(译)神经网络基础(2):Softmax 分类函数
点击阅读原文
翻译: huangyongye
前言:本文在翻译过程中,为了便于理解,某些句子可能和原文有一定的出入。但是整体上没有太大的改动,由于本人水平有限,翻译或者理解不对的地方,欢迎指正,不胜感激。
Softmax 分类函数
本例子包括以下内容:
* softmax 函数
* 交叉熵(Cross-entropy) 损失函数
在上一个例子中,我们介绍了如何利用 logistic 函数来处理二分类问题。
对于多分类问题,在处理多项式 logistic 回归(multinomial logistic regression)中,用到 logistic 函数的一种扩展形式,叫做 softmax 函数。下面的内容将会介绍 softmax 函数及其求导方式。
首先,导入需要用到的 python 库函数。
# Python imports
import numpy as np # Matrix and vector computation package
import matplotlib.pyplot as plt # Plotting library
from matplotlib.colors import colorConverter, ListedColormap # some plotting functions
from mpl_toolkits.mplot3d import Axes3D # 3D plots
from matplotlib import cm # Colormaps
# Allow matplotlib to plot inside this notebook
%matplotlib inline1. Softmax 函数
在上个例子中,我们介绍了logistic 函数 ,但是它只能用于处理二分类问题 t=1 或者 t=0 。现在我们来介绍它的一个推广的形式, softmax 函数,在多分类问题中它能够输出每个类别的预测概率。 softamx 函数 ς 的输入是一个 C -维的向量 z ,输出也是一个 C -维的向量 y , y 的每个元素都是介于 0 和 1 的一个实数值。这个函数形式为归一化的指数函数,定义如下:
其中,分母 ∑Cd=1ezd 作为一个正则化矩阵,确保所有类别的概率值和为 1: ∑Cc=1yc=1 .
在神经网络中,softmax 函数一般作为最后的输出层,所以 softmax 函数可以图形化地表示为一个拥有 C 个节点的神经层。
对于给定输入 z ,我们可以按照下面的公式计算每个类别的概率:
对于给定的输入 z , P(t=c|z) 就是该样本预测属于类别 c 的概率。
以一个二分类问题为例:对于输入 z=[z1,z2] , 输出预测属于类别 1 的概率 P(t=1|z) 如下图所示。输出预测为另一个类别 P(t=2|z) 的概率值大小刚好和图中结果互补。
# Define the softmax function
def softmax(z):
return np.exp(z) / np.sum(np.exp(z))# Plot the softmax output for 2 dimensions for both classes
# Plot the output in function of the weights
# Define a vector of weights for which we want to plot the ooutput
nb_of_zs = 200
zs = np.linspace(-10, 10, num=nb_of_zs) # input
zs_1, zs_2 = np.meshgrid(zs, zs) # generate grid
y = np.zeros((nb_of_zs, nb_of_zs, 2)) # initialize output
# Fill the output matrix for each combination of input z's
for i in range(nb_of_zs):
for j in range(nb_of_zs):
y[i,j,:] = softmax(np.asarray([zs_1[i,j], zs_2[i,j]]))
# Plot the cost function surfaces for both classes
fig = plt.figure()
# Plot the cost function surface for t=1
ax = fig.gca(projection='3d')
surf = ax.plot_surface(zs_1, zs_2, y[:,:,0], linewidth=0, cmap=cm.coolwarm)
ax.view_init(elev=30, azim=70)
cbar = fig.colorbar(surf)
ax.set_xlabel('$z_1$', fontsize=15)
ax.set_ylabel('$z_2$', fontsize=15)
ax.set_zlabel('$y_1$', fontsize=15)
ax.set_title ('$P(t=1|\mathbf{z})$')
cbar.ax.set_ylabel('$P(t=1|\mathbf{z})$', fontsize=15)
plt.grid()
plt.show()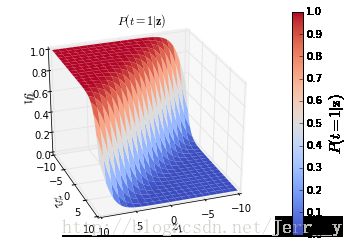
2. softmax 函数求导
为了在神经网络中使用 softmax 函数,我们需要对它进行求导。假设我们定义 ΣC=∑Cd=1ezd。forc=1⋯C ,预测属于类别 c 的概率值 yc=ezc/ΣC , 那么输出 y 对输入 z 的导数 ∂yi/∂zj 可以写成下面形式:
注意,若 i=j ,那么求导结果和 logistic 函数是一样的。
3. softmax 函数的交叉熵损失函数
首先我们看一下似然函数: 和 logistic 回归的损失函数一样,似然函数表示对于给定的模型参数集 θ ,模型能够正确预测输入样本的可能性。最大化似然函数可以写成下面的形式:
根据似然函数的定义, L(θ|t,z) 可以写成联合概率 的方式,在给定参数 θ 时,模型产生 t 和 z 的概率: P(t,z|θ) . Since P(A,B)=P(A|B)∗P(B) ,这个又可以写成下面形式:
由于我们并不需要关心 z 的概率,上式可以简化为:
L(θ|t,z)=P(t|z,θ) . 所以对于给定的 θ ,可以写成 P(t|z) .
由于每个样本的类别 ti 都是和整个输入 z 相关的,而且 t 中有且只有一个类别会激活该函数,所以可以将上面的概率函数写成下面的形式:
译者注:原文没有提到,但是我认为作者说的只有一个类别会激活 cross-entropy 损失函数的意思是指, t 是一个 one-hot 向量,只有真实类别所对应的那个元素取值为1, 其他元素取值为0。
和之前在 logistic 函数中提到的那样,最大化似然函数等价于最小化负的对数似然函数:
译者注:原文中的交叉熵损失函数的公式和我上面写的是不一样的,原文中是这样:
−logL(θ|t,z)=ξ(t,z)=−log∏i=cCytcc=−∑i=cCtc⋅log(yc)
但我不太理解下面从 i=c 开始是什么意思。我认为应该是我上面写的 类别 c 从 1 到 C ,不知道是作者笔误还是我理解错了。
这就是我们所说的交叉熵损失函数 ξ .
对于二分类问题 t2=1−t1 ,这个结果和之前在 logistic 回归中的损失函数是一样的:
那么对于一批数量为 n 的样本集,交叉熵损失函数计算如下:
其中当样本 i 属于类别 c 的时候, tic 取值为 1(否则为0)。 yic 表示对于输入样本 i ,模型输出属于类别 c 的概率大小。
4. softmax 函数的交叉熵损失函数求导
损失函数对 softmax 函数的输入 zi 进行求导: ∂ξ/∂zi ,推导如下:
译者注:注意下标的含义,在上面我们用 i 表示第 i 个样本,用 c 表示类别。但是这里下标 j 表示预测的类别, i 表示样本的真实类别。
注意,前面我们已经推导过 ∂yj/∂zi for i=j and i≠j .
从上面结果可以看出,和 logistic 回归中一样,交叉熵损失函数对所有类别 i∈C 的样本求导结果都是一样的: ∂ξ/∂zi=yi−ti 。
This post at peterroelants.github.io is generated from an IPython notebook file. Link to the full IPython notebook file