DensePose论文笔记(实现实时的人体姿态估计)
一:背景知识
姿态估计的目标是在RGB图像或视频中描绘出人体的形状,这是一种多方面任务,其中包含了目标检测、姿态估计、分割等等。有些需要在非水平表面进行定位的应用可能也会用到姿态估计,例如图形、增强现实或者人机交互。姿态估计同样包含许多基于3D物体的辨认。DensePose用深度学习把2D图像坐标映射到3D人体表面上,再加上以每秒多帧的速度处理密集坐标,最后实现动态人物的精确定位和姿态估计。该技术集目标检测、姿态估计、目标部分/实例分割等多种计算机视觉任务于一身的一个综合问题。未来可以把此技术应用于AR、VR、人机交互等一系列现实场景,对于我们理解3D物理模型开辟了一条新道路。
论文地址:https://arxiv.org/abs/1802.00434
项目地址:http://densepose.org
GitHub地址:https://github.com/facebookresearch/Densepose
二:研究方法
DenseReg(DenseReg: Fully Convolutional Dense Shape Regression In-the-Wild. CVPR 2017)
在这篇文章中,他们提出通过完全卷积学习从图像像素到密集模板网格的映射。将此任务作为一个回归问题,并利用手动注释的面部标注来训练我们的网络。使用这样的标注,在三维对象模板和输入图像之间,建立密集的对应领域,然后作为训练的回归系统的基础。论文指出可以将来自语义分割的想法与回归网络相结合,产生高精度的“量化回归”架构。
Mask R-CNN(https://arxiv.org/abs/1703.06870)
Mask R-CNN 是一个两阶段的框架,第一个阶段扫描图像并生成提议(proposals,即有可能包含一个目标的区域),第二阶段分类提议并生成边界框和掩码。Mask R-CNN 扩展自 Faster R-CNN,仍由何凯明和Ross提出。Faster R-CNN 是一个流行的目标检测框架,Mask R-CNN 将其扩展为实例分割框架。
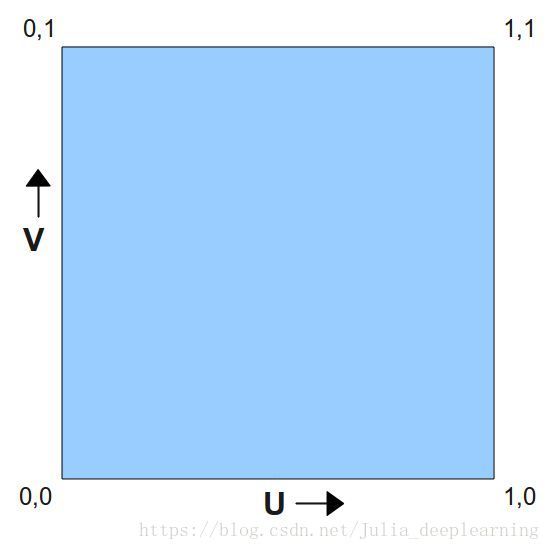
UV纹理贴图坐标
对于三维模型,有两个最重要的坐标系统,一是顶点的位置(X,Y,Z)坐标,另一个就是UV坐标。U和V分别是图片在显示器水平、垂直方向上的坐标,取值一般都是0~1,也 就是(水平方向的第U个像素/图片宽度,垂直方向的第V个像素/图片高度。纹理映射是把图片(或者说是纹理)映射到3D模型的一个或者多个面上。纹理可以是任何图片,使用纹理映射可以增加3D物体的真实感。每个片元(像素)都有一个对应的纹理坐标。由于三维物体表面有大有小是变化的,这意味着我们要不断更新纹理坐标。但是这在现实中很难做到。于是设定了纹理坐标空间,每维的纹理坐标范围都在[0,1]中,利用纹理坐标乘以纹理的高度或宽度就可以得到顶点在纹理上对应的纹理单元位置。纹理空间又叫UV空间。对于顶点来说,纹理坐标相对位置不变。
三:数据集介绍
COCO-Densepose-dataset
从数据库MSCOCO里面,挑选了50K个人,手动标注了近5百万的标注点。Test测试集“1.5k images,2.3k humans”,Training训练集“48k humans”。传统标注是找到图像上的一个点,然后旋转图像和立体模型来实现精确坐标定位,但这样做效率太过低下。因此他们把标记工作分成两个阶段:先进行宏观的部位分割,再进行具体的对应注释。他们用一组大致等距的点对每个身体部位区域进行采样。
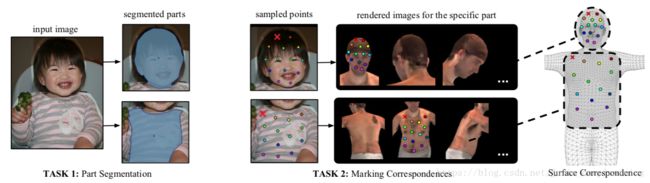 上图在任何渲染的部位图像上为每个被采样的点定位其对应的表面点,他们标注了图像和 3D 表面模型的密集对应关系。红色叉号表示当前被标注的点。
上图在任何渲染的部位图像上为每个被采样的点定位其对应的表面点,他们标注了图像和 3D 表面模型的密集对应关系。红色叉号表示当前被标注的点。
他们向标注者提供了人体部位的 6 个预渲染的视角,这样整个部位表面都是可见的。一旦标注了目标点,该点就会同时显示在所有渲染过的图像上如下图。

标注上了UV坐标之后,可以将一个3D人物的表面经过变换投影到2D图像上,并且会根据2D图像中人物的姿态做适当的变换,从而使得3D模型的表面可以做到紧贴2D人物。
四:网络结构
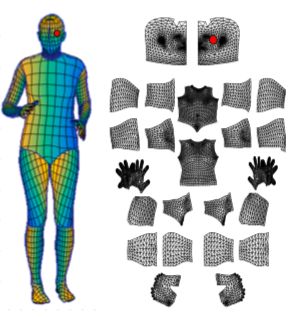
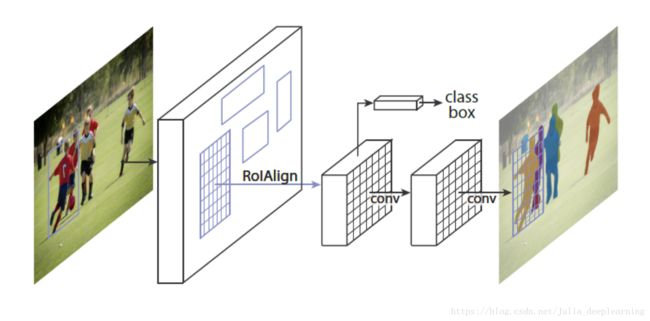
上图通过划分身体部位来对应回标注的等距点,对于每个像素,去确定它在贴图上的位置,并进行二维校正。

基于caffe2框架,研究团队采用的是金字塔网络(FPN)特征的RCNN结构,和区域特征聚集方式ROI align pooling以获得每个选定区域内的密集部分标签和坐标。将2D图像中人的表面的像素投影到3D人体表面上,也可以在估计出图像中人体的UV之后,将3Dmodel通过变换,将空间坐标转换为UV坐标之后,贴到图像上。输出三个内容 :身体部位分割,U 和 V。DensePose-RCNN系统可以直接使用标注点作为监督。它借用了Mask-RCNN的架构,同时带有Feature Pyramid Network(FPN)的特征,以及ROI-Align池化。除此之外,他们在ROI池化的顶层搭建了一个全卷积网络。

如上图,同时他们利用了多任务的Multi-task cascaded architectures结构,将 mask 和 keypoint的输出特征 与 densepose 的特征互相融合训练。而且也可以看出来使用了多stage的思想,进行“中继监督”训练,利用了任务协同作用和不同监督来源的互补优势。通过级联进一步提升了准确度。
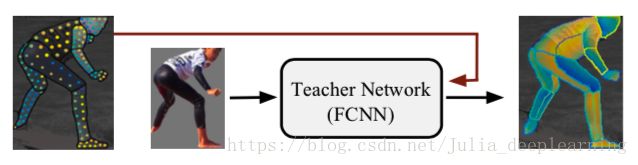
这里“teacher net” (如上图所示)对整体进行辅助训练,它是一个完全卷积神经网络(FCNN),在给定图像尺度把图像和分割蒙版统一化。他们首先使用稀疏的、人工收集的监督信号训练一个“teacher net” ,然后使用该网络来修补用于训练我们的基于区域的系统的密集监督信号。
五:模型的评测标准
该评测使用GPS(geodesic point similarity)作为度量,使用AP(Average Precision)和AR(Average Recall)作为标准。
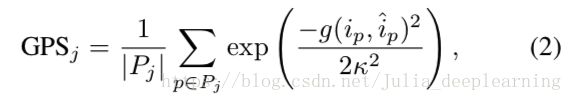
GPS:(1)计算预测的关键点与标签数据的关键点中距离最近的一对点。
(2)计算这对点的距离。
六:实验结果
左输入,右输出。