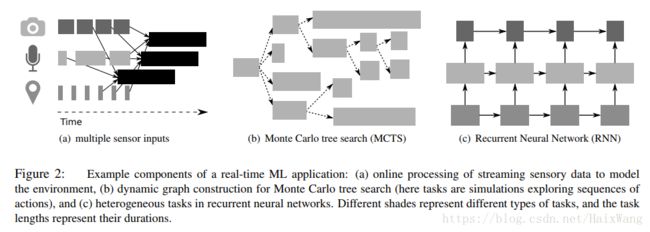
- 除了基于时间线的实时机器学习,论文arXiv:1703.03924v2 [cs.DC] 19 May 2017 – Real-Time Machine Learning: The Missing Pieces把 蒙特卡罗树搜索 和 循环神经网络 也归入实时机器学习:
- 论文Online Machine Learning in Big Data Streams指出:
大数据流中的在线机器学习包括(1)分布式算法和(2)由过去一段时间所存储的有限的流数据驱动的算法。第一个主要涉及软件架构和高效算法。第二个对建模方法施加了重要的理论限制:在数据流模型中,随着新数据的到来,旧数据不再可用于修改早期的次优模型。
这篇长论文主要解释了些实时机器学习 面临的困难,以及目前市场上几种常见实时机器学习框架(Storm、Flink、SparkStreaming + mllib这些 )设计思路以及各自优缺点。

难点
(以下是我的片面理解,毕竟没有经历过)
- 机器学习训练模型以及模型上线使用时大都时很消耗内存迭代式计算,海量数据的场景下,要想实时,很难。数据消费的实时 + 计算的实时。[参考8详细的阐述了该看法]
- 数据毕竟还会涉及清洗问题,所以加入的数据会不会导致模型出问题?多版本模型的上线、回滚问题?
- 在有的场景下,标签数据本身就有延时,比如说欺诈标签:
如果客户报告欺诈交易,我们可以立即将交易标记为“欺诈”。但是,我们应该如何处理剩余的交易?我们可以假设未报告的交易是“非欺诈”,但是这毕竟不准确;但假如不进行认为假设,正负样本也许会失衡。那么,我们应该等多久才能确定它们不是欺诈行为?
实时机器学习的分类1
- 批实时机器学习
- 软实时机器学习
软实时的定义是:响应系统在接收到请求的时候,立即开始对响应进行处理,并且在较短时间内进行反馈。软实时机器学习只要求系统立即对请求开始进行处理,最后处理完成所消耗的时间比较少,但是要求不如硬实时严格。软实时机器学习的主要应用场景是物流运输、较为频繁的数量金融交易等领域。 - 硬实时机器学习
硬实时的定义是:响应系统在接收到请求之后,能够马上对请求进行响应反馈,做出处理。硬实时机器学习的主要应用场景是网页浏览、在线游戏、高频交易等对时效性要求非常高的领域。在这些领域中,我们往往需要将相应延迟控制在若干毫秒以下。
对应部分开源技术
( 仅实时机器学习相关,flume+kafka+redis这些辅助件暂不谈。流式数据采集清洗以及计算结果的存储等可参考 )
Mahout
批实时机器学习:Mahout
Mahout的成立最初基于 Ng et al. 的文章 “Map-Reduce for Machine Learning on Multicore”。提供一些可扩展的机器学习领域经典算法的实现,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。
支持的算法:
-
分布式QR分解(Distributed QR Decomposition)
-
分布式随机主成分分析(Distributed Stochastic Principal Component Analysis)
-
分布式随机奇异值分解(Distributed Stochastic Singular Value Decomposition)
-
普通最小二乘法(Ordinary Least Squares)
-
德宾沃森测试(Durbin Watson Test)
-
Canopy Clustering
-
距离指标(Distance Metrics)
-
推荐貌似是核心
-
以及一些预处理算法
Spark mllib
软实时机器学习:spark-streaming + Spark mlib
- Spark mlib支持的机器学习:
Spark拥有一套非常丰富的批处理机器学习算法,包括线性,树,支持向量机,用于分类和回归的神经网络模型,以及与推荐系统相关的显式和隐式交替最小二乘,more。然而,线性模型是Spark MLLib中唯一的流式算法,并且还正在研发有关在线推荐器和Latent Dirichlet Allocation原型, Spark还没有SAMOA连接器。 Spark有几个参数服务器的实现,其中大部分是批处理。我们提到了近期活跃的两个项目, Glint是基于参数服务器的Latent Dirichlet Allocation(第6.1节)实现,在[123]中描述。 Angel是一个通用参数服务器[126],具有逻辑回归,SVM(第3.2节),矩阵分解(第5.3节),潜在Dirichlet分配等实现。 Angel支持同步,异步和过时同步处理[125]。[出自参考6]

以及K均值,高斯混合(GMM),决策树,随机森林和梯度提升树等。
Spark2之前,流处理是无状态的,Spark2提出的Structured Streaming缓解了该问题:
一般在流处理的时候会比较关注有状态处理,但是仔细看的话批处理也是会受到影响的。比如常见的窗口聚合,如果批处理的数据时间段比窗口大,是可以不考虑状态的,用户逻辑经常会忽略这个问题。但是当批处理时间段变得比窗口小的时候,一个批的结果实际上依赖于以前处理过的批。这时,因为批处理引擎一般没有这个需求不会有很好的内置支持,维护状态就成为了用户需要解决的事情。比如窗口聚合的情况用户就要加一个中间结果表记住还没有完成的窗口的结果。这样当用户把批处理时间段变短的时候就会发现逻辑变复杂了。这是早期 Spark Streaming 用户 经常碰到的问题,直到 Structured Streaming 出来才得到缓解。[见参考11]
Storm
Storm做机器学习的资料,没怎么搜集到。
Storm做图计算的案例倒是有,Titan是一个分布式图形数据库,其背后的存储引擎可以使用HBase、Cassandra等。
FlinkML
Flink被寄予厚望,除其数据处理后的托管状态(managed state)以及仅一次交付(exactly-once)保证之外,还有很多优秀的设计。
managed state:
要理解托管状态,首先要从有状态处理说起。如果处理一个事件(或一条数据)的结果只跟事件本身的内容有关,称为无状态处理;反之结果还和之前处理过的事件有关,称为有状态处理。稍微复杂一点的数据处理,比如说基本的聚合,都是有状态处理。
FlinkML。除了https://github.com/apache/incubator-samoa/tree/master/samoa-flink上的SAMOA连接器之外,Flink还有一个真正的流参数服务器实现,网址为https://github.com/FlinkML/flink-parameter-server,包括Passive Aggressive分类器(第3.2节)和梯度下降矩阵分解(第5.3节)。最后,Flink可以通过在任何支持PMML标准的系统上训练的模型进行在线预测[102],使用https://github.com/FlinkML/flink-jpmml上的JPMML库。在Flink中,参数服务器在https://github.com/FlinkML/flink-parameter-server中作为数据流API的一部分实现。由于worker和服务器之间的通信是双向的,因此实现涉及流处理中的循环。如第2.1节所述,从概念上讲,一次性处理和容错在概念上是困难的,并且在撰写本文时,实现尚未完成[42]。
- FlinkML支持的机器学习:

SAMOA
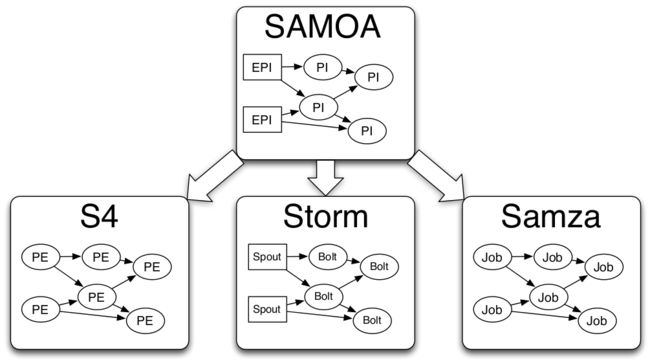
SAMOA
感觉像是没有被重视的一个项目(处于孵化状态),从github上看貌似没有什么进展,不知道什么时候能“毕业”。
-
Apache SAMOA是一种分布式流机器学习框架,用户无需直接处理底层分布式流处理引擎(DSPEe,如Apache Storm,Apache Flink和Apache Samza)的复杂性。Apache SAMOA用户可以只开发一次分布式流ML算法,然后在多个DSPE上执行。
-
SAMOA的主要目标是帮助开发人员在任何分布式流处理引擎上轻松创建机器学习算法。
其他,是否实时未知
Beam
Beam可以连接到深度学习框架Tensorflow(批量机器学习,非实时)
Apache SystemML
Apache SystemML 是一个优化大数据的机器学习平台,由 IBM 开发并开源。 它可以在 Apache Spark上运行,会自动缩放数据,逐行确定代码是否应在驱动程序或 Apache Spark 群集上运行。
目前正在开发GPU相关功能。
Apache SystemML 目前支持的机器学习算法有:
- 描述性统计 Descriptive Statistics
- 单变量统计 Univariate Statistics
- 双变量统计 Bivariate Statistics
- 分层双变量统计 Stratified Bivariate Statistics
- 多项 Logistic 回归 Multinomial Logistic Regression
- 支持向量机 Support Vector Machines
- 二进制类支持向量机 Binary-Class Support Vector Machines
- 多类支持向量机 Multi-Class Support Vector Machines
- 朴素贝叶斯 Naive Bayes
- 决策树 Decision Trees
- 随机森林 Random Forests
- K 均值聚类 K-Means Clustering
- 回归 Regression
- 线性回归 Linear Regression
- 逐步线性回归 Stepwise Linear Regression逐步线性回归 Stepwise Linear Regression逐步线性回归 Stepwise Linear Regression
- 广义线性模型 Generalized Linear Models
- 逐步广义线性回归 Stepwise Generalized Linear Regression
- 回归计分与预测 Regression Scoring and Prediction
- Kaplan-Meier 生存分析 Kaplan-Meier Survival Analysis
- Cox 比例风险回归模型 Cox Proportional Hazard Regression Model
- 主成分分析 Principal Component Analysis
- 通过交替最小化完成矩阵 Matrix Completion via Alternating Minimizations
MADlib
Apache MADlib是一个使用于可扩展数据库分析的综合库,为使用户提供了结构化和非结构化数据的机器学习,图形,数学和统计方法的并行实现。
PredictionIO

Apache PredictionIO是一个开源机器学习服务。它旨在帮助开发人员和数据科学家为机器学习任务创建预测引擎和服务。
基于Apache Spark,MLlib,HBase,Spray和Elasticsearch构建。
实时推荐系统
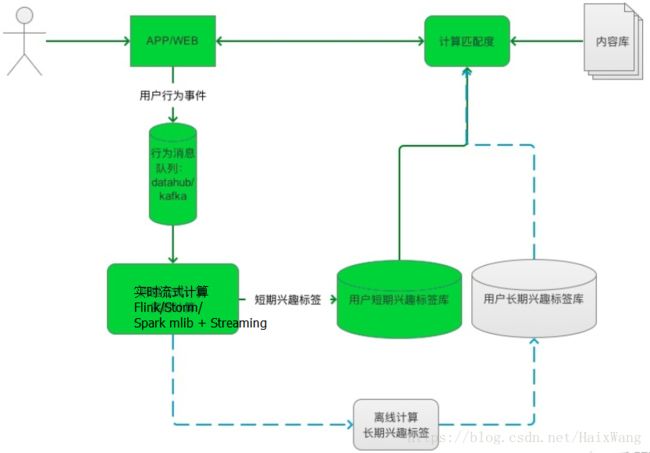
1.spark+kafka+redis
Spark中,推荐算法的实现只有交替最小二乘法ALS的实现版本。
以下内容(分割线以前)参考自CSDN:基于spark-streaming实时推荐系统(三):
未争取分享转载,侵删

上图主要是依托 spark+kafka+redis搭建实时在线推荐系统。矩形代表业务处理模块,竖条代表kafka,圆柱形代表redis。logSystem模块是日志采集系统实时传输数据写进kafka;reparation模块是日志清洗及根据用户进行hash,使相同的用户只会写到某一个paration中;statue模块可以根据系统设计需要,主要考虑到随着用户浏览时长等因素作为权重值所需,并进行hashParation保证每个分区数据分布均匀;bussines模块主要根据具体的业务逻辑计算用户对某一篇好的得分;rank模块在设计之初是与bussines模块合并的,但是在实际环境中运行时会出现系统堆积的现象,故单独拆开,主要是根据用户偏好得分并进行一定规则的过滤直接推荐,能够更加实时。
2.以下内容(分割线以前)参考自知乎用户:
未争取分享转载,侵删
一个简单的实时推荐系统大概分三部分:
1、标签系统
2、数据流处理系统
3、根据用户标签筛选出要推荐的内容
标签系统:
标签系统就是俗称的用户画像。
- 从属性变化性质来分,标签系统可分为静态标签和动态标签:
- 静态标签:短时间内变化不大的标签,比如性别、地域、职业、生活习惯等;
- 动态标签:不断变化的行为标签,比如关注的产品类别、产品偏好、内容偏好等
- 从更新时间的频率上来说,又可以分为短期兴趣标签和长期用户标签:
- 短期标签: 更新频率是分钟级或秒级;
- 长期标签: 更新频率是天级或小时级。
数据流处理系统(实时):
主要是绿色实线部分,针对系统推荐的内容。
用户有两种行为,点击或不点击,这个事件推送到流计算(其实是两个流,一个是点击流,一个是曝光流,这两个流根据用户id、内容id做join)。
3.Alibaba Clouder: real-time-personalized-recommendation-system
Spark Streaming + ElasticSearch + redis + HBase + Kafka

Spark Streaming预处理报告的曝光点击数据并将数据存储到ES。然后,ES提供要使用的BI报告的查询界面。
存储解决方案包括:
- Codis(用户推荐列表)
- HBase(用户个人资料和视频资料)
- Parquet(HDFS)(存档数据)
- ElasticSearch(HBase的副本)
参考
[1.] 《构建实时机器学习系统》彭河森,汪涵
[2.] 知乎:实时推荐系统如何做到实时
[3.] 过往记忆:Apache SystemML:为大数据优化的声明式机器学习平台
[4.] predictionio
[5.] arXiv:1703.03924v2 [cs.DC] 19 May 2017 – Real-Time Machine Learning: The Missing Pieces
[6.] Online Machine Learning in Big Data Streams
[7.] Samoa
[8.] What is online machine learning
[9.] CSDN:基于spark-streaming实时推荐系统(三)
[10.] YouTube:Real-Time Recommender Systems Made Easy with Neo4j — Pieter Cailliau, Neo4j
[11.] Spark比拼Flink:下一代大数据计算引擎之争,谁主沉浮?
《构建实时机器学习系统》(彭河森,汪涵)一1.5 实时机器学习的分类 ↩︎