[深度学习论文笔记][Object Detection] Fast R-CNN
1 R-CNN Problems
• Slow at test-time: need to run full forward pass of CNN for each region proposal.• Complex multistage training pipeline. Additional SVM and regressor need to be trained.
• SVMs and regressors are post-hoc: CNN features not updated in response to SVMs and regressors.
2 Pipeline
See Fig. The pipeline is as followings:
![[深度学习论文笔记][Object Detection] Fast R-CNN_第1张图片](http://img.e-com-net.com/image/info8/03d77475913344eda3959d1125c668fd.jpg)
2. Forward through conv5. Forward the whole image through CNN to get conv5 feature map.
3. RoI pooling. For each region proposal a region of interest (RoI) pooling layer extracts a fixed-size feature map from the conv5 feature map.
4. Classification and regresson. Each RoI feature map is fed into a sequence of fc layers that finally branch into two sibling output layers: one for classification and another one
for regression. NMS is then performed indepently for each class.
• It shares computation of convolutional layers between proposals for an image.
• The whole system is trained end-to-end all at once.
• No disk storage is required for feature caching.
3 RoI Pooling
Suppose conv5 feature map has size D l−1 × H l−1 × W l−1 . We project the region proposal (with sizes F H × F W ) onto conv5 feature map. The fc layers expect fixed size feature map: D l × H l × W l .
The RoI pooling is computed by dividing the projected region proposal into H l × W l grid, and then doing max pooling with each grid cell. RoI pooling can be back propagated
similar to standard max pooling.
4 Smooth l 1 Loss
We use a smooth l 1 loss for bounding box regression.
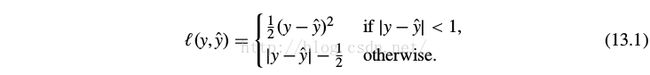
It is less sensitive to outliers than the l 2 loss used in R-CNN. When the regression targets are unbounded, training with l 2 loss can require careful tuning of learning rates in order to prevent exploding gradients.
5 Training Details
During fine-tuning, we sample 64 RoIs from each image. we take 25% of the RoIs from object proposals that have IoU overlap with a ground-truth bounding box of at least 0.5.
These RoIs comprise the examples labeled with a foreground object class. The remaining RoIs are sampled from object proposals that have a maximum IoU with ground truth in the interval [0.1, 0.5). These are the background examples. The lower threshold of 0.1 appears to act as a heuristic for hard example mining. During training, images are horizontally flipped with probability 0.5. No other data augmentation is used.
6 Results
See Tab. VGG-16 CNN is used on VOC-07 dataset.
![[深度学习论文笔记][Object Detection] Fast R-CNN_第2张图片](http://img.e-com-net.com/image/info8/c0cbf7ccfada416890a64e985adddd07.jpg)
Multi-task training improves pure classification accuracy relative to training for classification alone. The improvement ranges from +0.8 to +1.1 mAP points.