异常检测——基于Autoencoder的反欺诈数据集的异常检测
Autoencoder算法是一种常见的基于神经网络的无监督学习降维方法(其他常见降维方法)。
本教程中,我们利用python keras实现Autoencoder,并在信用卡欺诈数据集上进行异常检测算法。
1. Autoencoder简介
Autoencoder,中文称作自编码器,是一种无监督式学习模型。本质上它使用了一个神经网络来产生一个高维输入的低维表示。Autoencoder与主成分分析PCA类似,但是Autoencoder在使用非线性激活函数时克服了PCA线性的限制。
Autoencoder包含两个主要的部分,encoder(编码器)和 decoder(解码器)。Encoder的作用是用来发现给定数据的压缩表示,decoder是用来重建原始输入。在训练时,decoder 强迫 autoencoder 选择最有信息量的特征,最终保存在压缩表示中。最终压缩后的表示就在中间的coder层当中。
以下图为例,原始数据的维度是10,encoder和decoder分别有两层,中间的coder共有3个节点,也就是说原始数据被降到了只有3维。Decoder根据降维后的数据再重建原始数据,重新得到10维的输出。从Input到Ouptut的这个过程中,autoencoder实际上也起到了降噪的作用。
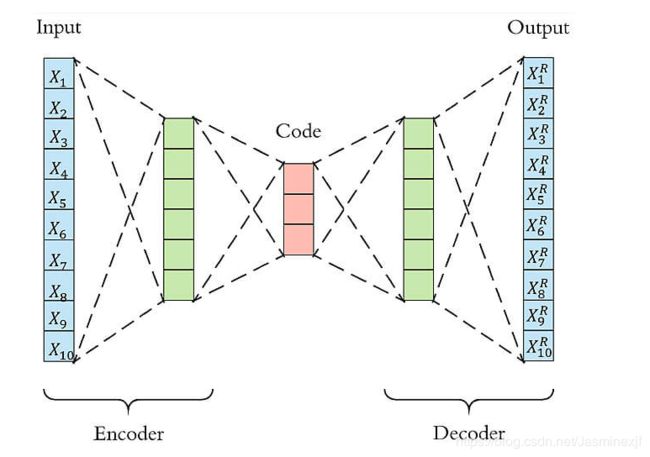

3. 利用Antoencoder检测信用卡欺诈
接下来是利用keras对信用卡的欺诈数据进行异常检测算法的实施。
下图是该project文件下的文件结果:
__init__.py:是初始化py文件。
processed.py:是数据预处理的函数,主要包括删除时间列、对amount列进行标准化;对正常样本和异常样本进行比例的可视化(fig1_);将所有正常数据按照8:2的划分规则划分成X_train,X_test,将异常样本写成X_fraud。
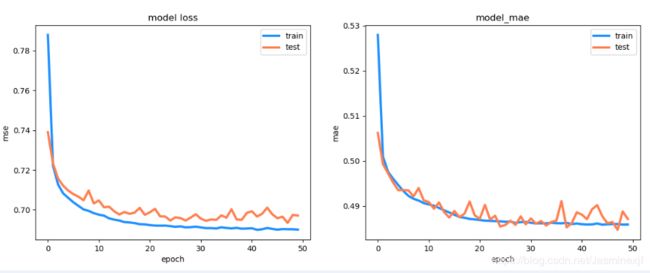
auto_model.py:利用keras框架写的autoencoder模型,并对训练结果进行可视化,分别在X_test和X_fraud(fig2_)
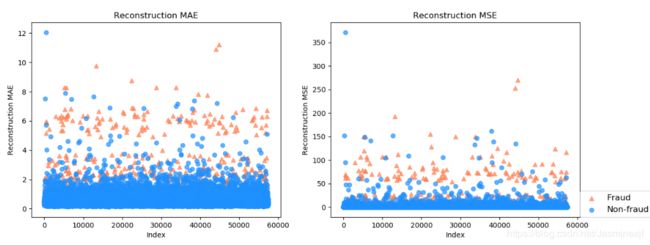
auto_test.py:依据训练的模型sofasofa_model.h5,在X_test,X_fraud进行可视化结果:
fig3_:横轴是index,纵轴是分别在X_test和X_fraud的还原误差MSE和MAE,前者是loss;后者是metrics的mae
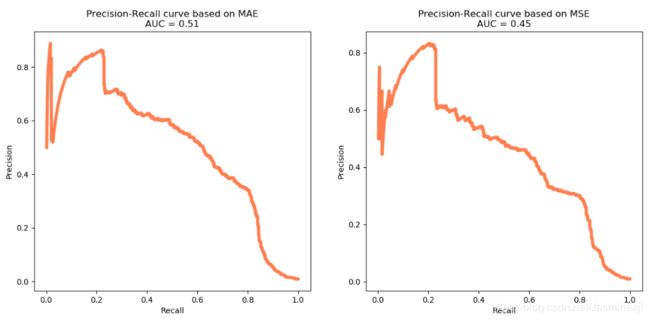
fig4_:相应的Precision-Recall曲线
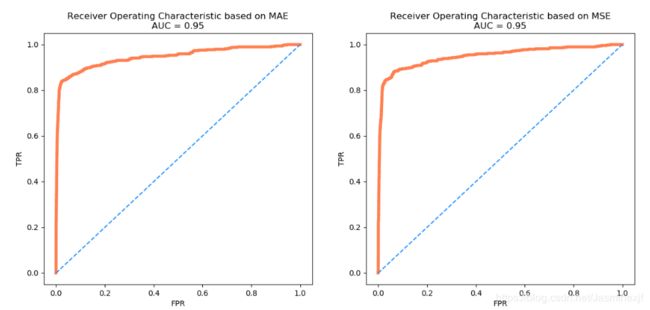
fig_5:ROC_AUC曲线
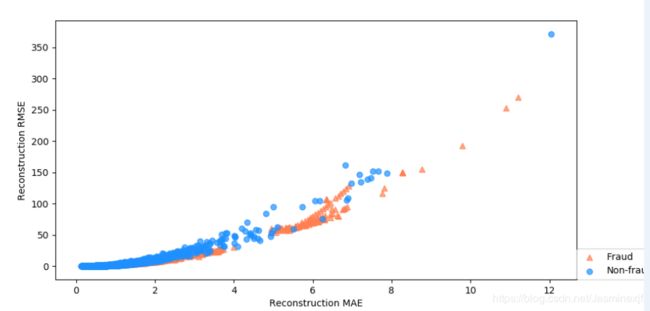
fig6_:MSE、MAE散点图

processed.py:
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
def read_file(dataname):
# read data
d = pd.read_csv(dataname)
# 查看样本比例
num_nonfraud = np.sum(d['Class'] == 0) # 0类样本表示非欺诈样本,是正常样本数据,该数据集中有284315条数据,占比较大。
num_fraud = np.sum(d['Class'] == 1) # 1类样本表示欺诈样本,是属于异常检测中的异常样本,该数据集中仅有492条数据,比例很小。
plt.bar(['fraud', 'non_fraud'], [num_fraud, num_nonfraud], color='dodgerblue')
plt.show()
# 删除时间列,并对amount列进行标准化
data = d.drop(['Time'], axis=1)
data['Amount'] = StandardScaler().fit_transform(data[['Amount']])
# 提取负样本(正常数据;label:0),并且按照8:2的比例切分成训练集合测试集。
mask = (data['Class'] == 0)
X_train, X_test = train_test_split(data[mask], test_size=0.2, random_state=920)
X_train = X_train.drop(['Class'], axis=1).values
X_test = X_test.drop(['Class'], axis=1).values
# 提取所有正样本(异常数据,label:1),作为测试集的一部分
X_fraud = data[~mask].drop(['Class'], axis=1).values
return X_train, X_test, X_fraud
auto_model.py:
from processed import read_file
import tensorflow as tf
from keras.models import Model
from keras.layers import Input, Dense
from keras.callbacks import ModelCheckpoint
from keras import regularizers
import matplotlib.pyplot as plt
from numpy.random import seed
seed(1)
dataname = './SofaSofa_Anomaly.csv'
X_train, X_test, X_fraud = read_file(dataname)
# 设置autoencoder的参数: 隐藏层参数设置:16,8,8,16; epoch_size为50;batch_size 为32
input_dim = X_train.shape[1]
encoding_dim = 16
num_epoch = 50
batch_size = 32
# 利用keras构建模型
input_layer = Input(shape=(input_dim,))
encoder = Dense(encoding_dim, activation="tanh",
activity_regularizer=regularizers.l1(10e-5))(input_layer)
encoder = Dense(int(encoding_dim/2), activation="relu")(encoder)
decoder = Dense(int(encoding_dim/2), activation="tanh")(encoder)
decoder = Dense(input_dim, activation="relu")(decoder)
autoencoder = Model(inputs=input_layer,outputs=decoder)
autoencoder.compile(optimizer="adam",
loss="mean_squared_error",
metrics=['mae']) # 评价函数和 损失函数 相似,只不过评价函数的结果不会用于训练过程中
# 将模型保存为sofasofa_model.h5,并开始训练。
checkpointer = ModelCheckpoint(filepath="sofasofa_model.h5",
verbose=0,
save_best_only=True)
history = autoencoder.fit(X_train, X_train,
epochs=num_epoch,
batch_size=batch_size,
shuffle=True,
validation_data=(X_test, X_test),
verbose=1,
callbacks=[checkpointer]).history
# 画出损失函数曲线
plt.figure(figsize=(14,5))
plt.subplot(121)
plt.plot(history["loss"], c='dodgerblue', lw=3)
plt.plot(history["val_loss"], c='coral', lw=3)
plt.title('model loss')
plt.ylabel('mse'); plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper right')
plt.subplot(122)
plt.plot(history['mean_absolute_error'], c='dodgerblue', lw=3)
plt.plot(history['val_mean_absolute_error'], c='coral', lw=3)
plt.title('model_mae')
plt.ylabel('mae');plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper right')
plt.show()auto_test.py:
from processed import read_file
from keras.models import load_model
from sklearn.metrics import roc_curve, auc, precision_recall_curve
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from numpy.random import seed
seed(1)
dataname = './SofaSofa_Anomaly.csv'
X_train, X_test, X_fraud = read_file(dataname)
# 读取模型
autoencoder = load_model('sofasofa_model.h5')
# 利用训练好的autoencoder重建测试集(X_test;X_fraud 前者是正常样本,后者是所有的异常样本)
pred_test = autoencoder.predict(X_test)
pred_fraud = autoencoder.predict(X_fraud)
# 计算还原误差MSE和MAE ;前者是loss;后者是metrics的mae
mse_test = np.mean(np.power(X_test - pred_test, 2), axis=1)
mse_fraud = np.mean(np.power(X_fraud - pred_fraud, 2), axis=1)
mae_test = np.mean(np.abs(X_test - pred_test), axis=1)
mae_fraud = np.mean(np.abs(X_fraud - pred_fraud), axis=1)
mse_df = pd.DataFrame()
mse_df['Class'] = [0]*len(mse_test) + [1]*len(mse_fraud)
mse_df['MSE'] = np.hstack([mse_test, mse_fraud])
mse_df['MAE'] = np.hstack([mae_test, mae_fraud])
mse_df = mse_df.sample(frac=1).reset_index(drop=True)
"""
sample()参数frac是要返回的比例,比如df中有10行数据,我只想返回其中的30%,那么frac=0.3
set_index()和reset_oindex()的区别 前者为现有的dataframe设置不同于之前的index;而后者是还原和最初的index方式:0,1,2,3,4……
"""
# 分别画出测试集中正样本和负样本的还原误差MAE和MSE
markers = ['o', '^']
colors = ['dodgerblue', 'coral']
labels = ['Non-fraud', 'Fraud']
plt.figure(figsize=(14, 5))
plt.subplot(121)
for flag in [1, 0]:
temp = mse_df[mse_df['Class'] == flag]
plt.scatter(temp.index,
temp['MAE'],
alpha=0.7,
marker=markers[flag],
c=colors[flag],
label=labels[flag])
plt.title('Reconstruction MAE')
plt.ylabel('Reconstruction MAE'); plt.xlabel('Index')
plt.subplot(122)
for flag in [1, 0]:
temp = mse_df[mse_df['Class'] == flag]
plt.scatter(temp.index,
temp['MSE'],
alpha=0.7,
marker=markers[flag],
c=colors[flag],
label=labels[flag])
plt.legend(loc=[1, 0], fontsize=12); plt.title('Reconstruction MSE')
plt.ylabel('Reconstruction MSE'); plt.xlabel('Index')
plt.show()
# 画出Precision-Recall曲线
plt.figure(figsize=(14, 6))
for i, metric in enumerate(['MAE', 'MSE']):
plt.subplot(1, 2, i+1)
precision, recall, _ = precision_recall_curve(mse_df['Class'], mse_df[metric])
pr_auc = auc(recall, precision)
plt.title('Precision-Recall curve based on %s\nAUC = %0.2f'%(metric, pr_auc))
plt.plot(recall[:-2], precision[:-2], c='coral', lw=4)
plt.xlabel('Recall'); plt.ylabel('Precision')
plt.show()
# 画出ROC曲线
plt.figure(figsize=(14, 6))
for i, metric in enumerate(['MAE', 'MSE']):
plt.subplot(1, 2, i+1)
fpr, tpr, _ = roc_curve(mse_df['Class'],mse_df[metric])
roc_auc = auc(fpr, tpr)
plt.title('Receiver Operating Characteristic based on %s\nAUC = %0.2f'%(metric, roc_auc))
plt.plot(fpr, tpr, c='coral', lw=4)
plt.plot([0, 1], [0, 1], c='dodgerblue', ls='--')
plt.ylabel('TPR');plt.xlabel('FPR')
plt.show()
# 画出MSE、MAE散点图
markers = ['o', '^']
colors = ['dodgerblue', 'coral']
labels = ['Non-fraud', 'Fraud']
plt.figure(figsize=(10, 5))
for flag in [1, 0]:
temp = mse_df[mse_df['Class'] == flag]
plt.scatter(temp['MAE'],
temp['MSE'],
alpha=0.7,
marker=markers[flag],
c=colors[flag],
label=labels[flag])
plt.legend(loc=[1, 0])
plt.ylabel('Reconstruction RMSE'); plt.xlabel('Reconstruction MAE')
plt.show()
fig_1 to fig_6:

最近发现一个利用VAE和PCA的方法对异常点检测改进算法的翻译:基于VAE的异常点检测算法