R语言-决策树算法(C4.5和CART)的实现
决策树算法的实现:
一、C4.5算法的实现
a、需要的包:sampling、party
library(sampling)
library(party)sampling用于实现数据分层随机抽样,构造训练集和测试集。
party用于实现决策树算法
另外,还可以设置随机数种子,可以获得相同的随机数。方便数据重复检验。
#设置随机数种子,可以获得相同的随机数
set.seed(100)我们使用iris数据集作为算法使用的数据集,通过下列各方法可以查看数据集的各种指标。
head(iris)
str(iris)
dim(iris)sub_train = strata(iris,
stratanames = "Species",
size = rep(35, 3),
method = "srswor")
data_train = iris[sub_train$ID_unit, ]
data_test = iris[-sub_train$ID_unit, ]c、训练模型
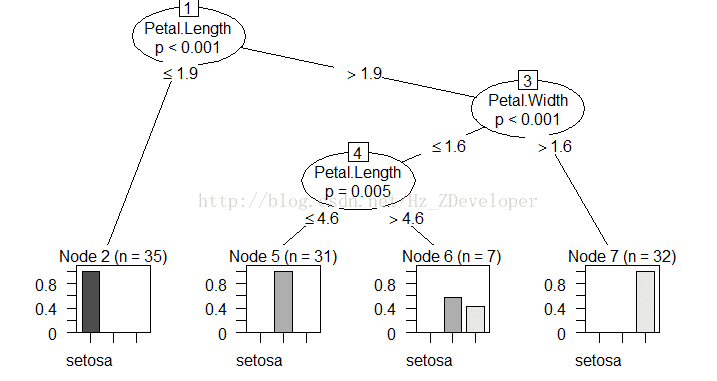
iris_tree = ctree(Species ~ ., data = data_train)#查看模型
print(iris_tree)
plot(iris_tree)
plot(iris_tree,type="simple")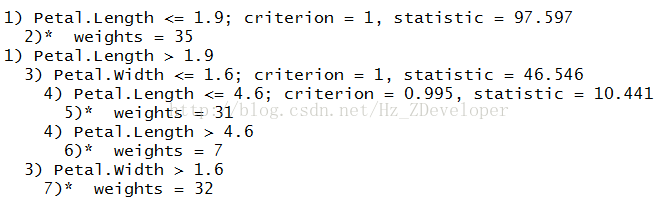

d、用测试集检验模型
test_pre = predict(iris_tree,newdata = data_test)
table(test_pre,data_test$Species)
correct = sum(as.numeric(test_pre)==as.numeric(data_test$Species))/nrow(data_test)
对测试集的判断准确率0.9333。
我们也可以看一下模型对训练集的判断准确率:
table(predict(iris_tree),data_train$Species)
correct = sum(as.numeric(predict(iris_tree))==as.numeric(data_train$Species))/nrow(data_train)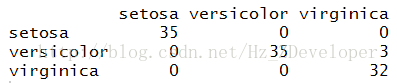
准确率0.97143。
二、CART算法的实现
添加以来的包
library(xts)
library(TTR)
library(quantmod)
library(ROCR)
library(DMwR)#查看所有连续变量的相关性,所有分类变量的卡方值
#连续变量
idx.num=which(sapply(algae,is.numeric))
idx.num
correlation=cor(algae$a1,algae[,idx.num],use = "pairwise.complete.obs")
correlation
correlation=abs(correlation)
correlation=correlation[,order(correlation,decreasing = T)]
correlation# 所有分类变量的卡方值
idx.factor=which((sapply(algae, is.factor)))
idx.factor
class(idx.factor)
algae[,idx.factor]
t1=table(algae$season,algae$size)
t1
chisq.test(t1)