SqueezeDet:一种应用于自动驾驶实时目标检测中的标准、小型、低功耗的全卷积神经网络(三)
论文原文:SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving
源代码:https://github.com/BichenWuUCB/squeezeDet
论文翻译:XJTU_Ironboy
时间:2017年8月
4. 实验设计
我们在KITTI目标检测数据集(专门为自动驾驶而设计的)中对我们的模型进行了测评。我们通过测量平均精度(AP:average precision)、recall、速度和模型大小分析我们的模型,然后比较 KITTI 排行榜的其他排名方法。接下来, 我们通过调整几个关键参数的大小,浮点运算(FLOPS)和激活大小,分析了准确性和成本在模式方面的权衡。我们用 Tensorflow 实现了模型的训练、评价、误差分析和可视化,并用 cuDNN 计算内核编译。有关模型的能效实验将在补充材料中详细描述。
4.1 KITTI 目标检测
Experimental setup:在这个实验中,除非另有要求,我们将输入图片大小固定为1242 x 375。我们随机将7381训练图像分成了训练集和一个验证集。平均精度(AP:average precision)结果在验证集上得到,我们使用随机梯度下降的方法(Stochastic Gradient Descent with momentum)来优化损失函数,并将初始学习率设置为 0.01, 学习速率衰减因子为 0.5, 衰变步长为10000。我们不是使用固定数量的步骤, 而是一直训练该模型, 直到平均精度 (mAP) 的训练集收敛,然后在验证集上评估模型。除非另有要求,我们将batch size设置为20。我们采用了数据扩充技术, 如随机裁剪和翻转来减少过拟合。我们训练我们的模型来检测三种对象——汽车、行人和骑行者,并在模型中为每个网格使用了9个anchor,在训练阶段, 我们只保留前64个具有最高置信评分的检测结果,并且使用NMS(非最大值抑制)来过滤这些边界框。我们实验的硬件设备是NVIDIA TITAN X GPUs。
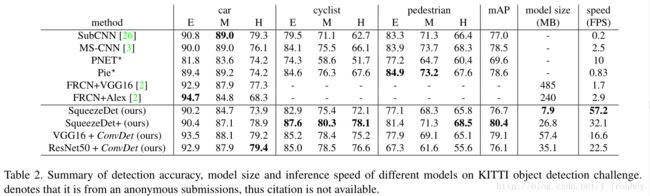
Average Precision:通过平均精度(AP:average precision)测量出的检测精度结果在表2中。我们提出的SqueezeDet +模型在KITTI 排行榜所有三个难度级别骑行者检测中取得了最好的AP。它在三类(汽车、行人和骑行者)所有3个难度级别的平均精度结果优于之前公布的方法。为了评估是否ConvDet可以应用到其他重要的CNN结构中,我们将ConvDet层添加到了 VGG16 和 ResNet50模型的卷积层中。在表2中,观察到这些模型都取得了具有很强竞争力的AP,尤其对汽车和自行车的检测。对于不同类型的错误检测的例子可以在图4中看出。

Recall: recall对于自动驾驶的安全是至关重要的,所以现在我们需要分析一下模型的recall。对于每张1242 x 375的图片,SqueezeDet生成15048个边界框的预测结果。由于 NMS(非最大值抑制) 的二次时间复杂度与边界框的数量有关, 因此在这许多边界框上执行非抑制是非常棘手的,于是我们只保留了前64预测结果, 以满足 NMS。有一个关键的问题是,如何确定边界框的数量来影响recall。我们用以下的实验来测试这个:首先搜集所有的边界框并将它们按照置信评分排序;接下来,对于每张图片,我们保留前 Nbox 个边界框预测结果,并且将这个 Nbox 值从8逐渐增加到15048;然后, 我们评估所有类别的所有难度级别的总体recall情况,Recall- Nbox 的关系曲线在图5中绘制出来了。
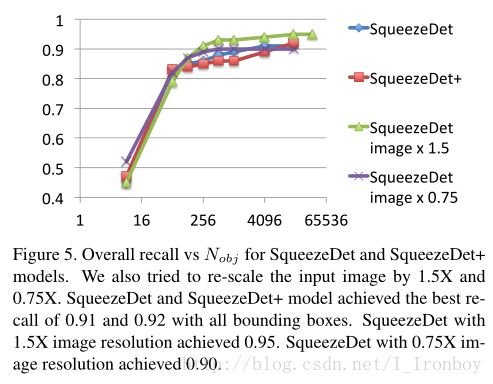
正如我们可以看出,对于 SqueezeDet和它的加强版( SqueezeDet+),前64个边界框的整体召回已经大于80%,如果使用所有的边界框, SqueezeDet 模型可以达到91% 和92% 的整体召回率。将输入图片增加到原图的1.5倍大时,边界框的总数量增加到了35190,并且使用所有边界框的最大召回率为95%
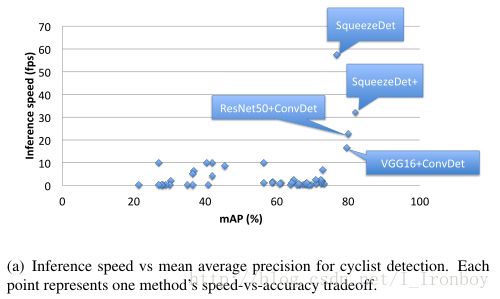
Speed: 我们的模型是第一个在 KITTI数据集上达到实时运行速度的。为了更好地理解场景,我们收集了40份 KITTI 数据集的骑行者检测报告的统计, 在 图 6 (a)绘制了他们的推断速度 vs 骑行者类下三个难度水平的平均精度的关系。在撰写本论文时, KITTI 排行榜上最快的是匿名提交的命名为 PNET的模型, 它具有10FPS 的运行速度。而我们提出的 SqueezeDet模型能到达57.2帧,而且相比 PNET来说准确度更高。而加强版 SqueezeDet+仍然能得到32.1FPS。对于 VGG16 和 ResNet50模型,运行速度仍然很慢,但是正如 表2、图6(a)可以看出,它仍然比 KITTI上所有已经提交的模型还要快。
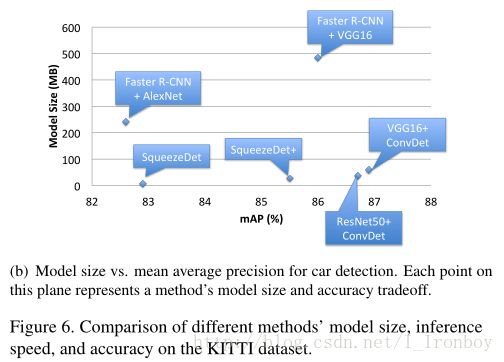
Model size:因为模型的大小在 KITTI排行榜上是不予公布的,所以我把我们的模型与 Faster R-CNN比较,我们在 图6(b)中绘制了模型大小与汽车类下三个难度水平的平均精度的关系,并将结果总结到了 表2中。正如我们在 表2可以看出, 我们的 SqueezeDet模型比 Faster R-CNN + VGG16模型小61倍,比 Faster R-CNN + AlexNet模型小30倍。实际上 VGG模型80%的参数量都来自于全连接层。因此,当我们用 ConvDet层来代替全连接层和 RPN层后,模型大小只有57.4MB。相比于 YOLO,这样一个由24个卷积层和2个全连接层,参数大小是753MB的结构, SqueezeDet模型在没有任何压缩的情况下仍然比它小95倍。
4.2 设计空间探索(Design space exploration)
我们进行了设计空间探索, 以评估一些关键的超参数对我们模型的整体检测精度的影响 (用 mAP 来进行测量)。同时, 我们还研究了这些变量的 “cost“, 从FLOPS, 运行速度, 模型大小和内存消耗,结果总结在表3中,其中第一行是我们的SqueezeDet结构,后续行是对 SqueezeDet 的修改,最后一行是SqueezeDet的加强版SqueezeDet +模型。
Image resolution:对于目标检测来说,增加图像分辨率是提高检测准确度的一个非常有效的方法。但是更大的图像会导致更大的激活、更多的浮点运算、更长的训练时间等等。我们现在评估这些指标的权衡。在我们的实验中,我们通过1.5X 和0.75X 分别缩放图像分辨率。随着图像越大,训练变得越缓慢。所以我们将batch size降低到10。正如我们在表3可以看出,放大输入图像实际会减小mAP,并且导致更多的浮点运算、更慢的运行速度和更大的内存消耗。我们也在缩小的输入图像中做一个实验。缩小图像会导致惊人的92.5 FPS的运行速度和更小的内存占用,尽管它的mAP只下降3个百分点。
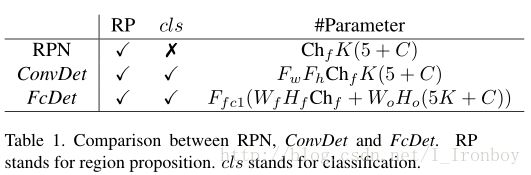
Number of anchors:要调整的另一个超参数是定位点(anchor)的数量。直观地说, 使用更多的anchor, 生成更多的边界框应该会导致一个更好的准确性。但是在我们的实验中(如表3所示),使用更多的anchor会导致更低的精度。但是它也显示了,使用了ConvDet层、增加了anchor数量的模型只适度地增加l模型大小、浮点运算量和内存占用。
Model architecture:正如我们之前讨论过的, 使用一个更强大的核心模型, 更多的参数大大提高了精确度 (见表3),但是这种修改在浮点运算、模型大小和内存占用方面的消耗也大大增加。
5. 结论
我们提出了SqueezeDet,一种用于实时目标检测的全卷积结构。我们将region proposition和分类器集成到了ConvDet层上,它包含参数的数量级小于全连接层结构。考虑到自主驾驶的限制,我们提出的SqueezeDet和SqueezeDet+模型被设计成为规模小、运行速度快、能量高效并且检测准确度高。在所有这些指标中,我们的模型更先进(the state-of-the-art)。
翻译完,原论文后三页还附有补充材料(主要是对能量利用效率的讨论与实验),感兴趣的同学可以自行看原论文,原论文下载链接在文章开头给出!
由于本论文较长,中文翻译分为三个部分连载:
SqueezeDet:一种应用于自动驾驶实时目标检测中的标准、小型、低功耗的全卷积神经网络(一)
SqueezeDet:一种应用于自动驾驶实时目标检测中的标准、小型、低功耗的全卷积神经网络(二)
注:第一次写博客,且水平有限,有些地方翻译的很不到位,望谅解!
如有问题需要讨论,可发送问题到我的邮箱:[email protected]