DNN在线解码(以aishell的chain模型为例)
基于gmm模型的在线解码很简单,网上例子也比较多,但是基于DNN模型的在线解码资料很少,看官网的介绍也比较麻烦。在这里,我将自己做的DNN在线解码的过程记录下来给大家参考,有错误之处恳请指正。
我以aishell的chain模型为例(nnet3和chain的在线一样,只替换相应的文件路径即可)。
1,生成配置文件
./steps/online/nnet3/prepare_online_decoding.sh data/lang_chain exp/nnet3/extractor exp/chain/tdnn_1a_sp exp/chain/nnet_online
其中,lang_chain是存储chain模型解码网络图中G.fst和L.fst文件以及词汇表words.txt文件的文件夹
exp/nnet3/extractor文件夹内容如下:
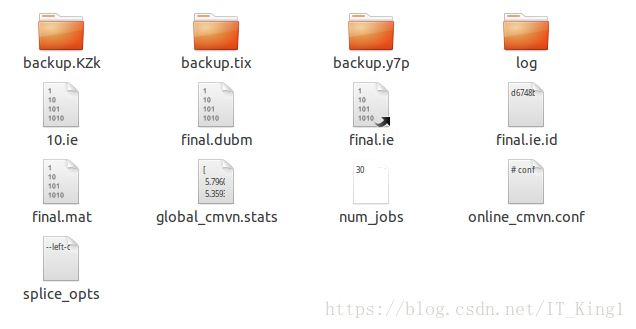
exp/chain/tdnn_1a_sp文件夹是存储chain模型的, exp/chain/nnet_online是自己定义存储生成配置文件的路径,生成的配置文件列表如下:

打开conf文件夹:
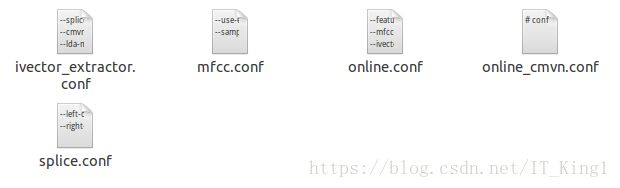
这样,在线解码的配置文件就生成成功了。
2,准备你要识别的音频,并用脚本生成spk2utt文件和wav.scp,spk2utt文件通过utt2spk_to_spk2utt.pl生成(在这之前你先要生成utt2spk文件),wav.scp写入待识别音频的路径。
3,需要kaldi源码里的三个程序:wav-copy,online2-wav-nnet3-latgen-faster,lattice-scale,然后执行以下命令:
./online2-wav-nnet3-latgen-faster --do-endpointing=false--frames-per-chunk=20 --extra-left-context-initial=0 --online=true--frame-subsampling-factor=3 --config=online.conf --min-active=200--max-active=7000 --beam=15.0 --lattice-beam=6.0 --acoustic-scale=1.0--word-symbol-table=words.txt final.mdl HCLG.fst ark:spk2utt'ark,s,cs:./wav-copy scp,p:wav.scp ark:- |' 'ark:|./lattice-scale--acoustic-scale=10.0 ark:- ark:- | gzip -c >lat.1.gz'
注意: 在该命令中,只需将我们刚才生成配置文件中的online.conf 文件的路径写入即可,其他配置文件都可以通过该文件找到,另外,words.txt final.mdl HCLG.fst spk2utt wav.scp文件请写对你自己的路径。
若以上步骤都没错,执行该命令后会导致如下错误:
LOG (wav-copy[5.3]:main():wav-copy.cc:68) Copied 1 wave files
ERROR (online2-wav-nnet3-latgen-faster[5.3]:OnlineTransform():online-feature.cc:421)Dimension mismatch: source features have dimension 91 and LDA #cols is 281
意思是特征维度不匹配。我们生成的配置文件里的特征类型是MFCC,而aishell训练nnet和chain模型输入的是更高维度的MFCC,叫mfcc_hire,hire是high resolution单词的缩写。所以我们要修改第一步生成的MFCC配置文件,打开mfcc.conf文件,我们看到:
--use-energy=false # only non-default option.
--sample-frequency=16000
添加新内容:
--num-mel-bins=40 # similar to Google's setup.
--num-ceps=40 # there is no dimensionality reduction.
--low-freq=40 # low cutoff frequency for mel bins
--high-freq=-200 # high cutoff frequently,relative to Nyquist of 8000 (=3800)
然后重新执行第三步的命令,可以看到识别结果已在终端输出。