Pandas数据对象进阶——Series和DataFrame
Pandas数据对象进阶
- 1. 汇总计算和描述数据
- sum方法、median方法、mode方法和mean方法
- idxmin和idxmax方法
- cumsum和cumprod方法
- describe方法
- 分位数
- mean, var,skew和kurt方法
- ptc_change方法
- 2. 相关系数和协方差
- Series相关系数和协方差计算
- DataFrame相关系数和协方差计算
- DataFrame与Series之间的相关系数和协方差
- 3. 唯一值、值计数和成员资格
- Series唯一值与计数
- DataFrame唯一值和计数
- 成员资格
- 4. 缺失值处理(重点)
- dropna方法删除缺失值
- fillna方法填充缺失值
- isnull方法判断哪项为缺失值
- notnull方法
1. 汇总计算和描述数据
在官网上目前Series和DataFrame能够对其数据进行操作的方法有,


sum方法、median方法、mode方法和mean方法
如上这些方法对数据进行基本的统计计算,
1)sum方法求和,
![]()
通过下面的实例进行说明,首先构建一个DataFrame对象,

对该对象使用sum方法进行求和运算,
![]()
默认情况下,axis参数值为0,即按列计算,
![]()
如果设置axis参数值为1,则为按行计算,
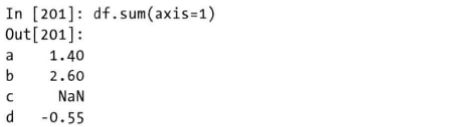
当某行存在缺失值时,默认会得到缺失值。skipna参数默认情况下值为True,固有 1.4 + NaN =1.4,计算过程中遇缺失值会被自动视为0;若将 skipna参数设置为 False,才会得到正常结果 1.4 + NaN = NaN。
sum方法的min_count参数是新的pandas版本中新加入的,传入的是一个整数,默认值为0,这个参数的意思是如果存在少于min_count的非NA值,则结果将是NA。
pd.Series([]).sum() # min_count=0 is the default,返回0.0
pd.Series([]).sum(min_count=1) #非缺失值个数小于1,于是返回nan
pd.Series([np.nan]).sum() #返回 0.0
pd.Series([np.nan]).sum(min_count=1) #非缺失值个数小于1,于是返回nan
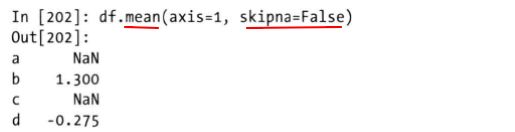
2)mean方法求取均值,
![]()
mean方法的使用与sum方法的使用基本一致,
3)mode方法求取众数
![]()
df = pd.DataFrame({'A': [1, 2, 1, 2, 1, 2, 3]})
df.mode() #返回 A
# 0 1
# 1 2
4)median方法计算中位数
![]()
median方法的使用与mean和sum方法相同,省去演示部分。
Series由于是一维的,所以对于Series而言axis参数只能为0,如果设置为1会报错。
idxmin和idxmax方法
返回最大值和最小值对应的索引,

使用idxmax方法返回最大值时对应的索引,对于DataFrame而言,默认情况下idxmax和idxmin是逐列进行分析并返回结果的,

如果是空的Series或者Dataframe,会报出ValueError的错误。
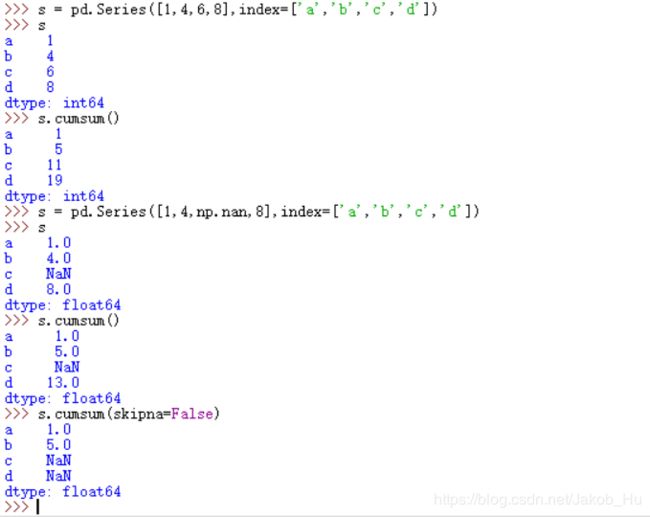
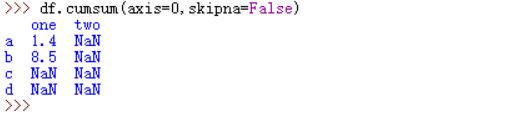
cumsum和cumprod方法
对元素进行累加,
![]()
对元素进行累积,
![]()
1)Series累加,axis参数值无需指定,默认为0;如果设置为1,会报出ValueError,
2)Dataframe累加,axis参数无论设置为0或1时,均是以列为单位进行统计。

累乘是同理。
describe方法
返回的是全面的统计信息
1)数值型数据返回的信息


2)非数值型数据返回的信息

分位数
quantile方法,用于返回分位数,一般常见的下四分位数、中位数和上四分位数可以用该方法得到,
![]()
![]()
下四分位数、中位数和上四分位数对应的q值分别为 0.25、0.5和 0.75。
q参数可以是小数,也可以是一个数组。如果是小数,返回的是该分位数上的值;如果是数组,

interpolation参数是在所求的分位数介于某两个数之间时,如何求取的设定,

s = Series([1, 2, 3, 4])
s.quantile(.5) #求取中位数,返回 2.5
s.quantile([.25, .5, .75]) #求取三种四分位数返回 0.25 1.75
# 0.50 2.50
# 0.75 3.25
# dtype: float64
df = DataFrame(np.array([[1, 1], [2, 10], [3, 100], [4, 100]]), columns=['a', 'b'])
#返回 a b
# 1 1
# 2 10
# 3 100
# 4 100
df.quantile(.1) #十分位数返回 a 1.3
# b 3.7
# dtype: float64
df.quantile([.1, .5]) #十分位数和中位数,返回 a b
# 0.1 1.3 3.7
# 0.5 2.5 55.0
mean, var,skew和kurt方法
这里再次提及mean方法不是因为重复,而是结合着其他三个方法一起讲解,样本量很大的时候,大数定律可得,一阶矩是样本的期望(平均数)、二阶矩是样本的方差、三阶矩是样本的偏度、四阶矩是样本的峰度。
ptc_change方法
在官方文档中这个方法的解释为“Percent change over given number of periods.”,将数值转变为一段时期的百分比变化。
![]()
对方法中的参数进行说明,

具体的演示如下,

指定不同的period参数值,

2. 相关系数和协方差
首先给出相关系数和协方差的公式,
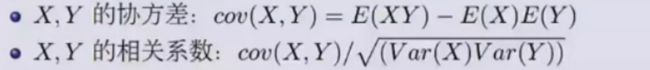
以雅虎的finance股票价格和成交量进行演示说明,首先生成如下数据,

使用上节中的pct_change方法求取变化的百分比,
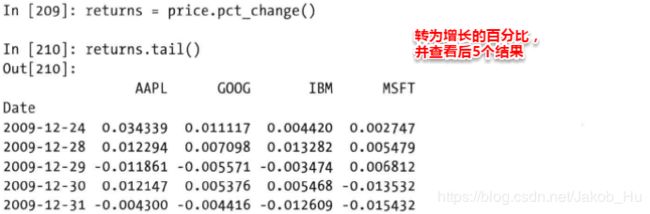
Series相关系数和协方差计算
相关系数使用的是corr方法,协方差的计算使用的是cov方法,
1)相关系数计算
![]()
其中method参数有三项可选,

min_period参数官方文档给出的解释“Minimum number of observations needed to have a valid result”,默认为None,设置一个整数,只有样本量多于这个值,返回的结果才不会是Nan。
计算MSFT和IBM两个企业股票相关系数,
![]()
计算的是两个Series之间重叠且非NaN的,每个Series相当于一个总体,根据最上面的公式计算相关系数。
2)协方差计算
![]()
依旧是刚才两家企业股票数据的协方差,
![]()
DataFrame相关系数和协方差计算
1)相关系数计算
同样使用的是DataFrame类的corr方法,
![]()
参数与Series的稍有区别,因为Dataframe是多个Series构成的,所以不用在通过 other参数传入值,Dataframe的corr方法计算的是列中,两两之间的相关系数,故返回的是相关系数矩阵,
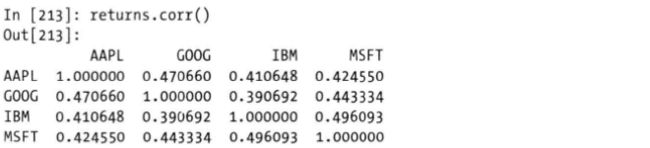
2)协方差计算
![]()
cov方法也是同理,无需传入other参数,返回的是协方差矩阵,
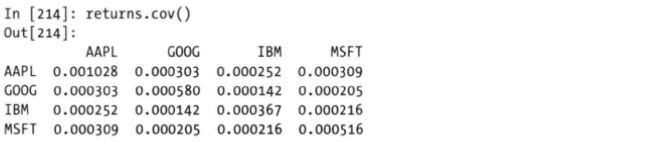
DataFrame与Series之间的相关系数和协方差
使用的是corrwith方法,其中,axis参数默认为0,官方文档中的解释,“0 or ‘index’ to compute column-wise, 1 or ‘columns’ for row-wise”,即axis=0是把每列视为一个总体;axis=1是把每行视为一个总体。other参数实际上传入的既可以是Series也可以是Dataframe,
![]()
1)other参数传入一个Series
这个Series将与组成Dataframe的每个Series求取相关系数,并最终返回一个相关系数Series,索引值是Dataframe中各个列的名字。

2)other参数传入一个DataFrame
两个Dataframe将共有的列配对,并计算相关系数,返回的同样是一个Series,索引值是两个Dataframe共有列的列名, 此时计算股价与成交额的相关系数,传入volume这个Dataframe,
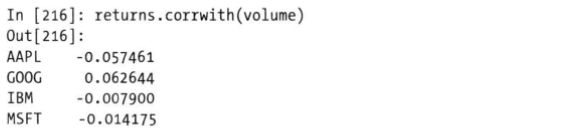
3. 唯一值、值计数和成员资格
Series唯一值与计数
1)唯一值
唯一值使用的是 unique方法,返回的是未排序的唯一值的一维数组(numpy数组)。官方文档中的注解"Significantly faster than numpy.unique. Includes NA values.",比numpy的unique方法高效,返回的数组包含缺失值。
![]()
使用unique方法计算唯一值,

2)计数
使用的是value_counts方法,计算的是Series各个唯一值出现的频数,返回的还是一个Series,结果是默认按照频数降序排列的,
![]()
参数说明,
| 参数 | 说明 |
|---|---|
| normalize参数 | 如果为True,If True then the object returned will contain the relative frequencies of the unique values.实际上返回的就是概率(归一化值)。 |
| sort参数 | 默认是True,Sort by values。 ascending参数为True时,为升序排列。 |
| dropna参数 | 默认为True,Don’t include counts of NaN.不计算缺失值的频数。 |
具体演示,

DataFrame唯一值和计数
Dataframe不能直接使用unique方法统计唯一值,
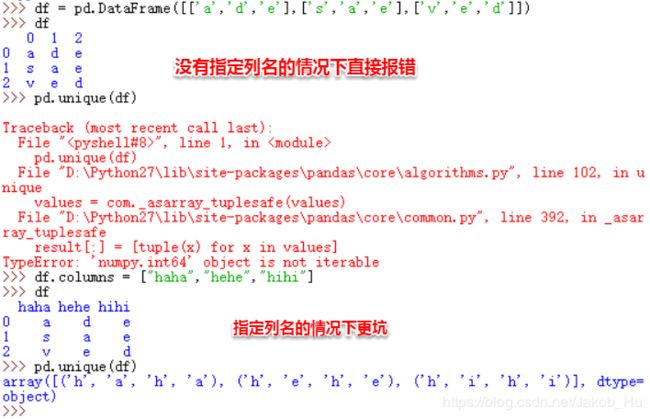
如果要求得唯一值,可以对Dataframe的每列进行操作,因为一列可以视为一个Series。
同样的,value_counts方法也不能直接使用于Dataframe上,需要通过apply方法进行传递,

1)计数

统计序列中字符出现频率,


成员资格
成员资格就是用于判断元素是否存在于Series中。
成员资格的操作对象也是Series,使用的是isin方法,返回的是布尔型的Series,可以用于选取Series的子集。
![]()

4. 缺失值处理(重点)
pandas中处理缺失值的方法有这几种,

dropna方法删除缺失值
Series类的dropna方法,
![]()
DataFrame的dropna方法,
![]()
Series的dropna方法使用很简单,且只有axis=0这一个维度,如果设置axis=1,则会报错。
Dataframe的dropna的axis参数有0和1两种,axis=0时候,如果在一行中有缺失值,就会默认删除该行;axis=1时,某列存在缺失值就会删除该列。默认axis=0。
how参数有“all”和“any”两种选择,官方文档的解释
| 取值 | 说明 |
|---|---|
| all | if all values are NA, drop that label(当全部是缺失值的时候,在all模式下才会删除这一行或者这一列。) |
| any | if any NA values are present, drop that label.(当任意一个是缺失值是,any模式下就会删除这一行或者这一列。) |
how参数的默认值为any。
thresh参数,设置一个整数,该阈值限制至少有几个非缺失的值。
subset参数,指定的是其中某几列的缺失值,而不是全部的缺失值。
具体的演示如下,
df = pd.DataFrame([[np.nan, 2, np.nan, 0],
[3, 4, np.nan, 1],
[np.nan, np.nan, np.nan, 5]],columns=list('ABCD'))
#返回 A B C D
# 0 NaN 2.0 NaN 0
# 1 3.0 4.0 NaN 1
# 2 NaN NaN NaN 5
df.dropna(axis=0) # 返回Empty DataFrame, 因为每行都有缺失值
# Columns: [A, B, C, D] Index: []
df.dropna(axis=1) #返回 D 只有D列没有缺失值
# 0 0
# 1 1
# 2 5
df.dropna(axis=0, how='all') #返回 A B C D 因为每行都不是全部缺失
# 0 NaN 2.0 NaN 0
# 1 3.0 4.0 NaN 1
# 2 NaN NaN NaN 5
df.dropna(thresh=2) #返回 A B C D
# 0 NaN 2.0 NaN 0
# 1 3.0 4.0 NaN 1
fillna方法填充缺失值
Series的fillna方法,
![]()
DataFrame的fillna方法,
![]()
Series的fillna方法较为简单,其中axis参数只能是0,设置为1时会报错。Dataframe的axis为1时,填补的分别是行上的缺失值;axis为0时,填补的是列上的缺失值。
value参数官方文档中的说明,“scala、dict、Series or DataFrame”,在dict、Series和Dataframe中要注意:a dict/Series/DataFrame of values specifying which value to use for each index (for a Series) or column (for a DataFrame).指明填补的是什么位置的缺失值。
method参数是极为重要的,

| 参数取值 | 说明 |
|---|---|
| pad/ffill | 用前一个非缺失值去填充该缺失值; |
| backfill/bfill | 用下一个非缺失值填充该缺失值; |
| None | 指定一个值去替换缺失值; |
默认情况下,method参数值为None。
limit参数指定的是填充多少个缺失值。
df = pd.DataFrame([[np.nan, 2, np.nan, 0],
[3, 4, np.nan, 1],
[np.nan, np.nan, np.nan, 5],
[np.nan, 3, np.nan, 4]],columns=list('ABCD'))
#返回 A B C D
# 0 NaN 2.0 NaN 0
# 1 3.0 4.0 NaN 1
# 2 NaN NaN NaN 5
# 3 NaN 3.0 NaN 4
#全部缺失值用0填补
df.fillna(0) #返回 A B C D
# 0 0 2.0 0 0
# 1 3.0 4.0 0 1
# 2 0 0 0 5
# 3 0 3.0 0 4
#使用前面的非缺失值补缺
df.fillna(method='ffill') #返回 A B C D
# 0 NaN 2.0 NaN 0
# 1 3.0 4.0 NaN 1
# 2 3.0 4.0 NaN 5
# 3 3.0 3.0 NaN 4
#使用 dict补缺,一定指明补得是那一列或者行
values = {'A': 0, 'B': 1, 'C': 2, 'D': 3}
df.fillna(value=values) #返回 A B C D
# 0 0.0 2.0 2.0 0
# 1 3.0 4.0 2.0 1
# 2 0.0 1.0 2.0 5
# 3 0.0 3.0 2.0 4
#使用limit参数限定只填补第一个缺失
df.fillna(value=values, limit=1) #返回 A B C D
# 0 0.0 2.0 2.0 0
# 1 3.0 4.0 NaN 1
# 2 NaN 1.0 NaN 5
# 3 NaN 3.0 NaN 4
isnull方法判断哪项为缺失值
isnull方法是无参数方法,返回的是布尔类型的Series和DataFrame,
df = pd.DataFrame(np.random.randn(10,6)) # Make a few areas have NaN values
df.iloc[1:3,1] = np.nan
df.iloc[5,3] = np.nan
df.iloc[7:9,5] = np.nan
#得到 0 1 2 3 4 5
#0 0.520113 0.884000 1.260966 -0.236597 0.312972 -0.196281
#1 -0.837552 NaN 0.143017 0.862355 0.346550 0.842952
#2 -0.452595 NaN -0.420790 0.456215 1.203459 0.527425
#3 0.317503 -0.917042 1.780938 -1.584102 0.432745 0.389797
#4 -0.722852 1.704820 -0.113821 -1.466458 0.083002 0.011722
#5 -0.622851 -0.251935 -1.498837 NaN 1.098323 0.273814
#6 0.329585 0.075312 -0.690209 -3.807924 0.489317 -0.841368
#7 -1.123433 -1.187496 1.868894 -2.046456 -0.949718 NaN
#8 1.133880 -0.110447 0.050385 -1.158387 0.188222 NaN
#9 -0.513741 1.196259 0.704537 0.982395 -0.585040 -1.693810
df.isnull()
# 得到 0 1 2 3 4 5
# 0 False False False False False False
# 1 False True False False False False
# 2 False True False False False False
# 3 False False False False False False
# 4 False False False False False False
# 5 False False False True False False
# 6 False False False False False False
# 7 False False False False False True
# 8 False False False False False True
# 9 False False False False False False
df.isnull().any() # 则会判断哪些”列”存在缺失值
#得到
#0 False
#1 True
#2 False
#3 True
#4 False
#5 True
#dtype: bool
df[df.isnull().values==True] #可以只显示存在缺失值的行列。
#得到
# 0 1 2 3 4 5
#1 1.090872 NaN -0.287612 -0.239234 -0.589897 1.849413
#2 -1.384721 NaN -0.158293 0.011798 -0.564906 -0.607121
#5 -0.477590-2.696239 0.312837 NaN 0.404196 -0.797050
#7 0.369665 -0.268898 -0.344523 -0.094436 0.214753 NaN
#8 -0.114483 -0.842322 0.164269 -0.812866 -0.601757 NaN
notnull方法
是isnull方法的反方法。