Zookeeper 介绍 Zookeeper 搭建 Zookeeper 集群搭建
关键字:分布式
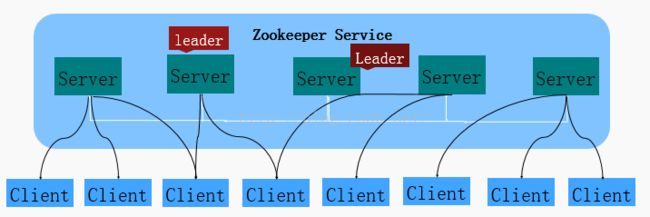

1. 集群角色
2. 数据发布与订阅
(自行安装jdk)
背景
随着互联网技术的高速发展,企业对计算机系统的技术、存储能力要求越来越高,最简单的证明就是出现了一些诸如:高并发、海量存储这样的词汇。在这样的背景 下,单纯依靠少量高性能主机来完成计算任务已经不能满足企业的要求,企业的IT架构逐步从集中式向分布式过渡,所谓的分布式是指:把一个计算任务分解成若干个计算单元,并且分派到若干不同的计算机中取执行,然后汇总计算结果的过程!
概念
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google Chubby的一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
Zookeeper是一个
分布式的服务协调组件
Zookeeper的基础
1. 文件系统
Zookeeper维护一个类似文件系统的数据结构
2. 通知机制
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。
Zookeeper可以说就是一个文件系统加通知机制
基本概念
Leader/Follower/Observer
Leader服务器是整个zk集群工作机制中的核心
Follower服务器是zk集群状态的跟随着
Observer服务器充当一个观察者的角色
Leader、Follower 设计模式
Observer 观察者模式

2. 会话
会话是指客户端和zk服务器的连接,zk中的会话叫session,客户端靠与服务器建立一个TCP的长连接来维持一个sessino,客户端在启动的时候首先会与服务器建立一个TCP连接,通过这个连接,客户端能够通过心跳检测与服务器保持有效的会话,也能向zk服务器发送请求并获得响应。
3. 数据节点
zk中的节点有两类
1. 集群中的一台机器称为一个节点
2. 数据模型中的数据单元Znode,分为持久节点(PERSISTENT )和临时节点(EPHEMERAL),具体在节点创建过程中,一般是组合使用,可以生成以下 4 种节点类型。
持久节点(PERSISTENT) 所谓持久节点,是指在节点创建后,就一直存在,直到有删除操作来主动清除这个节点——不会因为创建该节点的客户端会话失效而消失。
持久顺序节点(PERSISTENT_SEQUENTIAL) 这类节点的基本特性和上面的节点类型是一致的。额外的特性是,在ZK中,每个父节点会为他的第一级子节点维护一份时序,会记录每个子节点创建的先后顺序。基于这个特性,在创建子节点的时候,可以设置这个属性,那么在创建节点过程中,ZK会自动为给定节点名加上一个数字后缀,作为新的节点名。这个数字后缀的范围是整型的最大值。
临时节点(EPHEMERAL)和持久节点不同的是,临时节点的生命周期和客户端会话绑定。也就是说,如果客户端会话失效,那么这个节点就会自动被清除掉。注意,这里提到的是会话失效,而非连接断开。另外,在临时节点下面不能创建子节点。
临时顺序节点(EPHEMERAL_SEQUENTIAL),
参考持久顺序节点
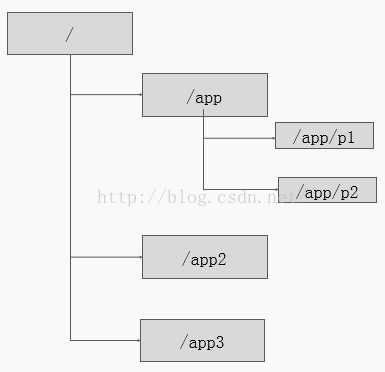
zk的数据模型是一棵树,树的节点就是Znode,Znode中可以保存信息(不同于文件系统的是,节点可以有自己的数据,而文件系统中的目录节点只有子节点),如下图
4. 版本
| 版本类型 |
说明
|
|
version
|
当前数据节点数据内容的版本号
|
|
cversion
|
当前数据节点子节点的版本号
|
|
aversion
|
当前数据节点ACL变更版本号
|
5. watcher
事件监听器
zk允许用户在指定节点上注册一些watcher,当数据发生变化的时候,zk服务器回把这个变化通知发送给感兴趣的客户端
可以参考:http://www.chepoo.com/zookeeper-watcher.htmln
6. ACL权限控制
ACL是Access Control Lists的简写,zk采用ACL策略来进行权限控制,有以下权限:
CREATE:创建子节点的权限
READ:获取节点数据和子节点列表的权限
WRITE:更新节点数据的权限
DELETE:删除子节点的权限
ADMIN:设置即诶但ACL的权限
使用场景
1. Leader 选举(Leader Election)
有一个向外提供的服务,服务必须7*24小时提供服务,不能有单点故障。所以采用集群的方式,采用master、slave的结构。一台主机多台备机。主机向外提供服务,备机负责监听主机的状态,一旦主机宕机,备机要迅速接代主机继续向外提供服务。
从备机选择一台作为主机,就是master选举。
当一个对象的改变,需要通知其他对象而且不知道要通知多少个对象,可以使用发布订阅模式 。在分布式中的应用有配置管理(Configuration Management) 、集群管理(Group Membership)/服务发现。
配置管理(Configuration Management)
故名思议就是一方把数据发布出来,另一方通过某种手段可以得到这些数据
集群管理(Group Membership)/服务发现
zk中我们所有的机器都注册一个临时节点,我们判断一个机器或者服务是否可用只需要判断这个节点在zk中是否存在就可以了,不需要直接去连接需要检查的机器,降低系统的复杂度。
3. 负载均衡
4. 分布式锁(Locks)
一般的锁是指单进程多线程的锁,在多线程并发编程中,用于线程之间的数据同步,保证共享资源的访问。而分布式锁,指的是在分布式环境下,保证跨进程、跨主机、跨网络的共享资源,实现互斥访问,保证一致性。
5. 分布式队列(Queues)
在传统的单进程编程中,我们使用队列来存储数据结构,用来在多线程之间共享或者传递数据。在分布式环境下,同样需要一个类似单进程的组件, 用来实现跨进程、跨主机、跨网络的数据共享和数据传递。这就是我们的分布式队列。Zookeeper可以通过顺序节点点来实现分布式队列。
6. 统一命名服务(Name Service)
命名服务就是提供名称的服务,Zookeeper的命名服务有两个应用方面。一个是提供类似JNDI功能,另一个是制作分布式的序列号生成器。
Zookeeper的安装和启动
下载
http://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz
链接:http://pan.baidu.com/s/1nvbCoE9 密码:15gh
安装启动
|
1
2
3
4
5
6
7
|
tar zxvf zookeeper-3.4.6.tar.gz
cd zookeeper-3.4.6
cd conf
mv zoo_sample.cfg zoo.cfg
cd ..
cd bin
./zkServer.sh start
|
创建、查询节点
输入:zkCli.sh
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 1] ls /zookeeper
[quota]
[zk: localhost:2181(CONNECTED) 2] create /rpc jerome
Created /rpc
[zk: localhost:2181(CONNECTED) 3] ls /
[zookeeper, rpc]
[zk: localhost:2181(CONNECTED) 4] ls /rpc
[]
[zk: localhost:2181(CONNECTED) 5] get /rpc
jerome
cZxid = 0x2
ctime = Fri Jul 15 01:50:00 PDT 2016
mZxid = 0x2
mtime = Fri Jul 15 01:50:00 PDT 2016
pZxid = 0x2
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 6
numChildren = 0
|
ZooKeeper 集群环境搭建
准备三台虚拟机,这里使用vm+centos 6.4
1. 安装JDK
2. 安装zk
参考上面
3. 配置zk集群
cd zookeeper-3.4.8/conf/
vim zoo.cfg
1. 修改dataDir存储块的路径:修改的路径记得创建目录,还要在配置的这个目录下面创建一个myid
vim myid,写1,就是下面的service.id ,其他两台分别为2、3
2. 新增服务器列表配置(三台配置一样,2888是Follower和leader通信的端口)
server.1 = 192.168.84.141:2888:3888
server.2 = 192.168.84.142:2888:3888
server.3 = 192.168.84.143:2888:3888
#启动zk(分别启动三台)
cd ../bin
./zkServer.sh start
4. 测试
验证是否启动成功,telnet 192.168.84.141 2181
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
[root@hadoop bin]# telnet 192.168.84.141 2181
Trying 192.168.84.141...
Connected to 192.168.84.141.
Escape character is '^]'.
stat
Zookeeper version: 3.4.6-1569965, built on 02/20/2014 09:09 GMT
Clients:
/192.168.84.141:35397[0](queued=0,recved=1,sent=0)
Latency min/avg/max: 0/0/0
Received: 2
Sent: 1
Connections: 1
Outstanding: 0
Zxid: 0x0
Mode: follower
Node count: 4
Connection closed by foreign host.
|
只要超过一半的服务器启动,就可以正常的向外服务。
把其他两台关掉,集群不可用
|
1
2
3
4
5
6
7
|
[root@hadoop bin]# telnet 192.168.84.141 2181
Trying 192.168.84.141...
Connected to 192.168.84.141.
Escape character is '^]'.
stat
This ZooKeeper instance is not currently serving requests
Connection closed by foreign host.
|
参考
极客学院视频【链接:http://pan.baidu.com/s/1qYKPNyO 密码:nlz3】