爬取应用宝首页、应用分类、应用以及应用详情
工具:python3.6、pycharm社区版、anaconda(为什么会有anaconda,因为我pycharm的库路径设置的anaconda库(怠惰))、firefox56.02(没用最新版是因为新版不兼容Http Requester)
下载地址:
pycharm:https://www.jetbrains.com/pycharm/download/#section=windows
anaconda:https://www.anaconda.com/download/
firefox:https://support.mozilla.org/zh-CN/products/firefox/install-and-update-firefox
环境配置就不赘述了
pip安装教程:https://jingyan.baidu.com/article/b907e627a072a846e6891c5a.html
scrapy框架安装教程:https://cuiqingcai.com/912.html
文档:https://doc.scrapy.org/en/latest/
pycharm使用anaconda库:http://blog.csdn.net/xiu_star/article/details/52277623
firebug教程:https://jingyan.baidu.com/article/fd8044fa97e08c5030137a6c.html
http://www.runoob.com/firebug/firebug-tutorial.html
xpath教程:http://www.w3school.com.cn/xpath/
准备完毕后
打开pycharm,新建一个project(Create New Project)
选择Pure Python
命名随意,我的已经建好了,命名是My_app
建好project以后,进入Terminal,输入scrapy startproject My_app
按enter执行命令

My_app也只是个文件名,可以取自己想要的名字
执行完毕后应该会这样
右键点击spiders,新建一个python文件,取名还是随意
建好以后开始在这个文件下写代码
我的文件比较多,因为之前分别爬了首页跟应用分类还有应用
爬取首页代码

爬取应用分类代码
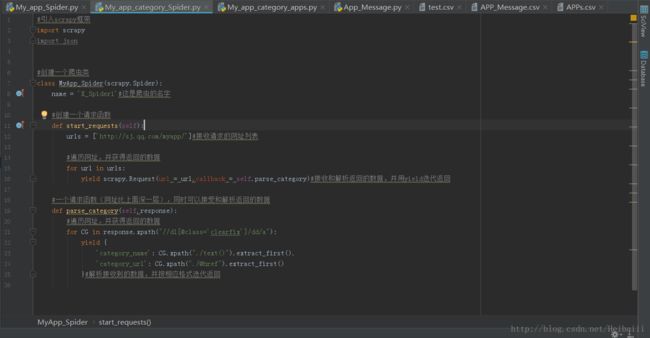
爬取应用代码

其实都差不多,就是一层层深入而已
最重要的是应用详情的爬取,里面有一些比较有意思的问题,比如相同类,相同标签里不同数据的爬取
比如爬取这种类型的数据
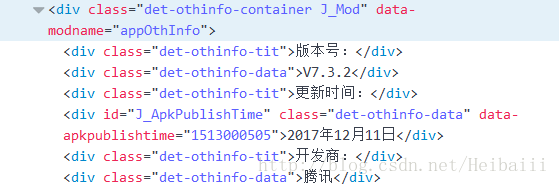
这里版本号数据与开发商数据的类名跟标签名是相同的,且在同一分层里,这就需要用到循环
下面是我爬取应用详情的代码
代码如下
#引入scrapy框架
import scrapy
#创建一个爬虫类
class Myapp_Spider(scrapy.Spider):
name = 'X_Spider3'#爬虫命名,每个爬虫的名字必须是唯一的
#首页
#创建一个请求函数
def start_requests(self):
urls = ['http://sj.qq.com/myapp/']
for url in urls:
yield scrapy.Request(url = url,callback=self.parse_category)
#应用分类
#创建一个请求函数(网址比上面深一层)同时可以接受和解析返回的数据
def parse_category(self,response):
#遍历网址,并获得返回的数据
for cg_url in response.xpath("//dl[@class='clearfix']/dd/a/@href"):#用@href获取指定超链接的url
cg_url = response.urljoin(cg_url.extract())#用urljoin()函数拼接出完整网址
yield scrapy.Request(url = cg_url,callback=self.parse_apps)#接收和解析返回的数据,并用yield迭代返回
#应用
#创建一个请求函数(网址比上面深一层)同时可以接受和解析返回的数据
def parse_apps(self,response):
#遍历网址,并获得返回的数据
for app in response.xpath("//ul[@class='app-list clearfix']/li/div/div/a[@class='name ofh']/@href"):#加条件[@class='name ofh']过滤掉无用数据
app = response.urljoin(app.extract())
yield scrapy.Request(url = app,callback=self.parse_app_message)
#应用信息
##创建一个请求函数(网址比上面深一层)同时可以接受和解析返回的数据
def parse_app_message(self,response):
iden = []#用来存储遍历出来的数据
#因为是两个相同类相同标签的不同数据,所以需要遍历一下
for identical in response.xpath("//div[@class='det-othinfo-data']/text()").extract():#这里用extract()提取有用数据
iden.append(identical)
#因为每个页面只展示一个应用的应用信息,所以不需要遍历
yield {
'Title': response.xpath("//div[@class='det-name-int']/text()").extract_first(),
'Amount of Downloads': response.xpath("//div[@class='det-ins-num']/text()").extract_first(),
'Score': response.xpath("//div[@class='com-blue-star-num']/text()").extract_first(),
'Version': iden[0],
'Developers': iden[1],
#'Version': response.xpath("//div[@class='det-othinfo-data']/text()").extract_first(),
#'Developers': response.xpath("//div[@class='det-othinfo-data']/text()").extract_first(),
'Information': response.xpath("//div[@class='det-app-data-info']/text()").extract_first()
}代码完成以后 在Terminal下将目录转移至spiders文件的目录下,如果不转移至spiders文件下,crawl将无法执行

根据我的文件夹,我应该输入:
cd My_app\My_app\spiders
执行这条命令后,输入:
scrapy crawl X_Spider3
启用爬虫
X_Spider3 是我的爬取应用详情的爬虫的名字,请根据你在爬虫类下定义的name输入你的爬虫的名字
若要将爬取的数据存入文件,可输入如下命令:
scrapy crawl X_Spider3 -o filename.csv
csv是因为我比较喜欢用csv格式存储,-o下可用的存储格式有这些:
‘json’, ‘jsonlines’, ‘jl’, ‘csv’, ‘xml’, ‘marshal’, ‘pickle’
其中一些格式会将中文字符转换成unicode编码(比如json..),但是这没什么关系
存入文件后是这样的
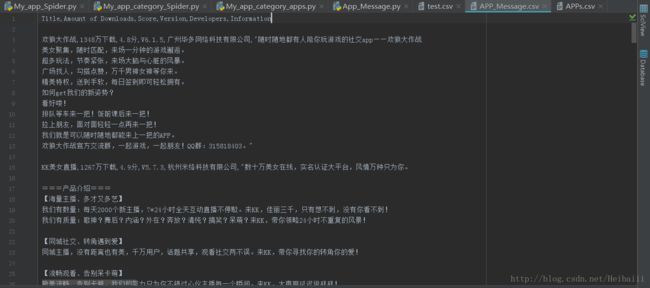
最上方的英文是我设置的标签,对应下面的各种内容(‘’tilte == 应用名 ‘’这样)
不要问我为什么开始抓到的都是什么美女直播之类的..我也不知道..随机抓的,以前不是这样的…(相信我!)
当然,也可以将这些数据存入数据库,我懒得写了,就不写了
我用的数据库是postgreSQL,操作工具是DBeaver
下面贴上我看的教程:爬虫神功
昨天起来到现在还没睡,睡觉睡觉,溜了溜了
