python调用中科院分词器进行中文分词
python调用中科院分词器进行中文分词之前一直使用python自带的jieba分词来进行中文分词,但是慢慢感觉分词效果不是很好,所以想用中科院的分词器进行分词。先看一下jieba分词效果
import jieba
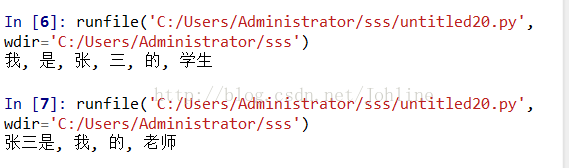
str1='张三是我的老师'
str2='我是张三的学生'
seg_list1=jieba.cut(str1)
seg_list2=jieba.cut(str2)
print( ", ".join(seg_list1))
print( ", ".join(seg_list2))结果:
结巴分词详细用法参考:jieba分词快速入门、结巴分词学习大全、结巴分词词性标注
用python调用中科院分词器
参考博客:http://blog.csdn.net/hongliryan/article/details/54577670
NLPIR汉语分词系统(又名ICTCLAS2013),主要功能包括中文分词;词性标注;命名实体识别;用户词典功能;支持GBK编码、UTF8编码、BIG5编码。新增微博分词、新词发现与关键词提取;张华平博士先后倾力打造十余年,内核升级10次。官网地址
首先 在cmd 中运行命令:pip install pynlpir进行下载
下载之后进行测试
import pynlpir
pynlpir.open()
str = '张三是我的老师'
print(pynlpir.segment(str))
print(pynlpir.segment(str, pos_english=False)) # 把词性标注语言变更为汉语
print(pynlpir.segment(str, pos_tagging=False)) # 使用pos_tagging来关闭词性标注参考该博客:http://blog.csdn.net/fontthrone/article/details/72692691
该博客说是你的NLPIR授权过期了,这个时候需要到github的license地址下载新的NLPIR.user
然后覆盖DATA文件夹中的原文件(NLPIR.user)即可。
如果不知道pynlpir安装地址在哪,可以在cmd里运行pip install pynlpir,然后出现

可是再次运行又出现了错误:
NLPIR RuntimeError: NLPIR function 'NLPIR_Init' failed
参考博客:http://blog.csdn.net/glory1234work2115/article/details/54144013
上面解决方案还是说授权过期需要下载新的NLPIR.user,但是已经下载过了,然后我将SPyder重新打开结果就好了,这说明下载下载新的文件后一定要重新启动项目才能运行。
运行结果:
