优雅设计封装基于Okhttp3的网络框架(三):多线程下载功能核心实现 及 线程池、队列机制、终止线程解析
通过前两篇博文的学习,已经带领大家学习了HTTP协议与Okhttp相关内容的学习,并且在上篇博文已经完成了初始编码工作:定义好了网络请求接口DownloadCallback 和网络请求类HttpManager,可以完成同步、异步请求操作,而接下来将编码实现多线程下载功能的核心代码,通过多个线程之间的管理和调度来处理下载任务,最后再引入队列机制来完善功能。
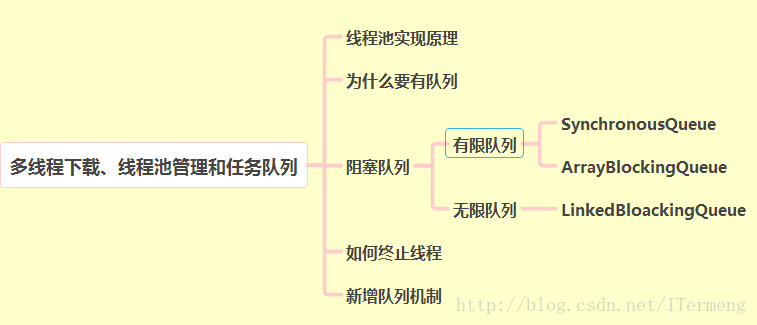
此篇文章将学习:
- 多线程核心功能编写
- 线程池原理学习
- 队列学习 和 终止线程方法
- 多线程下载引入队列机制
(建议阅读此篇文章之前,需理解前两篇文章的讲解,此系列文章是环环相扣,不可缺一,链接如下:)
优雅设计封装基于Okhttp3的网络框架(二):多线程下载功能原理设计 及 简单实现
优雅设计封装基于Okhttp3的网络框架(一):Http网络协议与Okhttp3解析
一. 多线程下载核心实现
1. DownloadManager 创建
既然要实现多线程下载,需要一个类来对多个线程进行统一管理和调度:DownloadManager类用来管理整个上层统一调用处理接口,照旧以单例模式提供实例对象,这里额外需要对线程管理,创建一个线程池ThreadPoolExecutor,分别传入参数:核心线程数、最大线程数、当前线程池存活时间、时间单位、Runnable、ThreadFactory,其中在创建的ThreadFactory匿名内部类中需要实现方法newThread ,创建一个Thread返回从出去,代码如下:
【DownloadManager 类】
public class DownloadManager {
public final static int MAX_THREAD = 2;
public final static int LOCAL_PROGRESS_SIZE = 1;
// private static final DownloadManager sManager = new DownloadManager();
private static DownloadManager sManager;
private static ThreadPoolExecutor sThreadPool = new ThreadPoolExecutor(MAX_THREAD, MAX_THREAD, 60, TimeUnit.MILLISECONDS, new LinkedBlockingDeque(), new ThreadFactory() {
private AtomicInteger mInteger = new AtomicInteger(1);
@Override
public Thread newThread(Runnable runnable) {
Thread thread = new Thread(runnable, "download thread #" + mInteger.getAndIncrement());
return thread;
}
});
public static DownloadManager getInstance() {
if (sManager == null) {
synchronized (DownloadManager.class) {
if (sManager == null) {
sManager = new DownloadManager();
}
}
}
return sManager;
}
private DownloadManager() {
}
} 2. DownloadRunnable
(1)构造方法
需要完成对线程的管理,还要实现一个Runnable接口,因为所有的多线程下载核心都在此操作。定义DownloadRunnable类实现Runnable接口,重写run 方法,不可或缺的用来指定下载位置的两个成员变量、下载URL和Callback回调,这四个局部变量在DownloadRunnable构造方法中可指定。
(2)run方法
接下来在run 方法内完成主要核心逻辑,首先还是进行同步网络请求,只是不同于普通地传入URL、DownloadCallback参数,还需要传入下载文件的起始和终止位置(即long值)注意:有关网络请求的部分还是交给HttpManager操作,但是上篇中编写的HttpManager类并不支持请求头的处理,所以我们需要在此类中多增加一个方法,代码如下:
【HttpManager 类】
/**
* 同步请求
*
* @param url
* @return
*/
public Response syncRequestByRange(String url, long start, long end) {
Request request = new Request.Builder().url(url)
.addHeader("Range", "bytes=" + start + "-" + end)
.build();
try {
return mClient.newCall(request).execute();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}以上完成后,可以正式开始编写DownloadRunnable的核心 —— run方法:
① 调用网络请求类HttpManager的同步方法,传入请求URL、下载位置起始末尾值,获取响应对象Response。
② 判断响应对象Response和回调DownloadCallback是否为空,为空则代表网络出现问题,则调用网络接口的
fail方法,传入错误码及信息返回,若不为空,代表请求成功,则继续处理。③传入请求的URL到文件管理类FileStorageManager,生成对应的文件,准备进行读写。此次写入同普通的有所不同,因为每个线程下载的具体位置不同,所以需要定位到下载的起始位置再进行写入,这里使用RandomAccessFile类来进行定位,其余部分大致相同。
(3)DownloadRunnable 代码
【DownloadRunnable 类】
public class DownloadRunnable implements Runnable {
private long mStart; //下载起始位置
private long mEnd; //下载终止位置
private String mUrl; //下载URL
private DownloadCallback mCallback;
public DownloadRunnable(long mStart, long mEnd, String mUrl, DownloadCallback mCallback) {
this.mStart = mStart;
this.mEnd = mEnd;
this.mUrl = mUrl;
this.mCallback = mCallback;
}
@Override
public void run() {
Response response = HttpManager.getInstance().syncRequestByRange(mUrl, mStart, mEnd);
if (response == null && mCallback != null) {
mCallback.fail(HttpManager.NETWORK_ERROR_CODE, "网络出问题了");
return;
}
File file = FileStorageManager.getInstance().getFileByName(mUrl);
try {
RandomAccessFile randomAccessFile = new RandomAccessFile(file, "rwd");
randomAccessFile.seek(mStart);
byte[] buffer = new byte[1024 * 500];
int len;
InputStream inStream = response.body().byteStream();
while ((len = inStream.read(buffer, 0, buffer.length)) != -1) {
randomAccessFile.write(buffer, 0, len);
}
randomAccessFile.close();
mCallback.success(file);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}3. DownloadManager 核心方法
在完成以后步骤后,可以开始编写DownloadManager 的核心方法 —— download ,此方法是暴露出来给外界调用,上层用户只需要传入请求Url和回调接口callback参数即可,至于具体文件大小,线程之间如何分配皆在此判断。
(1)首先调用网络请求类的HttpManager的异步方法,传入请求url,然后主要处理的逻辑在回调onResponse 方法中进行,先要判断响应数据是否成功,这里为后续的多线程下载考虑需多增加一个判断,即判断响应数据长度是否不为-1(后续会使用到数据长度),若不满足则调用接口的fail 方法传入错误码及信息,若满足代表请求成功,可进行核心逻辑。
(2)获取到数据长度后,可以开始处理多线程之间任务分配下载。举个例子来解释分配原理,例如待下载数据100字节,除以线程量2,则每个线程下载50字节即可,注意下载位置时从0开始,所以第一个线程下载0~49部分,另一个下载50~99部分。算法很简单,这样即可确定每个线程下载位置的起始、终止值。
(3) 在确定好每个线程的分配任务后,调用线程池对象的execute 方法提交任务,即传入参数 —— 创建一个DownloadRunnable(传入请求url、下载起始位置、下载终止位置)。
【DownloadManager 类】
/*
* 暴露上层调用的接口
* 多线程下载方法
* */
public void download(final String url, final DownloadCallback callback){
HttpManager.getInstance().asyncRequest(url, new Callback() {
@Override
public void onFailure(Call call, IOException e) {
Logger.debug("DownloadManager", "onFailure ");
}
@Override
public void onResponse(Call call, Response response) throws IOException {
if (!response.isSuccessful() && callback != null) {
callback.fail(HttpManager.NETWORK_ERROR_CODE, "网络出问题了");
return;
}
mLength = response.body().contentLength();
if (mLength == -1) {
callback.fail(HttpManager.CONTENT_LENGTH_ERROR_CODE, "content length -1");
return;
}
processDownload(url, mLength, callback);
}
});
}
/*
* 为每个线程分配下载任务并开启任务
* */
private void processDownload(String url, long length, DownloadCallback callback) {
// 100 2 50 0-49 50-99
long threadDownloadSize = length / MAX_THREAD;
for (int i = 0; i < MAX_THREAD; i++) {
long startSize = i * threadDownloadSize;
long endSize = 0;
if (endSize == MAX_THREAD - 1) {
endSize = length - 1;
} else {
endSize = (i + 1) * threadDownloadSize - 1;
}
sThreadPool.execute(new DownloadRunnable(startSize, endSize, url, callback));
}
}4. 测试多线程下载功能
以上三点,多线程下载功能的核心实现已经完成,当然有关于缓存本地、数据库相关类操作留给后续补充,这里只是将多线程下载流程执行完毕。这个测试依旧是请求下载腾讯网上一张图片,简单调用使用DownloadManager类,代码如下:
【MainActivity】
DownloadManager.getInstance().download("http://img1.gtimg.com/20/2000/200037/20003735_980x1200_0.png", new DownloadCallback() {
@Override
public void success(File file) {
final Bitmap bitmap = BitmapFactory.decodeFile(file.getAbsolutePath());
runOnUiThread(new Runnable() {
@Override
public void run() {
mImageView.setImageBitmap(bitmap);
}
});
Logger.debug("MainActivity", "success " + file.getAbsoluteFile());
}
@Override
public void fail(int errorCode, String errorMessage) {
Logger.debug("MainActivity", "fail " + errorCode + " " + errorMessage);
}
@Override
public void progress(int progress) {
}
});Log日志
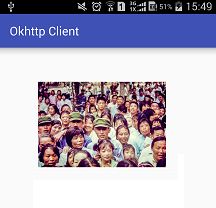
MainActivity: success /storage/emulated/0/Android/data/com.gym.okhttpclient/cache/2cf3ba0830d0883097478a266a61ee68应用结果:
5 . 小结
由以上结果截图可知,以上编写的类编码正确,该流程执行无误,与上一篇博客中的测试不同,上次是通过网络请求类HttpManager进行异步请求单线程下载图片,而此次是通过DownloadManager进行异步请求多线程下载图片。
也许以上请求在手机测试时两者效果并不明显,但是在下载大文件时,多线程下载的速度必然比单线程要快,这样的用户体验也更好。以上就是多线程下载核心的功能实现,但是功能并未实现完全,还有缓存、数据库等全面功能待实现,后续一一讲解。
二. 线程池实现原理
我们在完成多线程下载功能时涉及到了线程池的使用,在上部分并未讲解有关知识,可是在完成功能后不能连其本质底层都不知,线程池等原理也是大多数开发者的一个短板,所以此节来学习线程池管理等底层知识。
1 . 线程池理论
首先来思考一个问题:为什么要有线程池?
从OS操作系统的角度而言,线程池的使用可以节省线程的创建和开销的过程,因为线程操作的本质就是操作CPU资源,所以亲自对线程进行管理和调度是比较节省有限资源的。
所以系统提供了线程池ThreadPoolExecutor这样一个工具类,但是此工具类的使用并不容易,需要指定相关参数,这些参数意义与线程池原理也紧密相关,来查看:
【ThreadPoolExecutor 类】
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue workQueue, ThreadFactory threadFactory) {
throw new RuntimeException("Stub!");
} 以上是ThreadPoolExecutor 源码中的构造方法,其中参数的含义分别是:核心线程数、最大线程数、存活时间、时间单位、队列、ThreadFactory。例如以上实现多功能下载时创建的线程池,默认开启的核心线程数是2个,最大线程数也是2个存活时间为60秒,而创建的队列类型是LinkedBlockingDeque,最后创建的ThreadFactory,可以实现其newThread 方法指定线程名称。
简述线程池原理:
它默认开启的线程数是核心线程数,即线程池启动的时候就会开启核心线程数量的线程,下面可以提交线程任务,线程池会为开启的线程分配相关资源执行任务,此时还可以继续提交线程任务,这时核心线程正在工作,所以先将数据放到队列中,排队执行。
2 . 通过实例验证线程池原理
下面通过一个小demo来学习:
ThreadPoolExecutor sThreadPool = new ThreadPoolExecutor(2, 4, 60, TimeUnit.MILLISECONDS, new LinkedBlockingDeque(10)); 通过以上代码可知,创建出来的线程池中核心线程数为2,最大线程数为4,存活时间还是60秒,队列的可容纳值最大为10,至于ThreadFactory不指定也可。
线程池原理再论:
再次结合实例叙述线程池原理:线程池启动时会创建核心线程数量即2个线程,此时往线程池中提交任务,首先判断核心线程数是否启动,当核心线程在执行任务时,又提交了新的任务,会放到队列中等待执行。注意若队列中等待的任务数量超过了队列可容纳值,会判断最大线程数和核心线程数之间的差值,即继续创建其它的线程,也就是再创建2个线程。若此时还有多加的任务,此时会抛出异常,拒绝任务的提交。
下面通过循环提交任务来测试以上言论:
public class ThreadPoolTest {
public static void main(String args[]) throws InterruptedException {
final LinkedBlockingDeque queue = new LinkedBlockingDeque<>(10);
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 4, 60, TimeUnit.MILLISECONDS, queue);
for (int i = 0; i < 2; i++) {
final int index = i;
threadPoolExecutor.execute(new Runnable() {
@Override
public void run() {
System.out.println("index:" + index + ",queue size" + queue.size());
}
});
}
}
} 结果截图:
- a.【提交任务量为2】
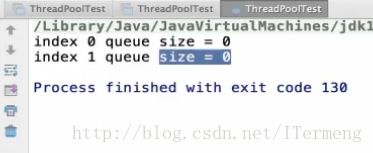
以上打印日志可知,我只提交了两个任务,队列中的数量为0,代表这两个任务分配给2个核心线程执行,所以并无等待任务
- b.【提交任务量为5】
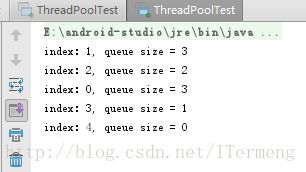
以上打印日志可知,若提交任务量为5,则两个核心线程执行任务,所以打印任务标识0,1时,队列中待执行任务数量为3,而打印任务2,3,4时,队列中任务量慢慢减少,最后为0。注意你可能疑惑怎么打印日志的任务index不是从0~4,记住线程之间的调度于CPU资源分配有关,所以并不是按照顺序的。
- c.【提交任务量为15】

以上打印日志可知,若提交任务量为5,则代表即使将最大限制数量的线程全部开启用来执行用户,并且队列中储存满带执行的任务,最大限制任务量为4+10=14,所以会报异常。
3. 解决任务量过多抛异常问题
- 方法一:
对于超出可执行最大任务量这种情况,系统为我们预备了解决方法,即创建线程池ThreadPoolExecutor多指定一个RejectedExecutionHandler策略参数,它的多个子类提供了不同的策略,例如DiscardOldestPolicy策略为:若线程池任务已满,将最老的任务移除。
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue workQueue, RejectedExecutionHandler handler) {
throw new RuntimeException("Stub!");
} - 方法二:
当然除了在创建线程池对象时额外指定策略,还有一个简单的方法,也是在创建线程池时将队列类型指定为LinkedeBlockingDeque,它属于无限制队列,即增加的任务来不及处理,可以存储在队列中,并无数量限制,但是当任务非常多时,系统应用会出现延迟,因为需要等待队列中的任务一个个执行。由于队列的无限制数量,并不会触发最大线程数量的开启,所以一直是核心线程在执行任务。这种资源消耗不可控情况并不理想,不建议使用。
三. 线程池中的队列 和 终止线程方法
以上在讲解完线程池相关内容后,对多线程下载之间的底层理解更加清晰,但其中涉及到了一个重要的数据结构,那就是队列,此节继续学习底层知识——队列。
1 . 线程池为什么需要队列
在提供网络请求时,可能某一时段接收大量请求,但是整个CPU资源有限,处理不了的请求放到队列中待处理,当线程资源可用的情况下,再从队列中取出相应的任务执行,队列中的算法为FIFO先进先出,而以上逻辑中正需要队列这种数据结构。
2 .阻塞队列
系统中提供的阻塞队列可分成以下两部分:有限队列和无限队列,顾名思义,有限队列是指队列长度有所限制,而无限队列对长度无限制。
(1)有限队列
SynchronousQueue
比较特殊的一种队列,满足生产者消费者模式,即队列长度只有一个,放入一个任务后,想要再放必须将之前的任务取出,否则处于阻塞状态。ArrayBlockingQueue
基于数组型的队列,在创建时需要指定其长度。
(2)无限队列
- LinkedBloackingQueue
对长度没有限制的队列,可以放置大量任务,注意其资源消耗,不推荐使用。
3 . 如何终止线程
关于终止线程的方法多数人第一想到的是定义一个标识变量,终止时设为false即可。不失是一个方法,但是在多线程的情况下会遇到变量已经被修改,但是值仍未变的情况。为了解决这种现象,有人想到了使用volitile关键字,保持当前标识变量值,即该变量修改后,其它相关线程会同步这个修改的信息。
(1)标识量终止线程
还是通过实际的demo来测试,首先测试用标识量flag来终止线程,代码如下:
public class ThreadStopTest {
static class FlagRunnable implements Runnable{
public boolean flag = true;
@Override
public void run() {
while (flag){
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("running");
}
}
}
public static void main(String args[]) throws InterruptedException {
FlagRunnable flagRunnable = new FlagRunnable();
Thread thread = new Thread(flagRunnable);
thread.start();
thread.sleep(1000);
flagRunnable.flag = false;
}
}显示结果:
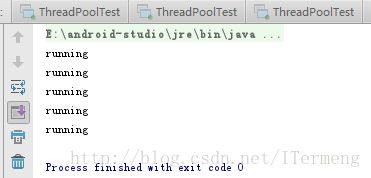
由以上图片结果可知,用标识的方法确实可以终止线程,但是如果Runnable中有耗时操作,线程处于阻塞状态,此时去修改标识量无法及时终止线程。
(2)Thread.interrupted()
为了去解决标识量方法出现的问题,介绍另一种大家常想到的 —– 通过Thread类的interrupted() 来终止线程,其实代码与以上类似,只是将flag标识量换成了判断Thread是否被interrupted,修改标识量该为将线程设置为interrupted状态,代码如下:
public class ThreadStopTest {
static class FlagRunnable implements Runnable{
//public boolean flag = true;
@Override
public void run() {
//标识量改变
while (!Thread.interrupted()){
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("running");
}
}
}
public static void main(String args[]) throws InterruptedException {
FlagRunnable flagRunnable = new FlagRunnable();
Thread thread = new Thread(flagRunnable);
thread.start();
thread.sleep(1000);
//调用线程的interrupt方法来终止线程
thread.interrupt();
}
}显示结果:
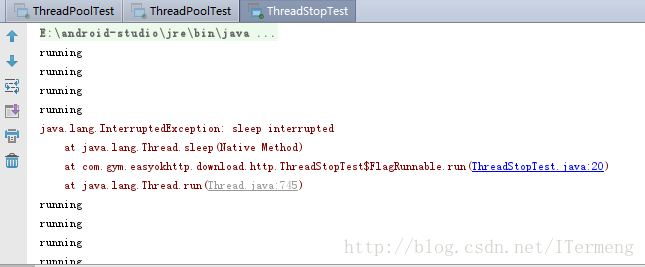
问题:
由以上图片结果可知,这样使用Thread.interrupted() 方法并未终止线程,不仅抛出异常,在我截图时Log日志还在不断打印“running”。异常定位在main方法中调用线程的interrupted()处,提示当前线程已被中断,该异常被FlagRunnable 中的catch捕捉到了,实际相当于线程已经中断了,执行到catch语句中,可是catch语句并未做任何相关操作,所以当下次循环时,线程的中断状态又变为正常状态,这样导致线程并未被中断。
解决方法☆☆☆☆☆:
经过以上分析,想要通过Thread.interrupted() 方法终止线程,除了以上代码外,还需要在FlagRunnable 中的catch语句中加上return; 代码。注意:调用线程的interrupted()方法只是将其状态置为终止状态,这样run 方法中的使线程休眠的代码执行会有异常,走到catch语句中,一定要在这处理,将其返回退出循环,否则它会继续下一次的循环,而线程的状态也会恢复。
(3)标识量 + Thread.interrupted() + volatile(最佳方法)
以上方法解决问题后可以很好的终止线程,但这并不是最佳方法,为了保证线程的终止状态立马同步,在循环判断时不仅判断线程的终止状态,也判断一个标识量,同方法一不同的是此标识量在定义时加上 volatile关键字,它可以保证变量在修改时能立刻同步到工作线程中。这时在main 方法终止状态时需要做两步操作:
- 将线程的状态置为中断,即调用Thread的
interrupt()方法。 - 将标识量置为false
这样做意味着通过标识量来控制线程中的循环,通过Thread的interrupt() 方法修改线程的状态,代码如下:
public class ThreadStopTest {
static class FlagRunnable implements Runnable{
public volatile boolean flag = true;
@Override
public void run() {
while (flag && !Thread.interrupted()){
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
return;
}
System.out.println("running");
}
}
}
public static void main(String args[]) throws InterruptedException {
FlagRunnable flagRunnable = new FlagRunnable();
Thread thread = new Thread(flagRunnable);
thread.start();
thread.sleep(1000);
flagRunnable.flag = false;
thread.interrupt();
}
}显示结果:
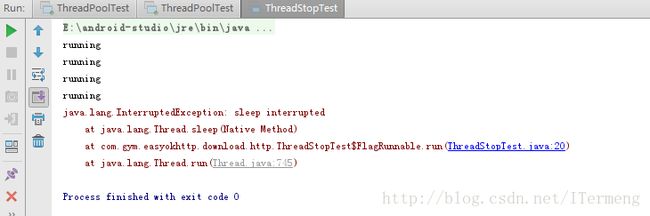
如果所示,通过以上最佳方法,可以全面保证线程的终止,是比较好的一种方法。
四. 多线程下载功能引入队列机制
通过以上的理论学习后,认识了线程池中的队列机制与它带来的好处,现将在已完成的多线程下载功能基础上引入队列机制。
1. DownloadTask
需要创建一个下载任务类,成员变量有请求Url、接口回调callback,还要实现equals、hashCode,代码并不难,查看其实现即可了解,代码如下:
public class DownloadTask {
private String mUrl;
private DownloadCallback mCallback;
public DownloadTask(String mUrl, DownloadCallback mCallback) {
this.mUrl = mUrl;
this.mCallback = mCallback;
}
public String getUrl() {
return mUrl;
}
public void setUrl(String mUrl) {
this.mUrl = mUrl;
}
public DownloadCallback getCallback() {
return mCallback;
}
public void setCallback(DownloadCallback mCallback) {
this.mCallback = mCallback;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
DownloadTask task = (DownloadTask) o;
if (mUrl != null ? !mUrl.equals(task.mUrl) : task.mUrl != null) return false;
return !(mCallback != null ? !mCallback.equals(task.mCallback) : task.mCallback != null);
}
@Override
public int hashCode() {
int result = mUrl != null ? mUrl.hashCode() : 0;
result = 31 * result + (mCallback != null ? mCallback.hashCode() : 0);
return result;
}
}2. DownloadManager
将队列机制引入到多线程下载功能中,新增代码步骤如下:
首先需要维护一个HashSet任务集合,保证每一个任务是唯一的值。
然后对这个队列进行添加任务,在DownloadManager类的
download方法中,每次下载时创建一个任务DownloadTask,传入参数请求url和回调callback,再判断队列中有无此任务,若存在则调用网络接口的fail方法并返回出去,因为已存在的任务无需再次下载,若没有则将任务添加到队列中,继续下载步骤。接下来进行移除操作,即不管网络请求成功与否,需要将此任务从队列中移除。定义一个finish方法,即调用队列的
remove方法,此方法在请求回调后的onFailure、onResponse中调用,这样可保证移除操作的完整性。
【DownloadManager 类中的新增代码】
public class DownloadManager {
......
//1.定义队列机制
private HashSet mHashSet = new HashSet<>();
//3.从队列中移除任务
private void finish(DownloadTask task) {
mHashSet.remove(task);
}
/*
* 暴露上层调用的接口
* 多线程下载方法
* */
public void download(final String url, final DownloadCallback callback){
//2.添加任务到队列中
final DownloadTask task = new DownloadTask(url, callback);
if (mHashSet.contains(task)) {
callback.fail(HttpManager.TASK_RUNNING_ERROR_CODE, "任务已经执行了");
return;
}
mHashSet.add(task);
HttpManager.getInstance().asyncRequest(url, new Callback() {
@Override
public void onFailure(Call call, IOException e) {
//4.请求结束,及时从队列中移除任务
finish(task);
Logger.debug("DownloadManager", "onFailure ");
}
@Override
public void onResponse(Call call, Response response) throws IOException {
if (!response.isSuccessful() && callback != null) {
callback.fail(HttpManager.NETWORK_ERROR_CODE, "网络出问题了");
return;
}
mLength = response.body().contentLength();
if (mLength == -1) {
callback.fail(HttpManager.CONTENT_LENGTH_ERROR_CODE, "content length -1");
return;
}
processDownload(url, mLength, callback);
//4.请求结束,及时从队列中移除任务
finish(task);
}
});
}
......
} 添加任务机制的好处:
任务机制可以有效地防止任务重新提交,举个例子:有这样一个需要,用户在UI上点击按钮添加下载任务,可能存在用户多次点击按钮导致应用程序多次下载任务,而这些任务是同一个!如上任务机制中HashSet队列的维护可以有效的避免这种现象的产生。添加队列机制后再次请求网络图片,显示正常,由于代码同第一节演示的效果相同,再次不重复贴。
五. 总结
1. 本篇总结
以上就是本篇内容的所有内容,相比较前两篇基础内容,正式进入到编码过程,可能第一篇有些不易了解,自己亲手敲代码实践、理清思路会对此理解更加深入。首先第一点完成了多线程下载的核心功能,完成两个线程同时下载任务,而第二点和第三点的线程池、队列机制内容偏理论性质讲解的学习,帮组我们更好理解多线程下载功能的原理本质,第四点队列机制的编码,实际运用队列知识融汇到多线程下载功能,使得功能更加完善、全面。
也许以上内容分段讲解部分读者不易理解,在以后的博文中源码会根据博客不断更新提供出来,供大家下载学习。(此次源码正在整理,明后天放出)
2. 下篇预告
呵呵,这个居然专门起一个题目,有点说书的意味~下篇将引入数据库,即采用greendao自动生成数据库相关代码、为多线程下载添加数据库支持、完善多线程下载的进度更新功能,敬请期待~~~
若有错误,欢迎指教~
(源码日后放出。正在整理)
希望对你们有帮组 :)