Deep-compression 阅读笔记
参考链接1 参考链接2 参考链接3 参考链接4 参考链接5 参考链接6
引言--Why
模型压缩一直是机器学习的一个重要方向,并且一个模型不可能只在GPU和服务器上运行才可以。只有通过硬件化实现才能落地。但是神经网络也是非常耗费存储和耗费运算的。LeNet-5是一个简单的手写数字识别网络,AlexNet和VGG-16则用于图像分类,刷新了ImageNet竞赛的成绩,但是就其模型尺寸来说,根本无法移植到手机端App或嵌入式芯片当中,就算是想通过网络传输,较高的带宽占用率也让很多用户望尘莫及。另一方面,大尺寸的模型也对设备功耗和运行速度带来了巨大的挑战。随着深度学习的不断普及和caffe,tensorflow,torch等框架的成熟,促使越来越多的学者不用过多地去花费时间在代码开发上,而是可以毫无顾及地不断设计加深网络,不断扩充数据,不断刷新模型精度和尺寸,但这样的模型距离实用却仍是望其项背。本文希望通过一些方法把原本耗费大量存储和运算的神经网络实现在硬件上。

How
Deep Compression 的实现主要有三步,如下图所示:
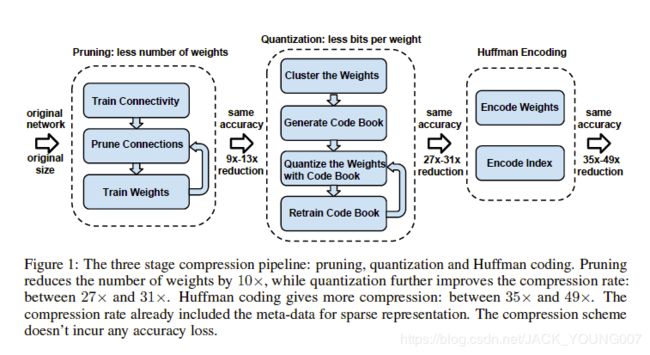
主要包括:
Pruning(权值修剪):去掉一些不必要的网络权值,只保留对网络重要的权值参数;
Weight Shared and Quantization(权值共享和量化):权值共享就是多个神经元见的连接采用同一个权值,权值量化就是用更少的比特数来表示一个权值;
Huffman Encoding(哈夫曼编码):对权值进行哈夫曼编码能进一步的减少冗余;
首先,网络通过正常的训练,训练出相应的权重,然后把低于某个阈值的权重删除掉,然后再训练模型,一次次去掉冗余的链接;然后网络把保留的权重进行聚类和权值共享,然后通过训练不断调整聚类的中心点和聚类的数量,然后将最后的权值和权值索引进行哈夫曼编码,达到模型压缩的效果。
Pruning (权值修剪)
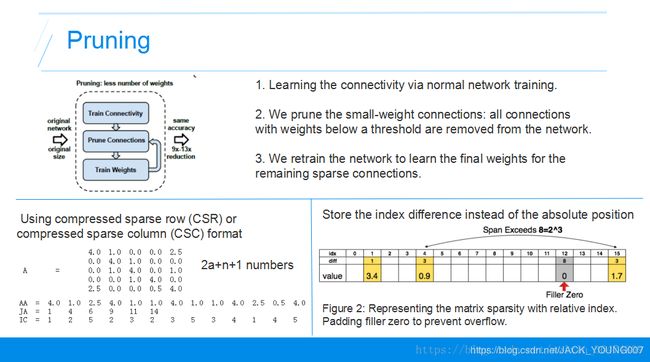
剪枝生成稀疏矩阵:
1. Learning the connectivity via normal network training. 通过正常方法训练网络得到网络权值
2. We prune the small-weight connections: all connections with weights below a threshold are removed from the network. 将小于某个阈值的权重扔掉,设为0不再训练
3. We retrain the network to learn the final weights for the remaining sparse connections. 重新训练相应的网络剩下的权重
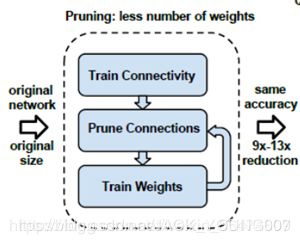
稀疏矩阵的存储:经过权值修剪后的稀疏网络,就可以用一种紧凑的存储方式CSC或CSR(compressed sparse column or compressed sparse row)来表示。
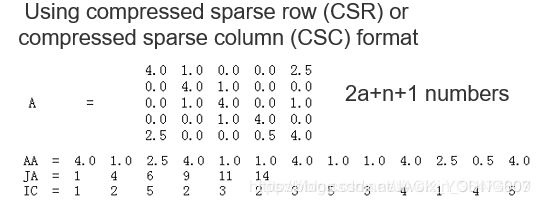
例如CSC的存储稀疏矩阵的方法
第一行AA存储所有的非零元素
第二行JA存储所有系数矩阵中每行第一个非零元素在AA的位置,例如第一个元素是4.0,在AA中位置是第一个,第二行第一个元素是4.0,在AA中位置是第四个。通过JA可以将AA中所有元素对应的行恢复出来。
第三行JC是所有元素对应的列标。
这样,一个稀疏的矩阵通过三行就能存下来,达到了很好的存储压缩,由N*N变为了2a+N+1个元素。
相对位置的参数:在压缩完参数之后,我们存了权值和权值对应的参数。之前的参数存的是绝对的参数,我们现在存相对的参数,就是两个参数的差值,比如我们用三个特存相对的参数,只要两个元素的距离小于8,都能把参数存为3个比特的,如果两个参数的距离大于这个值,我们就在第8个位置设置一个0值。
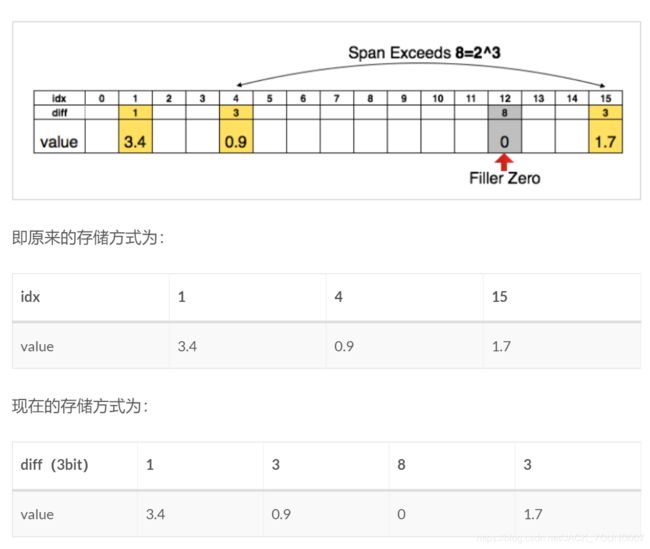
通过CSC得到了压缩的矩阵,可以通过差分存储进一步压缩存储数量。3bit可以容忍的间距为8:当间距小于8时,用3比特的值就可以恢复出相应的位置;当间距大于8时,在第8个位置插入0值,然后用3bit的与插入的0值的差分位置恢复出相应的位置;间距大于8的倍数时,每隔8个位置插入0值,与最后一个0值的3bit的差分位置恢复出位置。
Weight Shared and Quantization(权值共享和量化)
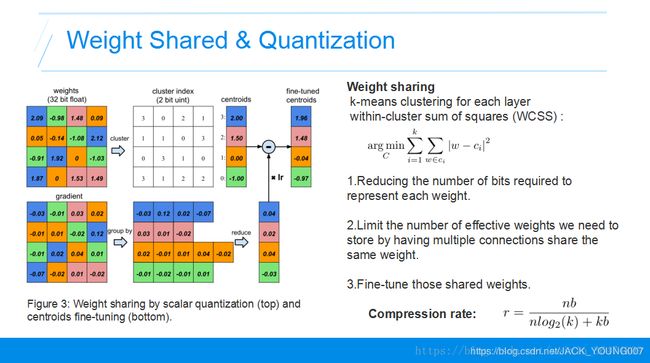
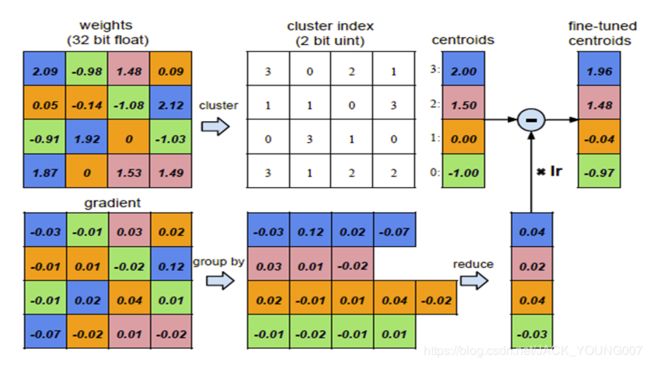
聚类方法:运用K-means的聚类方法,将权值接近的共享。运用聚类中心点的值作为所有权值的值。例如上面相同颜色的就是同一个聚类的。

权值更新方法 Fine-tune:将所有聚类的点的梯度相加作为权值中心的梯度用于更新权值。
压缩率:
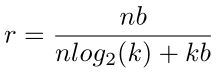
- 压缩前分子:原始权值的个数n,原始权重的比特数b,相乘得到原始总权值需要的比特数
- 压缩后分母:n为权重的个数,log2(k)表示聚类后的每一类的比特数。用这个可以恢复出共享的每一个权值属于哪一类,k为聚类数,b为之前的需要存储的精度,用这个可以恢复出每一个聚类的中心点的位置。
压缩率可以这样得出来,分子n是有n个权值要存储,b就是原始的每个权值的比特数,nb就是原来需要存储这些权值需要的比特数。分母n乘以log2(k)就是这n个权值需要乘以log2(k)个比特来表示每个权值的类,然后kb是所有类的中心点需要耗费的存储。
相应的梯度是这样更新的:只需要更新聚类的中心点的位置就好,我们把聚类内对应位置的梯度加起来,作为新的梯度,乘上学习率然后用聚类内中心点减去这个值。
权值共享的是聚类中心点的位置,初始的聚类中心点是如何确定的呢?
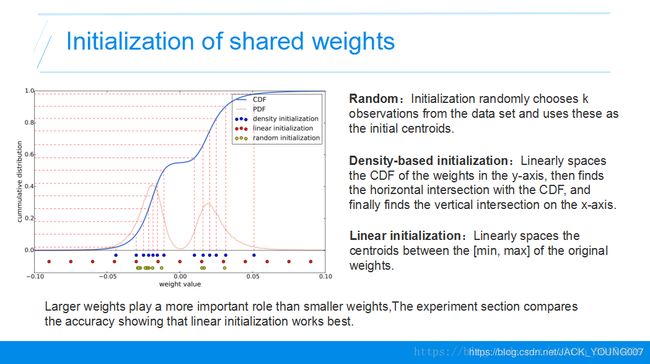
权值共享的是聚类中心点的位置,初始的聚类中心点是如何确定的呢?有三种方法可以确定聚类中心点的位置。一是随机的方法,就是在权值中随机的选k个值做为聚类中心点。还有一种是基于密度的初始化,我们可以看这个图,横轴是对应的权值的值,纵轴是权值的数量,类似于直方图一样。红色的线是权值的直方图统计,蓝色的线是权值的累积统计,类似于概率密度函数和概率累积函数。基于密度的初始化就是把权值从小到大等分成k份,然后每一份分界点的权值就是聚类的中心。线性的初始化就是直接把最小值最大值之间直接线性进行划分。
因为网络中大的权值往往是更重要的,前两种方法容易让聚类的中心点往概率密度大的地方累积,而线性分类法权值更容易是大的。所以线性的初始化方法比较好,通过后面的实验,也发现通过线性的分类方法取得了更好的准确率。
Huffman Encoding(哈夫曼编码)

哈夫曼编码运用字符出现的概率来进行编码,只要不是均匀分布的,哈夫曼编码就能减少一定的冗余。所以采用哈夫曼编码的方法,用短码代表出现频率高的权重,用长码替代出现频率低的权重,进一步对网络进行压缩。
实验数据
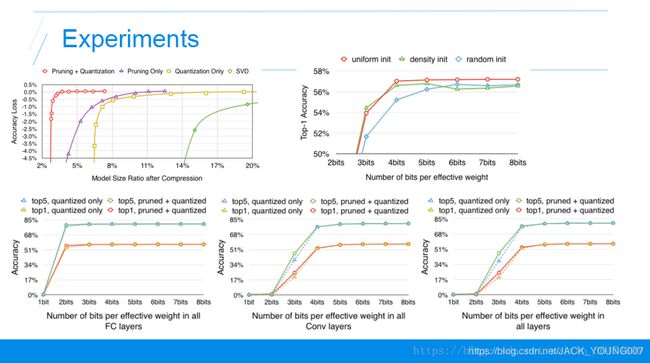
首先第一个实验,不同压缩方法在不同压缩率下精度的损失。横轴是压缩率,越靠左压缩率越大,纵轴是精度的损失,就是压缩之前和压缩之后的准确率的减少的量。这条曲线越靠左上越好,表明更大压缩率下精度损失更少,我们看到最好的方法就是剪枝和权值共享和权值量化的方法。
然后就是权值共享过程中,聚类的初始化值对实验结果的影响,三条曲线分别是上面讲到的三种不同的聚类方法。横轴是压缩的比特数,越靠左表明压缩的比率越大,纵轴是准确率,表明随着压缩的越来越少的比特数,精度越来越低,所以曲线越靠上越好。效果最好的是红色的这条线,就是我们初始聚类初始化的时候,采用线性初始化的方法能达到最好的效果。
下面这三个图表示不同的压缩率对不同层的影响,第一个是压缩的比特数对全连接层的影响,第二个是压缩的比特数对卷积层的影响,第三个是两个层的压缩比特数对实验结果的影响,我们发现卷积层比全连接层对压缩的比特数更加敏感。
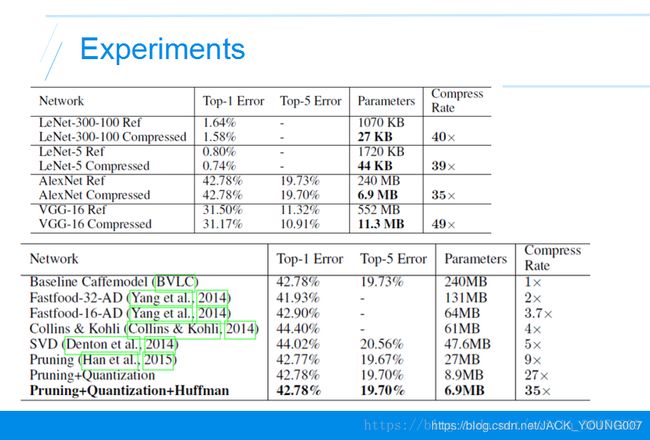
相应的实验,AlexNet压缩了35倍,把VGG压缩了49倍,相比其他的压缩方法,作者的方法没有精度损失并且达到了最大的压缩率。