【论文复现】使用fastText进行文本分类
写在前面
今天是补笔记的一天。。。
今天的论文是来自Facebook AI Research的Bag of Tricks for Efficient Text Classification
也就是我们常用的fastText
最让人欣喜的这篇论文配套提供了fasttext工具包。这个工具包代码质量非常高,论文结果一键还原,目前已经是包装地非常专业了,这是fastText官网和其github代码库,以及提供了python接口,可以直接通过pip安装。这样准确率高又快的模型绝对是实战利器。
为了更好地理解fasttext原理,直接复现了一遍,但是代码中紧紧实现了最简单的基于单词的词向量求平均,并未使用b-gram的词向量,所以自己实现的文本分类效果会低于facebook开源的库:https://github.com/KaiyuanGao/text_claasification/tree/master/fastText
论文概览
We can train fastText on more than one billion words in less than ten minutes using a standard multicore CPU, and classify half a million sentences among 312K classes in less than a minute.
首先引用论文中的一段话来看看作者们是怎么评价fasttext模型的表现的。
这篇论文的模型非常之简单,之前了解过word2vec的同学可以发现这跟CBOW的模型框架非常相似。
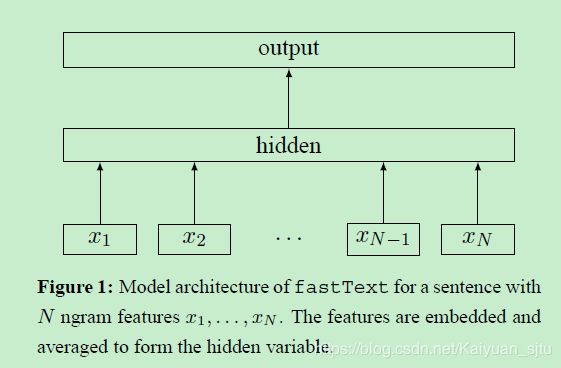
对应上面这个模型,比如输入是一句话,x1到xn就是这句话的单词或者是n-gram。每一个都对应一个向量,然后对这些向量取平均就得到了文本向量,然后用这个平均向量取预测标签。当类别不多的时候,就是最简单的softmax;当标签数量巨大的时候,就要用到hierarchical softmax了。
模型真的很简单,也没什么可以说的了。下面提一下论文中的两个tricks:
- hierarchical softmax
- 类别数较多时,通过构建一个霍夫曼编码树来加速softmax layer的计算,和之前word2vec中的trick相同
- N-gram features
- 只用unigram的话会丢掉word order信息,所以通过加入N-gram features进行补充
- 用hashing来减少N-gram的存储
模型表现
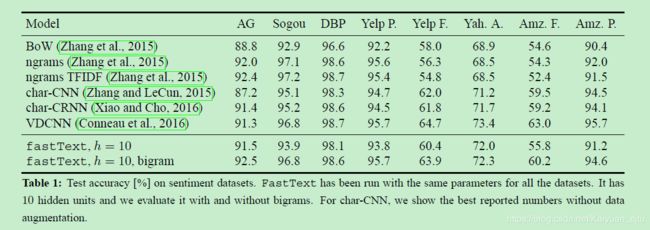
来看一下fasttext的试验结果,如此简单的模型竟然能取得这么好的效果 !
但是也有人指出论文中选取的数据集都是对句子词序不是很敏感的数据集,所以得到文中的试验结果并不奇怪。
总结
这篇论文在模型创新方面明显新意不足。首先网络结构照搬Word2vec,只是把单词换成了label。其他的一些创新也在之前的工作中有人做过了。但是fasttext依然产生了巨大的影响,我觉得最主要的就是其良心开源代码,在github上收到超高的人气。
代码实现
我觉得当时可能直接去读他们开源的代码会比较好.....
class fastTextModel(BaseModel):
"""
A simple implementation of fasttext for text classification
"""
def __init__(self, sequence_length, num_classes, vocab_size,
embedding_size, learning_rate, decay_steps, decay_rate,
l2_reg_lambda, is_training=True,
initializer=tf.random_normal_initializer(stddev=0.1)):
self.vocab_size = vocab_size
self.embedding_size = embedding_size
self.num_classes = num_classes
self.sequence_length = sequence_length
self.learning_rate = learning_rate
self.decay_steps = decay_steps
self.decay_rate = decay_rate
self.is_training = is_training
self.l2_reg_lambda = l2_reg_lambda
self.initializer = initializer
self.input_x = tf.placeholder(tf.int32, [None, self.sequence_length], name='input_x')
self.input_y = tf.placeholder(tf.int32, [None, self.num_classes], name='input_y')
self.global_step = tf.Variable(0, trainable=False, name='global_step')
self.instantiate_weight()
self.logits = self.inference()
self.loss_val = self.loss()
self.train_op = self.train()
self.predictions = tf.argmax(self.logits, axis=1, name='predictions')
correct_prediction = tf.equal(self.predictions, tf.argmax(self.input_y, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_prediction, 'float'), name='accuracy')
def instantiate_weight(self):
with tf.name_scope('weights'):
self.Embedding = tf.get_variable('Embedding', shape=[self.vocab_size, self.embedding_size],
initializer=self.initializer)
self.W_projection = tf.get_variable('W_projection', shape=[self.embedding_size, self.num_classes],
initializer=self.initializer)
self.b_projection = tf.get_variable('b_projection', shape=[self.num_classes])
def inference(self):
"""
1. word embedding
2. average embedding
3. linear classifier
:return:
"""
# embedding layer
with tf.name_scope('embedding'):
words_embedding = tf.nn.embedding_lookup(self.Embedding, self.input_x)
self.average_embedding = tf.reduce_mean(words_embedding, axis=1)
logits = tf.matmul(self.average_embedding, self.W_projection) +self.b_projection
return logits
def loss(self):
# loss
with tf.name_scope('loss'):
losses = tf.nn.softmax_cross_entropy_with_logits(labels=self.input_y, logits=self.logits)
data_loss = tf.reduce_mean(losses)
l2_loss = tf.add_n([tf.nn.l2_loss(cand_var) for cand_var in tf.trainable_variables()
if 'bias' not in cand_var.name]) * self.l2_reg_lambda
data_loss += l2_loss * self.l2_reg_lambda
return data_loss
def train(self):
with tf.name_scope('train'):
learning_rate = tf.train.exponential_decay(self.learning_rate, self.global_step,
self.decay_steps, self.decay_rate,
staircase=True)
train_op = tf.contrib.layers.optimize_loss(self.loss_val, global_step=self.global_step,
learning_rate=learning_rate, optimizer='Adam')
return train_opimport tensorflow as tf
import numpy as np
import os
import time
import datetime
from cnn_classification import data_process
from fastText import fastTextModel
from tensorflow.contrib import learn
# define parameters
#data load params
tf.flags.DEFINE_string("positive_data_file", "../cnn_classification/data/rt-polarity.pos", "Data source for the positive data.")
tf.flags.DEFINE_string("negative_data_file", "../cnn_classification/data/rt-polarity.neg", "Data source for the negative data.")
#configuration
tf.flags.DEFINE_float("learning_rate", 0.01, "learning rate")
tf.flags.DEFINE_integer("num_epochs", 60, "embedding size")
tf.flags.DEFINE_integer("batch_size", 100, "Batch size for training/evaluating.") #批处理的大小 32-->128
tf.flags.DEFINE_integer("decay_steps", 12000, "how many steps before decay learning rate.")
tf.flags.DEFINE_float("decay_rate", 0.9, "Rate of decay for learning rate.") # 0.5一次衰减多少
tf.flags.DEFINE_string("ckpt_dir", "text_fastText_checkpoint/", "checkpoint location for the model")
tf.flags.DEFINE_integer('num_checkpoints', 10, 'save checkpoints count')
tf.flags.DEFINE_integer("sequence_length", 300, "max sentence length")
tf.flags.DEFINE_integer("embedding_size", 128, "embedding size")
tf.flags.DEFINE_boolean("is_training", True, "is traning.true:tranining,false:testing/inference")
tf.flags.DEFINE_integer("validate_every", 1, "Validate every validate_every epochs.") #每10轮做一次验证
tf.flags.DEFINE_float("dev_sample_percentage", .1, "Percentage of the training data to use for validation")
tf.flags.DEFINE_integer('dev_sample_max_cnt', 1000, 'max cnt of validation samples, dev samples cnt too large will case high loader')
tf.flags.DEFINE_float("dropout_keep_prob", 0.5, "Dropout keep probability (default: 0.5)")
tf.flags.DEFINE_float("l2_reg_lambda", 0.0001, "L2 regularization lambda (default: 0.0)")
tf.flags.DEFINE_boolean("allow_soft_placement", True, "Allow device soft device placement")
tf.flags.DEFINE_boolean("log_device_placement", False, "Log placement of ops on devices")
FLAGS = tf.flags.FLAGS
def prepocess():
"""
For load and process data
:return:
"""
print("Loading data...")
x_text, y = data_process.load_data_and_labels(FLAGS.positive_data_file, FLAGS.negative_data_file)
# bulid vocabulary
max_document_length = max(len(x.split(' ')) for x in x_text)
vocab_processor = learn.preprocessing.VocabularyProcessor(max_document_length)
x = np.array(list(vocab_processor.fit_transform(x_text)))
# shuffle
np.random.seed(10)
shuffle_indices = np.random.permutation(np.arange(len(y)))
x_shuffled = x[shuffle_indices]
y_shuffled = y[shuffle_indices]
# split train/test dataset
dev_sample_index = -1 * int(FLAGS.dev_sample_percentage * float(len(y)))
x_train, x_dev = x_shuffled[:dev_sample_index], x_shuffled[dev_sample_index:]
y_train, y_dev = y_shuffled[:dev_sample_index], y_shuffled[dev_sample_index:]
del x, y, x_shuffled, y_shuffled
print('Vocabulary Size: {:d}'.format(len(vocab_processor.vocabulary_)))
print('Train/Dev split: {:d}/{:d}'.format(len(y_train), len(y_dev)))
return x_train, y_train, vocab_processor, x_dev, y_dev
def train(x_train, y_train, vocab_processor, x_dev, y_dev):
with tf.Graph().as_default():
session_conf = tf.ConfigProto(
# allows TensorFlow to fall back on a device with a certain operation implemented
allow_soft_placement= FLAGS.allow_soft_placement,
# allows TensorFlow log on which devices (CPU or GPU) it places operations
log_device_placement=FLAGS.log_device_placement
)
sess = tf.Session(config=session_conf)
with sess.as_default():
# initialize cnn
fasttext = fastTextModel(sequence_length=x_train.shape[1],
num_classes=y_train.shape[1],
vocab_size=len(vocab_processor.vocabulary_),
embedding_size=FLAGS.embedding_size,
l2_reg_lambda=FLAGS.l2_reg_lambda,
is_training=True,
learning_rate=FLAGS.learning_rate,
decay_steps=FLAGS.decay_steps,
decay_rate=FLAGS.decay_rate
)
# output dir for models and summaries
timestamp = str(time.time())
out_dir = os.path.abspath(os.path.join(os.path.curdir, 'run', timestamp))
if not os.path.exists(out_dir):
os.makedirs(out_dir)
print('Writing to {} \n'.format(out_dir))
# checkpoint dir. checkpointing – saving the parameters of your model to restore them later on.
checkpoint_dir = os.path.abspath(os.path.join(out_dir, FLAGS.ckpt_dir))
checkpoint_prefix = os.path.join(checkpoint_dir, 'model')
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
saver = tf.train.Saver(tf.global_variables(), max_to_keep=FLAGS.num_checkpoints)
# Write vocabulary
vocab_processor.save(os.path.join(out_dir, 'vocab'))
# Initialize all
sess.run(tf.global_variables_initializer())
def train_step(x_batch, y_batch):
"""
A single training step
:param x_batch:
:param y_batch:
:return:
"""
feed_dict = {
fasttext.input_x: x_batch,
fasttext.input_y: y_batch,
}
_, step, loss, accuracy = sess.run(
[fasttext.train_op, fasttext.global_step, fasttext.loss_val, fasttext.accuracy],
feed_dict=feed_dict
)
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
def dev_step(x_batch, y_batch):
"""
Evaluate model on a dev set
Disable dropout
:param x_batch:
:param y_batch:
:param writer:
:return:
"""
feed_dict = {
fasttext.input_x: x_batch,
fasttext.input_y: y_batch,
}
step, loss, accuracy = sess.run(
[fasttext.global_step, fasttext.loss_val, fasttext.accuracy],
feed_dict=feed_dict
)
time_str = datetime.datetime.now().isoformat()
print("dev results:{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
# generate batches
batches = data_process.batch_iter(list(zip(x_train, y_train)), FLAGS.batch_size, FLAGS.num_epochs)
# training loop
for batch in batches:
x_batch, y_batch = zip(*batch)
train_step(x_batch, y_batch)
current_step = tf.train.global_step(sess, fasttext.global_step)
if current_step % FLAGS.validate_every == 0:
print('\n Evaluation:')
dev_step(x_dev, y_dev)
print('')
path = saver.save(sess, checkpoint_prefix, global_step=current_step)
print('Save model checkpoint to {} \n'.format(path))
def main(argv=None):
x_train, y_train, vocab_processor, x_dev, y_dev = prepocess()
train(x_train, y_train, vocab_processor, x_dev, y_dev)
if __name__ == '__main__':
tf.app.run()对啦,我这里使用的数据集还是之前训练CNN时的那一份喔
以上~