GoLang—爬虫—数据清洗(goquery)
当我们成功向网站发送HTTP请求的时候,网站会给回我们响应的网页内容。网页内容以HTML代码形式表示,因此我们需要从HTML代码中提取目标数据。
数据清洗方式大致分为三种:字符串操作(截取,替换等操作)、正则表达式和HTML解析。字符串操作和正则表达式就不再详细讲述,这属于GoLang的基础语法,本文重点讲述GoLang的HTML解析。
GoLang常用的HTML解析有第三包goquery,在CMD窗口输入安装指令即可。
go get github.com/PuerkitoBio/goquery
goquery定义多种方法从HTML里获取目标数据,本文只讲述最常用的数据清洗提取方法,其他的数据清洗提取方法可以参考官方文档
我们将上一节的响应内容作为源数据,详情参考:GoLang—爬虫入门基础—模拟发送HTTP请求。为了区分上一节的内容,我们将模拟发送HTTP请求改为函数SendHttp发送,数据清洗写在main函数,整段代码如下所示。
package main
import (
"fmt"
"github.com/PuerkitoBio/goquery"
"github.com/axgle/mahonia"
"io/ioutil"
"net/http"
"net/url"
"strings"
"time"
)
//使用第三方mahonia实现网页内容的转码
func ConvertToString(src string, srcCode string, tagCode string) string {
srcCoder := mahonia.NewDecoder(srcCode)
srcResult := srcCoder.ConvertString(src)
tagCoder := mahonia.NewDecoder(tagCode)
_, cdata, _ := tagCoder.Translate([]byte(srcResult), true)
result := string(cdata)
return result
}
// 使用映射传递函数参数,requestMode作为HTTP的请求方式
func SendHttp(urls string, method string, rawurl string, cookie []http.Cookie)string{
req, _ := http.NewRequest(method ,urls, nil)
//为请求对象NewRequest设置请求头
req.Header.Add("Content-Type", "application/x-www-form-urlencoded")
req.Header.Add("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36")
//设置Cookies信息
if cookie != nil {
for _, v := range cookie{
req.AddCookie(&v)
}
}
//设置代理IP,代理IP必须以为fun形式表示
client := &http.Client{}
if rawurl != "" {
proxy := func(_ *http.Request) (*url.URL, error) {
return url.Parse(rawurl)
}
transport := &http.Transport{Proxy: proxy}
//在Client对象设置参数Transport即可实现代理IP
client.Transport = transport
}
//执行HTTP请求
resp, _ := client.Do(req)
//读取响应内容
body, _ := ioutil.ReadAll(resp.Body)
//将响应内容转换utf-8编码
result := ConvertToString(string(body), "gbk", "utf-8")
//输出网页内容
return result
//输出响应内容的Cookies信息
//for _, v := range resp.Cookies() {
// fmt.Println(v)
//}
}
func main() {
urls := "https://search.51job.com/list/030200,000000,0000,00,9,99,python,2,1.html"
method := "GET"
//rawurl := "http://111.231.93.66:8888"
rawurl := ""
var cookie []http.Cookie
c := http.Cookie{Name: "clientcookieid", Value: "121", Expires: time.Now().Add(111 * time.Second)}
cookie = append(cookie, c)
result := SendHttp(urls, method, rawurl, cookie)
fmt.Println(result)
// 使用第三包goquery读取HTML代码,读取方式有多种,如下所示:
// NewDocumentFromReader:读取字符串的HTML代码
// NewDocumentFromResponse:读取HTML代码对象,即net/http生成的响应内容resp.Body
// NewDocument:从网址中直接读取HTML代码
dom, _ := goquery.NewDocumentFromReader(strings.NewReader(result))
// Find函数是查找HTML里面所有符合要求的标签。
// 如果查找Class="t1"的标签,则Find(".t1");如果查找id="t1"的标签,则Find("#t1")
// 如果有多个标签使用同一个Class,比如div和p标签使用Class="t1",若只需定义div标签,可以使用Find("div[class=t1]")
dom.Find(".t1 ").Each(func(i int, selection *goquery.Selection) {
fmt.Println(strings.TrimSpace(selection.Text()))
})
// 通过多层HTML标签查找,只需在Find里面设置多层标签的Class属性即可
// 首先查找Class="el"的标签,然后在Class="el"的标签里查找Class="t2"的标签
// 再从Class="t2"的标签查找标签a,因此查找方式为Find(".el .t2 a"),每个标签之间使用空格隔开
dom.Find(".el .t2 a").Each(func(i int, selection *goquery.Selection) {
// 获取数据
fmt.Println(strings.TrimSpace(selection.Text()))
// 获取数据所在HTML代码
fmt.Println(selection.Html())
// 使用Attr获取数据所在HTML代码的href属性
v, _ := selection.Attr("href")
fmt.Println(v)
// 使用AttrOr获取数据所在HTML代码的href属性
fmt.Println(selection.AttrOr("href", ""))
})
}
在main函数中,调用函数SendHttp,函数的返回值为result,这是网页的HTML代码,并以字符串的形式表示。然后使用goquery.NewDocumentFromReader解析网页的HTML代码,生成dom对象。最后由dom对象调用Find函数实现目标数据的定位。Find函数调用Each函数可以将符合条件的标签进行遍历,整个使用方式如下
dom.Find(".t1 ").Each(func(i int, selection *goquery.Selection) {
fmt.Println(strings.TrimSpace(selection.Text()))
})
其中函数参数func(i int, selection *goquery.Selection是固定的,参数i是当前遍历的次数,参数selection是定位后的目标数据,然后由selection对象调用Text、Html、Attr或AttrOr可以获取目前数据的文本内容、HTML标签和标签属性。(selection对象还可以使用Find函数实现下一级的标签查找)
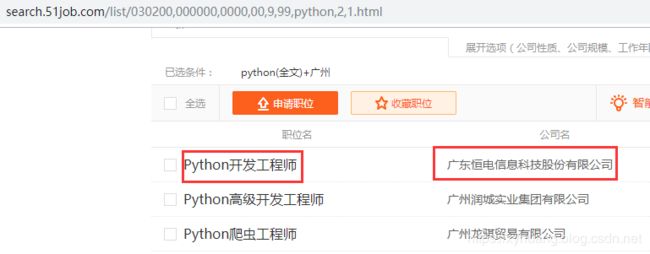
上述代码中,分别获取职位名、公司名称和公司信息页的URL地址,如图所示
本博文只简单讲述第三包goquery的使用,如果想了解详细的使用方法可以参考,下一节将讲述如何读取和解析JSON数据。