import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import scala.collection.mutable.ArrayBuffer
import scala.util.Random
object Kmeans2 {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
val sparkSession = SparkSession.builder().master("local[4]").appName("Kmeans").getOrCreate()
val sc = sparkSession.sparkContext
val data = sc.textFile("G:\\mldata\\watermelon 4.0.txt").map(line => line.split(',')).map(arr => (Row(arr(0).toInt,arr(1).toDouble,arr(2).toDouble)))
val schema = StructType(List(StructField("Label",IntegerType,true),StructField("density",DoubleType,true),StructField("sugarContent",DoubleType,true)))
val featuresArr = Array("density","sugarContent")
val df = sparkSession.sqlContext.createDataFrame(data,schema)
val vectorAssmeb = new VectorAssembler().setInputCols(featuresArr).setOutputCol("features")
val newdf = vectorAssmeb.transform(df).select("Label","features")
val K_number = 3
val iteratorMax = 10000
val result = k(newdf,K_number,iteratorMax)
for(i<-0 until K_number){
println("第" + i +"簇聚类结果:" )
result(i).foreach(println(_))
}
}
def cal(data:Vector[Double],meanVectors:Array[Vector[Double]]):(Double,Int) ={
val disArr = ArrayBuffer[(Double,Int)]()
for(i<- 0 until meanVectors.length){
var dis = 0.0
for(j<-0 until data.length){
dis += math.pow((data(j) - meanVectors(i)(j)),2)
}
disArr.append((dis,i))
}
val leastdis = disArr.sortBy(tuple => tuple._1).take(1)(0)
leastdis
}
def reflash(Ck:ArrayBuffer[Vector[Double]],meanVector:Vector[Double],dimentions:Int)={
val dimentionsArr = ArrayBuffer[Double]()
for(i<-0 until dimentions) dimentionsArr.append(0.0)
for(i<-0 until meanVector.length) {
for(j<-0 until Ck.length){
dimentionsArr(i) += Ck(j)(i)
}
}
for(i<-0 until dimentionsArr.length) dimentionsArr(i) = dimentionsArr(i) / Ck.length
val newmeanVector = dimentionsArr.toVector
if(newmeanVector == meanVector) (meanVector,false) else (newmeanVector,true)
}
def k(df:DataFrame,K:Int,iteratorMax:Int)={
val trainData = df.select("features").rdd.map(row => row.toString())
.map(str => str.replace('[',' '))
.map(str => str.replace(']',' '))
.map(str => str.trim()).map(str => str.split(','))
.map(arr => arr.map(str => str.toDouble))
.collect()
val dimensions = trainData(0).length
val meanVectors = ArrayBuffer[Vector[Double]]()
val rn = ArrayBuffer[Int]()
var flag_mean = true
while(flag_mean){
val index = Random.nextInt(trainData.length-1)
if(!rn.contains(index)){
rn.append(index)
meanVectors.append(trainData(index).toVector)
}
if(meanVectors.length == K) flag_mean = false
}
val iniCk = new Array[ArrayBuffer[Vector[Double]]](K)
for(j<-0 until K){
iniCk(j) = ArrayBuffer(Vector(0.0))
iniCk(j).clear()
}
var iteratornum = -1
var flag = true
while(flag){
iteratornum += 1
for(i<-0 until trainData.length){
var flag2 = true
val leastdis = cal(trainData(i).toVector,meanVectors.toArray)
for(j<-0 until K if flag2){
if(leastdis._2 == j){
iniCk(j).append(trainData(i).toVector)
flag2 = false
}
}
}
val vectorArr = ArrayBuffer[(Vector[Double],Boolean)]()
for(i<-0 until meanVectors.length){
vectorArr.append(reflash(iniCk(i),meanVectors(i),dimensions))
}
for(i<-0 until meanVectors.length) meanVectors(i) = vectorArr(i)._1
val boolArr = ArrayBuffer[Boolean]()
for (bool<- vectorArr){
if(!bool._2) boolArr.append(bool._2)
}
if(boolArr.length == meanVectors.length || iteratornum > iteratorMax) flag = false else {
for(ci <- iniCk) ci.clear()
}
}
iniCk
}
}
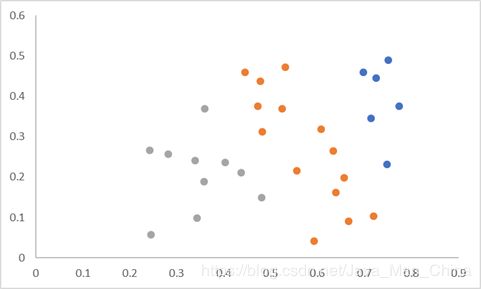
-------西瓜数据集结果-----------------------------------------------------------------------------
第0簇聚类结果:
Vector(0.697, 0.46)
Vector(0.774, 0.376)
Vector(0.748, 0.232)
Vector(0.714, 0.346)
Vector(0.751, 0.489)
Vector(0.725, 0.445)
第1簇聚类结果:
Vector(0.634, 0.264)
Vector(0.608, 0.318)
Vector(0.556, 0.215)
Vector(0.666, 0.091)
Vector(0.639, 0.161)
Vector(0.657, 0.198)
Vector(0.593, 0.042)
Vector(0.719, 0.103)
Vector(0.483, 0.312)
Vector(0.478, 0.437)
Vector(0.525, 0.369)
Vector(0.532, 0.472)
Vector(0.473, 0.376)
Vector(0.446, 0.459)
第2簇聚类结果:
Vector(0.403, 0.237)
Vector(0.481, 0.149)
Vector(0.437, 0.211)
Vector(0.243, 0.267)
Vector(0.245, 0.057)
Vector(0.343, 0.099)
Vector(0.36, 0.37)
Vector(0.359, 0.188)
Vector(0.339, 0.241)
Vector(0.282, 0.257)
-------鸢尾花数据集结果---------------------------------------------------------------------------------------------------------------------
第0簇聚类结果:
Vector(4.9, 3.0, 1.4, 0.2)
Vector(4.7, 3.2, 1.3, 0.2)
Vector(4.6, 3.1, 1.5, 0.2)
Vector(4.6, 3.4, 1.4, 0.3)
Vector(4.4, 2.9, 1.4, 0.2)
Vector(4.9, 3.1, 1.5, 0.1)
Vector(4.8, 3.4, 1.6, 0.2)
Vector(4.8, 3.0, 1.4, 0.1)
Vector(4.3, 3.0, 1.1, 0.1)
Vector(4.6, 3.6, 1.0, 0.2)
Vector(4.8, 3.4, 1.9, 0.2)
Vector(5.0, 3.0, 1.6, 0.2)
Vector(4.7, 3.2, 1.6, 0.2)
Vector(4.8, 3.1, 1.6, 0.2)
Vector(4.9, 3.1, 1.5, 0.1)
Vector(5.0, 3.2, 1.2, 0.2)
Vector(4.9, 3.1, 1.5, 0.1)
Vector(4.4, 3.0, 1.3, 0.2)
Vector(4.5, 2.3, 1.3, 0.3)
Vector(4.4, 3.2, 1.3, 0.2)
Vector(4.8, 3.0, 1.4, 0.3)
Vector(4.6, 3.2, 1.4, 0.2)
Vector(5.0, 3.3, 1.4, 0.2)
第1簇聚类结果:
Vector(5.1, 3.5, 1.4, 0.2)
Vector(5.0, 3.6, 1.4, 0.2)
Vector(5.4, 3.9, 1.7, 0.4)
Vector(5.0, 3.4, 1.5, 0.2)
Vector(5.4, 3.7, 1.5, 0.2)
Vector(5.8, 4.0, 1.2, 0.2)
Vector(5.7, 4.4, 1.5, 0.4)
Vector(5.4, 3.9, 1.3, 0.4)
Vector(5.1, 3.5, 1.4, 0.3)
Vector(5.7, 3.8, 1.7, 0.3)
Vector(5.1, 3.8, 1.5, 0.3)
Vector(5.4, 3.4, 1.7, 0.2)
Vector(5.1, 3.7, 1.5, 0.4)
Vector(5.1, 3.3, 1.7, 0.5)
Vector(5.0, 3.4, 1.6, 0.4)
Vector(5.2, 3.5, 1.5, 0.2)
Vector(5.2, 3.4, 1.4, 0.2)
Vector(5.4, 3.4, 1.5, 0.4)
Vector(5.2, 4.1, 1.5, 0.1)
Vector(5.5, 4.2, 1.4, 0.2)
Vector(5.5, 3.5, 1.3, 0.2)
Vector(5.1, 3.4, 1.5, 0.2)
Vector(5.0, 3.5, 1.3, 0.3)
Vector(5.0, 3.5, 1.6, 0.6)
Vector(5.1, 3.8, 1.9, 0.4)
Vector(5.1, 3.8, 1.6, 0.2)
Vector(5.3, 3.7, 1.5, 0.2)
第2簇聚类结果:
Vector(7.0, 3.2, 4.7, 1.4)
Vector(6.4, 3.2, 4.5, 1.5)
Vector(6.9, 3.1, 4.9, 1.5)
Vector(5.5, 2.3, 4.0, 1.3)
Vector(6.5, 2.8, 4.6, 1.5)
Vector(5.7, 2.8, 4.5, 1.3)
Vector(6.3, 3.3, 4.7, 1.6)
Vector(4.9, 2.4, 3.3, 1.0)
Vector(6.6, 2.9, 4.6, 1.3)
Vector(5.2, 2.7, 3.9, 1.4)
Vector(5.0, 2.0, 3.5, 1.0)
Vector(5.9, 3.0, 4.2, 1.5)
Vector(6.0, 2.2, 4.0, 1.0)
Vector(6.1, 2.9, 4.7, 1.4)
Vector(5.6, 2.9, 3.6, 1.3)
Vector(6.7, 3.1, 4.4, 1.4)
Vector(5.6, 3.0, 4.5, 1.5)
Vector(5.8, 2.7, 4.1, 1.0)
Vector(6.2, 2.2, 4.5, 1.5)
Vector(5.6, 2.5, 3.9, 1.1)
Vector(5.9, 3.2, 4.8, 1.8)
Vector(6.1, 2.8, 4.0, 1.3)
Vector(6.3, 2.5, 4.9, 1.5)
Vector(6.1, 2.8, 4.7, 1.2)
Vector(6.4, 2.9, 4.3, 1.3)
Vector(6.6, 3.0, 4.4, 1.4)
Vector(6.8, 2.8, 4.8, 1.4)
Vector(6.7, 3.0, 5.0, 1.7)
Vector(6.0, 2.9, 4.5, 1.5)
Vector(5.7, 2.6, 3.5, 1.0)
Vector(5.5, 2.4, 3.8, 1.1)
Vector(5.5, 2.4, 3.7, 1.0)
Vector(5.8, 2.7, 3.9, 1.2)
Vector(6.0, 2.7, 5.1, 1.6)
Vector(5.4, 3.0, 4.5, 1.5)
Vector(6.0, 3.4, 4.5, 1.6)
Vector(6.7, 3.1, 4.7, 1.5)
Vector(6.3, 2.3, 4.4, 1.3)
Vector(5.6, 3.0, 4.1, 1.3)
Vector(5.5, 2.5, 4.0, 1.3)
Vector(5.5, 2.6, 4.4, 1.2)
Vector(6.1, 3.0, 4.6, 1.4)
Vector(5.8, 2.6, 4.0, 1.2)
Vector(5.0, 2.3, 3.3, 1.0)
Vector(5.6, 2.7, 4.2, 1.3)
Vector(5.7, 3.0, 4.2, 1.2)
Vector(5.7, 2.9, 4.2, 1.3)
Vector(6.2, 2.9, 4.3, 1.3)
Vector(5.1, 2.5, 3.0, 1.1)
Vector(5.7, 2.8, 4.1, 1.3)
-------由于鸢尾花数据集特征列为4维,不方便作图,特选择西瓜数据集作图-------------------------------------------------