极简笔记 Instance Segmentation Survey
极简笔记 Instance Segmentation Survey
本篇包含多篇实例分割论文笔记,因为大多都是较为早远的论文,因此每篇笔记奉行极简原则,在叙述大意的同时,尽量缩短篇幅。
Instance-aware Semantic Segmentation via Multi-task Network Cascades (MNC)
Jifeng Dai, Kaiming He较早的实例分割文章,思路也非常简单,就是把实例分割分为三步骤:1. 实例检测;2. 单目标分割;3. 分类。实现过程如图,第一步RPN得到bbox,第二步利用共享特征和bbox进行mask计算,第三步利用共享特征、bbox、mask进行分类(非逐像素)。

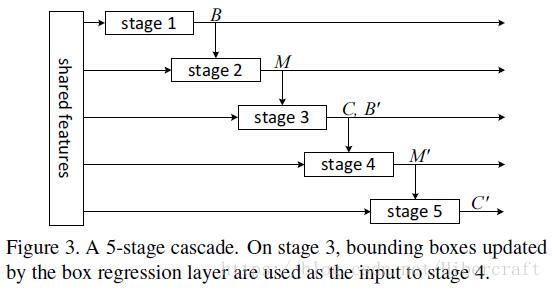
文章另外还尝试了cascade的形式,即在第一次三步预测完成的基础上进行第二次三步预测对之前的结果进行refine,有一定效果但速度较慢。
Instance-sensitive Fully Convolutional Networks
Jifeng Dai, Kaiming He的有一篇实例分割文章。文章提出实例位置敏感得分图,即一个channel表示当前像素点属于某个实例的某个部分的得分。如图所示可见它与传统FCN只出一个mask的区别。得到位置敏感得分之后利用采样固定大小窗口的方式将这些位置敏感channel集成在一起,比如当前窗口左上角的patch从对应左上角位置的channel复制过来,右上角patch从对应右上角位置的channel复制过来。通过这样的复制操作得到最终的单实例mask。

网络结构分为两支,第一支如上述得到实例mask,第二支则从前面的feature出发,在每一个采样窗口(sliding window方法进行采样)位置预测该窗口的物体/非物体得分,最后利用NMS(threshold>0.8)得到物体得分最高的几个窗口,并将窗口对应的mask作为最终结果。

Fully Convolutional Instance-aware Semantic Segmentation (FCIS)
此篇是Jifeng Dai组对之前InstanceFCN的改进,COCO2016实例分割冠军。引入RPN先提取bbox,同时计算全图的position-sensitive score,然后利用提取的proposal在相应位置进行assemble,之后预测区分类别的mask和类别判断。网络结构如下图:

Proposal-free Network for Instance-level Object Segmentation
同样是问题分解的方式,但这篇文章把问题分解成了:1.逐像素语义分割;2.逐像素对应实例的bbox坐标预测;3.区分类别的实例个数预测。先是用VGG进行语义分割,然后取VGG的一些不同尺度的feature map,和channel=2的表示每个像素坐标值(x,y)的feature map concatenate,各自卷积之后缩放到相同尺度再次concatenate,用于预测每个像素对应的实例的bbox坐标。再将坐标预测feature map和之前的VGG特征concatenate预测区分类别的实例个数。网络细节见下图:

在test阶段,针对语义分割得到的同类别的像素,根据预测的逐像素bbox坐标进行聚类,聚类个数由预测的实例个数决定。
Learning to Segment Object Candidates (DeepMask)
这篇做的工作主要是给一个patch,然后对patch进行类别无关的分割,同时判断该patch中的对象是否centered(要满足两个条件:1. patch包含了一个对象大致在中心位置;2.patch中对象占有的像素个数不超过一个限制)。网络也非常简单,VGG之后两个任务的分支(见下图):

在全图推断上,文章用了多尺度sliding window的方法进行密集预测(多尺度通过修改输入图像的尺度实现,window大小并没有改变),然后将密集取到的patch输入网络计算。文章最后也没有讲用NMS(全文搜索搜不到),但是大概还是要对object score map进行NMS操作之后取对应mask得到结果吧。

Learning to Refine Object Segments (SharpMask)
此篇是之前DeepMask的改进,其实改进的内容很小,只是在预测mask的时候采用encoder-decoder结构,同时引入多尺度的mask loss,从而对细节进行更好的还原。

训练时候文章采用分步训练,先用最高层的mask loss来训练骨架网络,然后再训练refine model部分。作者还把得到的mask作为proposal用于目标检测(这个流程思路和我的想法很相近),发现效果比RPN好

FastMask: Segment Multi-scale Object Candidates in One Shot
本文也是针对DeepMask的改进。把DeepMask对原图的多尺度和sliding window挪到了网络深层。网络主要分为三个部分:body,neck,head。body就是骨架网络,之后利用neck结构对feature map进行多尺度变化产生特征金字塔。在特征金字塔的结果上进行sliding window提取proposal,再对每个proposal预测mask和confidence score(是否为物体且占据中心)

neck部分参考了residual block的结构,文章还另外尝试了avg/max pooling非参数方法和简单的卷积方式,发现还是residual最好。

window部分采用了attention机制,需要预测一个attention map(这部分attention需要根据ground truth算loss),之后再预测mask和confidence score

此外,由于DeepMask的图像金字塔尺度变化更加紧密,而这里在特征层面构建金字塔始终以2为gap,相比之下更加稀疏,因此文章也提出时候two-stream的结构,在body net之后在不同比率下采样的特征上建立以2为倍数的特征金字塔,从而使得尺度变化更加密集。

Associative Embedding: End-to-End Learning for Joint Detection and Grouping
这篇文章针对的问题是多目标姿态估计和实例分割,文章采用的骨架网络是stacked-hourglass,主要思路是先做逐像素分类(关键点分类/语义分割),然后做聚类。聚类步骤对每一个类别预测一个pixel-wise id表示当前像素所属实例的编号。聚类的loss目标使得同一实例的标注更加相近,不同实例的标注更远(编号没有gt)。在测试阶段,对预测编号进行直方图统计并做NMS之后确定实例个数,再进行聚类。

细讲一下grouping loss,记gt中第n个实例的第k个关键点坐标为 xnk x n k , h(x) h ( x ) 表示 x x 像素预测的实例id,首先计算第n个实例各个关键点对应的实例id均值:
然后计算groupling loss( T={(xnk)} T = { ( x n k ) } 表示所有gt的关键点位置集合):
对于Instance segmentation,文章没有做semantic segmentation,而是把所有mask union作为gt。在计算grouping loss的时候也不是对所有像素进行计算,而是每个instance采样出一些像素集合 Sn S n 来计算loss:
这个基于聚类的方法在multi-pose estimation中效果不错,超过了OpenPose,但是在Instance Segmentation中的效果远低于MNC,可能就是因为相比于pose estimation,Instance segmentation没有做分类。

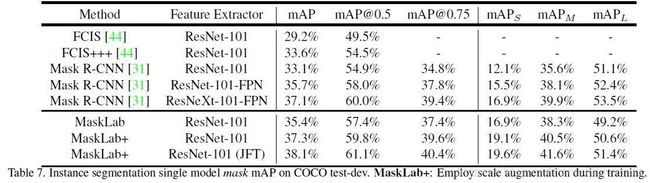
MaskLab: Instance Segmentation by Refining Object Detection with Semantic and Direction Features
本篇文章是之前广泛工作的集成,网络分为三个部分:RPN提取proposal,全局semantic segmentation mask预测以及direction预测(其实direction就是position-sensitive score map,然后根据不同位置复制集成到一起)。网络结构图如下:

direction prediction流程见下图:

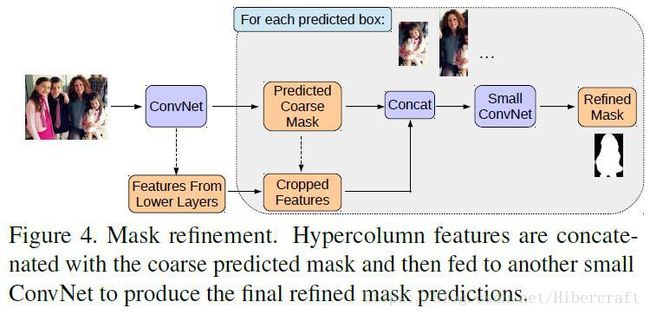
在得到instance mask之后,文章采用refine方法,把course mask和浅层feature map concatenate进行再一次refine
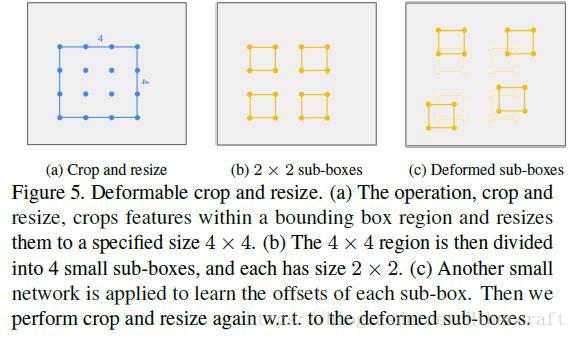
文章同样参考了deformable conv net,在detection的时候进行类似deformable pooling操作,即将proposal分为四个小块,同时用一个额外的小网络预测offset,将偏移的小块进行集合做检测。
最后放一个性能对比(现在好像还是PANet最强)