【Java后端同学入门Spark编程】RDD基本操作
最近由于工作任务,需要掌握大数据技术栈的相关知识,于是开始了入门大数据的漫漫之路。
相比传统Java后端的技术栈来说,大数据关注的技术点可以说是另一套内容,但同时本质上又殊途同归,Hadoop是用Java实现的,Spark虽然是用Scala实现,但Scala本身也是跑在JVM上,所以对于Java同学还是有一定的友好度的。
相对于技术部分,个人觉得更多的不同点在于业务的设计部分,这一部分才是真的处于零基础入门阶段,对于数据分析模型的建立,还是和建立业务模型有区别的,这一部分只能逐渐摸索前进了。
在这里把我的学习之路做一个总结,希望对Java后端,同时想了解大数据的同学有些帮助。
【一】环境
由于时间紧任务重,对于环境搭建这种耗时,又容易踩坑的事情还是要尽量避免,这一阶段的目标是能写出代码,毕竟还要同时入门Scala,所以其他步骤我选择尽量简化,我选取了Docker镜像的方式来部署环境,这个时候才觉得,Docker就是懒人福音呐~
这是一个在镜像仓库找到的可用的镜像,拉取下来就可以直接实验了~
镜像地址:hub.c.163.com/liweigu/spark
拉取镜像,创建容器之后,执行"docker exec -it spark /bin/sh"进入容器
启动文件在 /soft/spark-2.1.1-bin-hadoop2.7/bin
【二】基本概念
【1】RDD、DAG
简介
它是Spark编程的核心,Spark API 的所有操作都是基于 RDD 的,你要牢牢记住它,这将是你在coding过程中一直打交道的兄弟。
RDD较为官方的解释,是弹性分布式数据集,分布式对象集合,本质上提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,如果想要修改,只能创建新的RDD。
这样设计的目的:减少网络及磁盘 IO 开销
DAG则是反应各个RDD间的依赖关系
RDD特性
- 容错性 - 血缘关系:血缘关系、重新计算丢失分区、无需回滚系统、重
算过程在不同节点之间并行、只记录粗粒度的操作 - 避免磁盘读写:中间结果持久化到内存
- 避免序列化和反序列化:可存放Java对象
一次典型的RDD执行过程
- RDD读入外部数据源进行创建
- RDD经过一系列的转换(Transformation)操作,每一次都会产生不同的
RDD,供给下一个转换操作使用 - 最后一个RDD经过“动作”操作进行转换,并输出到外部数据源,这一系列处理称为一个Lineage(血缘关系),即DAG拓扑排序的结果
RDD总结
- 由一系列partition组成,partition分布在不同的节点上
- 存在一系列的依赖关系
- 函数是作用在每一个partition(split)上的
- 分区器是作用在K,V格式的RDD上
- 提供一系列最佳的计算位置
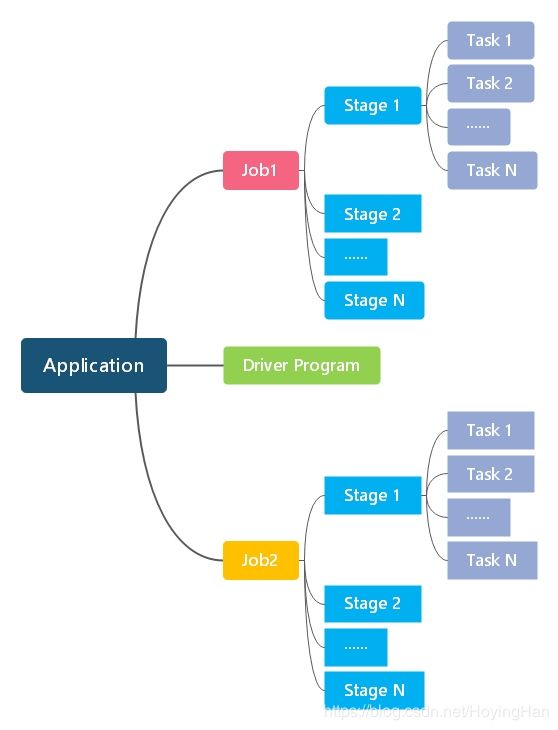
【2】Job、Stage、Task
Job是多个RDD和应用在RDD上的各种操作。
Stage是Job的基本调度单位,通过Shuffle划分。
Task是实际执行的最小单元,一个Task对应一个线程。
三者关系
一个Job对应多个Stage,每个Stage是一组Task,这一组Task是一组存在关联,但相互间没有Shuffle依赖关系的组合。
【三】基本操作
这部分是最终要落在代码上的知识,毕竟作为一门实践学科,还是先用起来比较重要。操作分为四种类型,分别是创建,转换,控制和行动操作。这里分别介绍几个较为常用的算子。
【1】创建
-
并行化集合创建
val distData = sc.parallelize(Array(1,2,3,4)) -
外部存储创建:Spark支持将Hadoop支持的资源转化成RDD。
【2】转换
转换操作是延迟执行的
-
对单条Record的转换操作
-
filter(func):
sc.parallelize(Array(1,2,3,4)).filter(_> 1).collect() res1: Array[Int] = Array(2, 3, 4) -
map(func):每个元素执行func,输入:输出=1:1
sc.parallelize(Array(1,2,3,4)).map(x=>x+1).collect() res2: Array[Int] = Array(2, 3, 4, 5) -
flatMap(func):与map()相似,但输入:输出=1:N
sc.parallelize(Array(1,2,3,4)).flatMap(x=> Array(x+1,x+10)).collect() res5: Array[Int] = Array(2, 11, 3, 12, 4, 13, 5, 14)
-
-
对分区shuffle的转换操作
-
reduceByKey():按key聚合,返回新的(K, Iterable)
sc.parallelize(Array( "a" -> 1,"a" ->2,"a" ->3, "b" -> 4)).reduceByKey((x,y)=> x+y).collect() res1: Array[(String, Int)] = Array((a,6), (b,4)) -
groupByKey():针对(K, V)类型,返回(K, Iterable)类型的数据集
sc.parallelize(Array( "a" -> 1,"a" ->2, "b" -> 3)) res2: Array[(String, Iterable[Int])] = Array((a,CompactBuffer(1, 2)), (b,CompactBuffer(3))) -
join:针对(K,V)类型,连接的依据是Key值
-
union:两个RDD合并
-
mapPartitions()
sc.parallelize(Array(1,2,3,4)).mapPartitions(x=> x.map(_+1)).collect() res1: Array[Int] = Array(2, 3, 4, 5)
-
【3】控制
控制操作也可以理解为持久化,这主要是为了避免多次计算同一个RDD,默认情况下会把数据以序列化的形式缓存在JVM 的堆空间,主要包括下面三个方法。
- cache()
- persist()
- checkpoint()
【4】 行动
- count():返回元素个数
- take(n):前n个元素,以数组形式返回
- first():返回第一个元素
- foreach(func):集合中每个元素执行func
- collect():拉取rdd中所有数据到driver节点,转换成一个数组,如果数据量过大,会造成driver的OOM
【四】Spark SQL
Spark SQL的定位是处理结构化数据的Spark组件,所以增加了SchemaRDD,数据既可以来自RDD,也可以是Hive、HDFS、Cassandra等外部数据源,还可以是JSON格式的数据。
所谓的结构化数据,在Spark中被称为DataFrame,相比于RDD,有如下的优势:
- 精简代码
- 提升执行效率 - 重用对象
- 减少数据读取
从常规RDD,转化为DataFrame,有如下两种方式,一般情况下,我们采用第二种方式创建。
- Case Class方式: 利用反射推断Schema
- createDataFrame方式:
- 从源RDD创建rowRDD
- 创建于源RDD匹配的Schema
- 通过createDataFrame应用到rowRDD
在业务开发的过程中,使用Spark SQL的确可以降低开发难度,采用类似SQL语句的形式对数据进行处理,也可以继续使用RDD转换算子,对结果进行进一步处理。