BERT:Pre-training of Deep Bidirectional Transformers for Language
BERT: Bidirectional Encoder Representations from Transformers
1. 创新点
BERT旨在通过联合调节所有层中的左右上下文来预先训练来自未标记文本的深度双向表示。
2. Bert
总共分两步:
- pre-training:在预训练期间,模型在不同的预训练任务上训练未标记的数据。
- fine-tuning:对于微调,首先使用预先训练的参数初始化BERT模型,并使用来自下游任务的标记数据对所有参数进行微调。
2.1 Model Architecture
BERT’s model architecture is a multi-layer bidirectional Transformer encoder based on the original implementation described in Vaswani et al. (2017) and released in the tensor2tensor library.
2.1.1 前置要求
因为Bert里面用的是Transformer的结构,所以需要先阅读论文“attention is all you need”
2.1.2 定义模型
论文定义了两个模型,分布是 B E R T B A S E BERT_{BASE} BERTBASE和 B E R T L A R G E BERT_{LARGE} BERTLARGE:
B E R T B A S E ( L = 12 , H = 768 , A = 12 , T o t a l P a r a m e t e r s = 110 M ) BERT_{BASE} (L=12,H=768,A=12,Total Parameters=110M) BERTBASE(L=12,H=768,A=12,TotalParameters=110M)
B E R T L A R G E ( L = 24 , H = 1024 , A = 16 , T o t a l P a r a m e t e r s = 340 M ) BERT_{LARGE} (L=24,H=1024,A=16,Total Parameters=340M) BERTLARGE(L=24,H=1024,A=16,TotalParameters=340M)
- L : L: L: the number of layers(i.e., Transformer blocks)
- H : H: H: the hidden size
- A : A: A: the number of self-attention heads
B E R T B A S E BERT_{BASE} BERTBASE was chosen to have the same model size as OpenAI GPT for comparison purposes. Critically, however, the BERT Transformer uses bidirectional self-attention, while the GPT Transformer uses constrained self-attention where every token can only attend to context to its left.
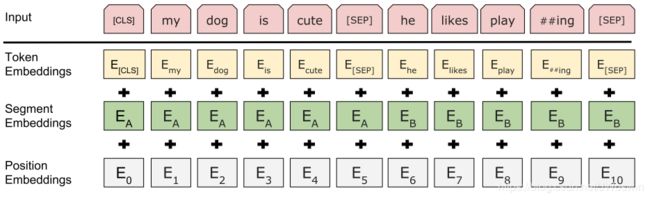
2.2 Input/Output Representations
2.2.1 句子处理
每个句子前面加 [ C L S ] [CLS] [CLS]
2.2.2句子对处理
- 句子之间用 [ S E P ] [SEP] [SEP]分开
- Second, we add a learned embedding to every token indicating whether it belongs to sentence A or sentence B.
3. Pre-training BERT
我们不使用传统的从左到右或从右到左的语言模型来预训练BERT。 相反,我们使用本节中描述的两个非监督的任务来预训练BERT。
3.1 Task #1: Masked LM
直觉上,有理由相信深度双向模型比左向右模型或从左到右和从右到左模型的浅层连接更有效,因为双向调节可以让每个单词直接“看到自己”,而模型可以在多层次的背景简单地预测目标单词。遗憾的是,标准的条件语言模型只能从左到右或从右到左进行训练。
为了训练深度双向表示:
一句话中取15%的词用 [ M A S K ] [MASK] [MASK]替换, 然后预测 [ M A S K ] [MASK] [MASK]替换的词原来是什么词
预测 [ M A S K ] [MASK] [MASK]替换的词原来是什么词时,把 [ M A K S ] [MAKS] [MAKS]对应的最终输出输入到一个softmax层(softmax层为词汇表大小)。
虽然这允许我们获得双向预训练模型,但缺点是我们在预训练和微调之间产生不匹配,因为[MASK]在微调期间不会出现。 为了缓解这种情况,我们并不总是用实际的[MASK]替换随机选择的字。
训练数据生成器随机选择15%的词进行预测。 如果选择了第i个词,我们用
- 80%的可能用[MASK]替换选中的第i个词
- 10%的可能随机选一个词来替换选中的第i个词
- 10%的可能选中的第i个词保留原来的词
3.2 Task #2: Next Sentence Prediction (NSP)
为了使模型理解句子间的关系, 任务2 在每个预训练样本中选择句子 A 和 B , 句子B有50%的几率是句子A的下一句 (labeled as IsNext), 50%的几率不是句子A的下一句 (labeled as NotNext).

如图1所示, C C C被用来预测句子B是不是句子A的下一句