极简笔记 segmentation + transfer learning survey第二弹
极简笔记 segmentation + transfer learning survey第二弹
@(academic)[极简笔记]
Deep Extreme Cut: From Extreme Points to Object Segmentation
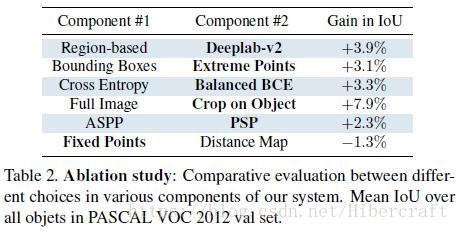
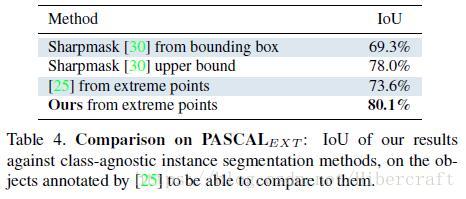
本文的思路非常简单,标注分割对象的极点(最上方点,最下,最左,最右),生成4 channel的极点位置高斯响应图,与输入图片concatenate之后送入网络学习。实验发现这样的学习方式比利用bbox+50px margin进行cut出来继续分割的效果好。
Residual Parameter Transfer for Deep Domain Adaptation
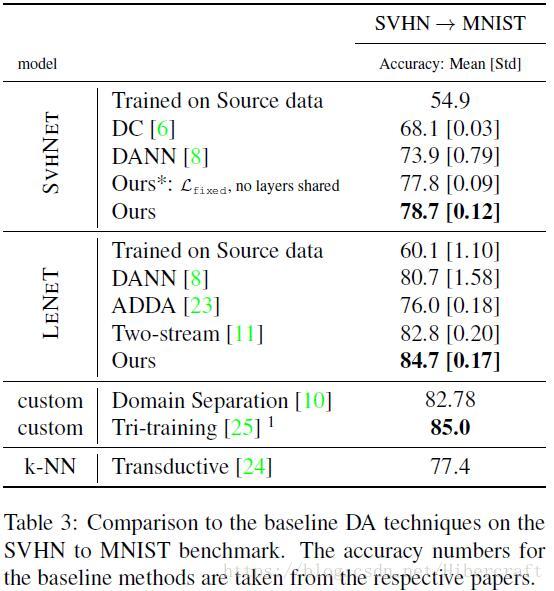
本篇文章的工作是为了做domain adaption,即在一个库上训练,换一个只有少量标注的数据集,保证识别率。

网络架构如上图,采用two-stream结构,分别用于source domain和target domain数据特征的提取,target domain网络的参数由source domain对应层经过一个residual block的结构(identity map+autoencoder)学得。训练过程中包括三部分loss:1.分类loss,包括source domain分类误差和少部分target domain的分类误差;2. Discrepancy Loss,目标是使得两个网络输出的特征尽量一致。利用一个预训练分类器和对抗误差实现这个效果;3. 正则化误差,因为target domain标注极小,residual-block参数过多会导致严重过拟合,因此在residual-block采用多种正则化方法减少参数量。
文章提到pseudo-label(用source domain网络预测target domain结果之后做监督学习)非常有效,是未来的方向。
Large Scale Fine-Grained Categorization and Domain-Specific Transfer Learning
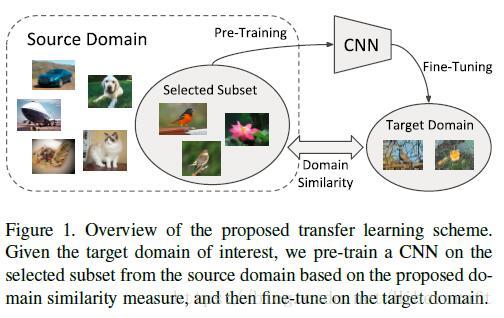
本篇文章研究的问题是细粒度分类,主要有两个贡献:1. 利用二阶段训练方法解决分类问题long-tailed数据分布问题;2. 利用Earth Mover’s Distance(EMD)来度量source domain(粗粒度分类)中的类别与target domain(细粒度分类)中类别的相似度。利用贪心的方式选取与target domain类别最相关的source domain类别集合进行预训练,之后再在target domain上进行fine-tuning。
long-tailed分布问题是因为自然界中总是有一些物体出现次数少,这类物体在训练集中出现次数也很少,这就会导致训练不平衡的问题。文章提出二阶段法,第一阶段正常训练,第二阶段选取那些出现次数少的样本做一个训练集,用较小学习率进行fine-tuning,能取得效果提升。文章还提到提高输入图像resolution也能提高性能。
在迁移学习方面,文章的研究思路是pretrain粗粒度网络(数据量大),之后迁移到细粒度训练集进行fine-tuning。记source domain样本 s∈S s ∈ S ,target domain样本 t∈T t ∈ T ,样本特征间的欧氏距离 d(s,t)=||g(s)−g(t)|| d ( s , t ) = | | g ( s ) − g ( t ) | | ,其中 g(∙) g ( ∙ ) 表示在JFT数据集上训练的特征抽取器。两个域之间的EMD距离记作
其中 g(si) g ( s i ) 表示source domain中类别 i i 所有样本特征的均值, g(ti) g ( t i ) 也一样。 fi,j f i , j 是通过最优化EMD解出来的最优流,最后域相似度定义成:
Multi-Evidence Filtering and Fusion for Multi-Label Classification, Object Detection and Semantic Segmentation Based on Weakly Supervised Learning
该篇文章感觉贡献不大(这居然都能中CVPR2018,只能说审稿人质量下降严重),主要就是提出一个pipeline,连weakly supervised方法都不是自己提出的。
流程主要分为四个步骤:
1. 在image level,用了别人weakly supervised网络生成object heatmap,把另外的分类网络的feature map认作attention heatmap,把object heatmap与attention heatmap融合,用类似RPN的方法提取超量的proposal。
2. 在instance level,用triplet loss训练一个网络做proposal feature embedding,然后用density based clustering对proposal进行聚类,筛除一些outlier。另外还训练一个instance 类别分类器,如果分类的结果和标注不一样也作为outlier删掉。
3. 在像素级别上,把全图的attention map和实例级别的attention map进行融合作为最终attention map,和之前detection heatmap相乘并归一化,同时又融合了一篇自引文章的silence detection heatmap,加了个分割网络得到结果。
文章用的网络基本都是VGG或者GoogLeNet-v1/2,显然比较out-of-date。在众多的特征融合过程中出现大量阈值,调参痕迹明显。
