【scrapy】scrapy爬取豆瓣电影排行榜并写入数据库
scrapy是爬虫界常用的基于Python爬虫框架,但是网上找了很多这类的文章,发现有多处错误,故为了让刚想尝试爬虫的蜘蛛们少走点坑,故把最新的方法奉上。
在此之前,请先更新你的pip版本,并安装scrapy , pymysql。
pip install scrapy
python3 -m pip install pymysql首先我的目录结构是这样的,你可以使用如下命令进行初始化
scrapy startproject SpiderObject
//参考:https://blog.csdn.net/skullfang/article/details/78607942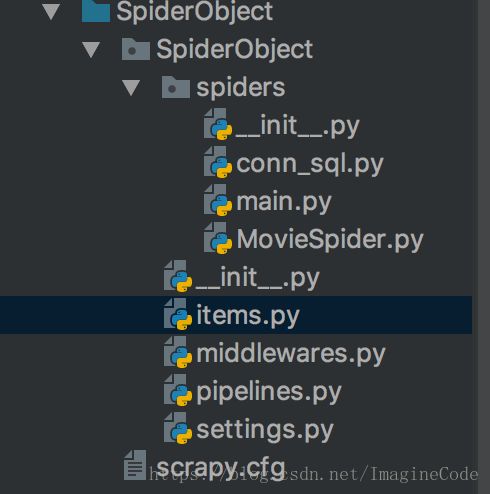
1.编写items.py
import scrapy
class MovieItem(scrapy.Item):
name = scrapy.Field()
movieInfo = scrapy.Field()
star = scrapy.Field()
number = scrapy.Field()
quote = scrapy.Field()
pass2.编写MovieSpider.py
# -*- coding: utf-8 -*-
from scrapy.spider import Spider
from scrapy.http import Request
from scrapy.selector import Selector
from SpiderObject.items import MovieItem
import requests
import time
class MovieSpider(Spider):
# 爬虫名字
name = 'MovieSpider'
# 反爬措施
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}
url = 'https://movie.douban.com/top250'
# start_urls = ['movie.douban.com']
def start_requests(self):
# url = 'https://movie.douban.com/top250'
yield Request(self.url, headers=self.headers, callback=self.parse)
def parse(self, response):
item = MovieItem()
selector = Selector(response)
movies = selector.xpath('//div[@class="info"]')
for movie in movies:
name = movie.xpath('div[@class="hd"]/a/span/text()').extract()
message = movie.xpath('div[@class="bd"]/p/text()').extract()
star = movie.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract()
number = movie.xpath('div[@class="bd"]/div[@class="star"]/span/text()').extract()
quote = movie.xpath('div[@class="bd"]/p[@class="quote"]/span/text()').extract()
if quote:
quote = quote[0]
else:
quote = ''
item['name'] = ''.join(name)
item['movieInfo'] = ';'.join(message).replace(' ', '').replace('\n', '')
item['star'] = star[0]
item['number'] = number[1].split('人')[0]
item['quote'] = quote
yield item
nextpage = selector.xpath('//span[@class="next"]/link/@href').extract()
time.sleep(3)
if nextpage:
nextpage = nextpage[0]
yield Request(self.url + str(nextpage), headers=self.headers, callback=self.parse)
3.编写pipelines.py与mysql数据库进行连接
import pymysql
class MoviePipeline(object):
def __init__(self):
# 连接数据库
self.conn = pymysql.connect(host='127.0.0.1',port=3306,user='root',passwd='root',
db='DOUBANDB',charset='utf8')
# 建立游标对象
self.cursor = self.conn.cursor()
self.cursor.execute('truncate table Movie')
self.conn.commit()
def process_item(self, item, spider):
try:
self.cursor.execute("insert into Movie (name,movieInfo,star,number,quote) \
VALUES (%s,%s,%s,%s,%s)", (item['name'],item['movieInfo'],item['star'],
item['number'],item['quote']))
self.conn.commit()
except pymysql.Error:
print("Error%s,%s,%s,%s,%s" % (item['name'],item['movieInfo'],item['star'],
item['number'],item['quote']))
return item4.设置settings.py
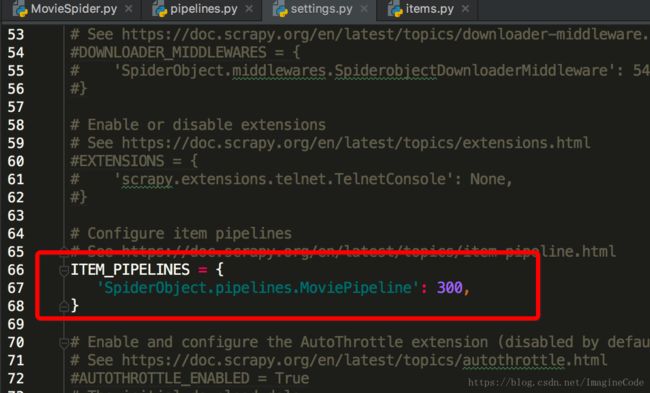
5.搭建mysql数据库
我们通过代码自动访问mysql数据库,
前提是你要先开启mysql连接,并在127.0.0.1下新建数据库DOUBANDB,如图所示:
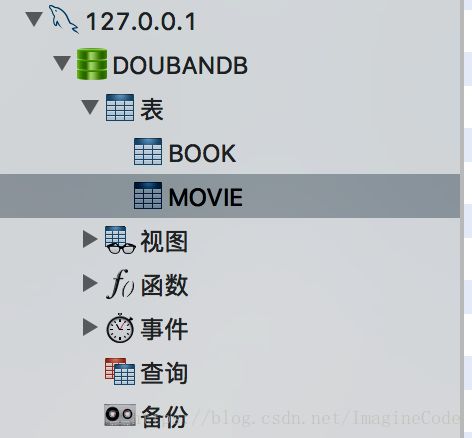
如何用代码自动添加并设计Movie表结构呢:
新建conn_sql.py
import pymysql
db = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root', db='DOUBANDB', charset='utf8')
cursor = db.cursor()
cursor.execute('DROP TABLE IF EXISTS MOVIE')
sql = """CREATE TABLE MOVIE(
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '自增 id',
name VARCHAR(1024) NOT NULL COMMENT '电影名',
movieInfo VARCHAR(1024) DEFAULT NULL COMMENT '电影简介',
star VARCHAR(20) NOT NULL COMMENT '评分',
number VARCHAR(1024) NOT NULL COMMENT '评价人数',
quote VARCHAR(1024) NOT NULL COMMENT '简评',
createtime DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '添加时间'
)"""
cursor.execute(sql)
db.close()
6.执行爬取并存入
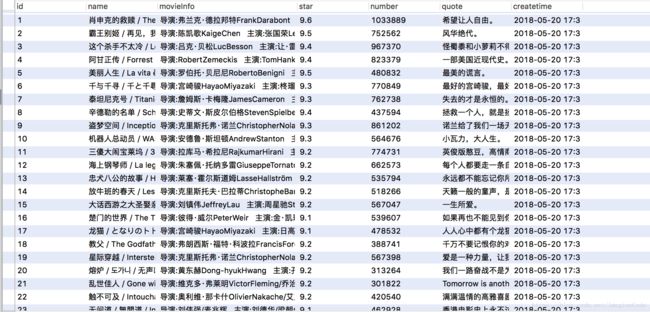
只需要执行一行代码:
scrapy crawl MovieSpider7.结果