Pytorch AutoEncoder 自编码 全部源代码复现
PyTorch 自编码的实现:
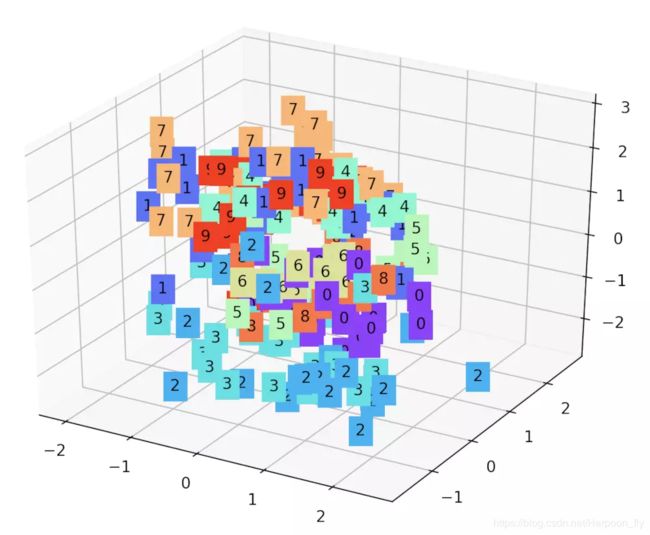
下面是显示效果,感觉还是可以的,最起码该出现的都出现了!

import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
from torch.autograd import Variable
import numpy as np
# 超参数定义
Epoch = 10
Batch_size = 100
LR = 0.005
Downloads_MNIST = False
N_Test_img = 5 # 测试图片的显示效果,5张为一批
train_data = torchvision.datasets.MNIST(
root=r'./mnist_data/',
train=True,
transform=torchvision.transforms.ToTensor(),
download=Downloads_MNIST
)
print(train_data.train_data.size())
train_loader = Data.DataLoader(dataset=train_data, batch_size=Batch_size, shuffle=True)
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
# 定义编码网络
self.encoder = nn.Sequential(
nn.Linear(28 * 28, 128),
nn.Tanh(),
nn.Linear(128, 64),
nn.Tanh(),
nn.Linear(64, 12),
nn.Tanh(),
nn.Linear(12, 3)
# 压缩成3个特征进行3D图像可视化
)
# 定义解码网络
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.Tanh(),
nn.Linear(12, 64),
nn.Tanh(),
nn.Linear(64, 128),
nn.Tanh(),
nn.Linear(128, 28 * 28),
nn.Sigmoid()
)
def forward(self, x):
encoder = self.encoder(x)
decoder = self.decoder(encoder)
return encoder, decoder
if __name__ == '__main__':
autoencoder = AutoEncoder()
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=LR)
loss_func = nn.MSELoss()
# 初始化图像
f, a = plt.subplots(2, N_Test_img, figsize=(5, 2))
plt.ion()
view_data = Variable(train_data.train_data[:N_Test_img].view(-1, 28 * 28).type(torch.FloatTensor) / 255.)
for i in range(N_Test_img):
a[0][i].imshow(np.reshape(view_data.data.numpy()[i], (28, 28)), cmap='gray')
a[0][i].set_xticks(())
a[0][i].set_yticks(())
for epoch in range(Epoch):
for step, (x, b_label) in enumerate(train_loader):
b_x = x.view(-1, 28 * 28)
b_y = x.view(-1, 28 * 28)
encoder_out, decoder_out = autoencoder(b_x)
loss = loss_func(decoder_out, b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 100 == 0:
print('Epoch:{}, Train_loss:{:.4f}'.format(epoch, loss.item()))
_, decoder_data = autoencoder(view_data)
for i in range(N_Test_img):
a[1][i].clear()
a[1][i].imshow(np.reshape(decoder_data.data.numpy()[i], (28, 28)), cmap='gray')
a[1][i].set_xticks(())
a[1][i].set_yticks(())
plt.draw()
plt.pause(0.08)
plt.ioff()
plt.show()
view_data = train_data.train_data[:200].view(-1, 28 * 28).type(torch.FloatTensor) / 255.
encoder_data, _ = autoencoder(view_data)
fig = plt.figure(2)
ax = Axes3D(fig) #这个3D画图
X = encoder_data.data[:, 0].numpy()
Y = encoder_data.data[:, 1].numpy()
Z = encoder_data.data[:, 2].numpy()
values = train_data.train_labels[:200].numpy()
for x, y, z, s in zip(X, Y, Z, values):
c = cm.rainbow(int(255 * s / 9))
ax.text(x, y, z, s, backgroundcolor=c)
ax.set_xlim(X.min(), X.max())
ax.set_xlim(Y.min(), Y.max())
ax.set_xlim(Z.min(), Z.max())
plt.show()
这个3D画图出来的效果